 XGBoost详解
XGBoost详解





 本文深入讲解XGBoost算法原理,包括提升树构建过程、预测流程及特点,对比GBDT算法,探讨过拟合减少技术,提供调参技巧,并附带Python实现代码。
本文深入讲解XGBoost算法原理,包括提升树构建过程、预测流程及特点,对比GBDT算法,探讨过拟合减少技术,提供调参技巧,并附带Python实现代码。
前面讲到提升树算法是逐步添加基本CART树,后一个添加的树是基于已有组合模型预测结果残差来构建的。相比于以往的CART树最根本的差别就是拥有多颗树进行综合预测,每棵树的预测结果仅仅是最终结果的累加量。
GB(梯度提升)算法就是基于提升算法,用目标函数的梯度作为下一轮的训练目标,这样适合多种采用不同损失函数的情况,而不仅仅局限于平方误差损失函数(梯度即为残差)。
GBDT即采用决策树(通常为CART回归树)作为基本分类器的GB算法。
GBDT算法是一种加法模型,即逐步添加树以使得目标函数(或称代价函数,即损失函数之和)值最大程度减小。此时的目标函数没有正则化项,仅仅是损失函数(通常是平方损失函数)值之和,这样容易造成过拟合,因为对于回归树一直细分下去损失函数一直减小,树的深度却越来越大。
XGBoost算法在GBDT算法的基础上给代价函数加一个正则化项(XGBoost又被称为正则化的GB),并且对目标函数进行二阶泰勒近似。然后,采用精确或近似方法贪心搜索出得分最高的切分点(维度+值),进行下一步切分并扩展叶节点。这样做,一方面保证最小化损失函数的过程中,树结构不会过于复杂而产生过拟合,另一方面加快计算速度。
几个符号的意义
n
n
n:样本的个数
m
m
m:特征的个数
i
i
i:样本索引
X
i
X_i
Xi:单个样本输入
j
j
j:基本树上叶节点索引
I
j
I_j
Ij:叶节点拥有的样本集合
l
l
l:损失函数,参数
y
i
y_i
yi是实际值(常量)
L
\mathcal{L}
L:目标函数(代价函数),其中
Ω
\Omega
Ω是正则化项
q
q
q:树结构,即样本到叶节点的映射
f
t
f_t
ft:新加入模型中的基本树,下标
t
t
t表示第
t
t
t次迭代
T
T
T:叶节点个数
g
i
g_i
gi:泰勒展开一阶导数,即损失函数对已有加法模型预测值
y
t
−
1
y_{t-1}
yt−1处的导数
h
i
h_i
hi:泰勒展开二阶导数
w
i
w_i
wi:新添加基本树在叶节点
i
i
i上的预测输出值
推导过程
第t次迭代时总的目标函数(包含常数项)如下:
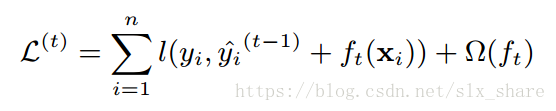
式中,
y
i
^
t
−
1
\hat{y_i}^{t-1}
yi^t−1为当前加法模型的预测值,为自变量,
f
t
(
X
i
)
f_t(X_i)
ft(Xi)为新添加基本树预测的值,相当于损失函数自变量增量。
对损失函数进行二阶泰勒展开如下:
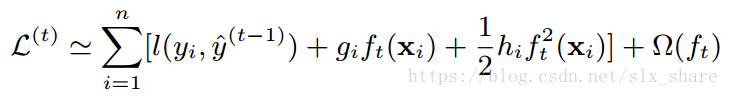
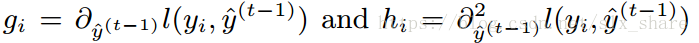
由于损失函数中
l
(
y
i
,
y
i
^
t
−
1
)
l(y_i,\hat{y_i}^{t-1})
l(yi,yi^t−1)为常量,可将其去除,后续仅仅考虑新添加的基本树是否合理即可,得到第t次迭代添加的基本树对最终目标函数的贡献(前一部分为负,使预测误差减小;后一部分为正,使得树的复杂度增加):
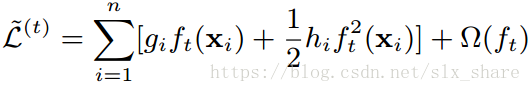
再代入正则化项得

上文公式中叶节点的权重
w
j
w_j
wj即该叶节点的输出,目标函数中
1
2
(
∑
i
∈
I
j
h
i
+
λ
)
w
j
2
+
(
∑
i
∈
I
j
g
i
)
w
j
\frac{1}{2}(\sum_{i\in I_j}{h_i+\lambda})w_j^2+(\sum_{i\in I_j}{g_i})w_j
21(∑i∈Ijhi+λ)wj2+(∑i∈Ijgi)wj是一个二次函数,取得最小值时,
w
j
=
−
∑
i
∈
I
j
g
i
∑
i
∈
I
j
h
i
+
λ
w_j=-\frac{\sum_{i\in I_j}{g_i}}{\sum_{i\in I_j}{h_i+\lambda}}
wj=−∑i∈Ijhi+λ∑i∈Ijgi
提升树的构建过程
上文推导出构建单棵基本树的标准,即使得
L
^
(
t
)
(
q
)
\hat{\mathcal{L}}^{(t)}(q)
L^(t)(q)最小的树结构 q 就是最优的基本树结构。基于这个标准,接下来需要通过逐步切分叶节点来扩展树。搜索切分点的方法可以分为精确搜索以及近似搜索。精确搜索充分考虑每个切分点,而近似搜索基于某些技巧,仅仅考虑部分切分点。
基本树的构建:贪心算法从根节点开始逐步添加分枝,针对一个叶节点,可以将其视为新的根节点进行分枝。分枝前后代价函数值之差就是该切分点得分(即切分后该基本树的目标函数值减小更多)。显然要寻找得分最大的切分点。
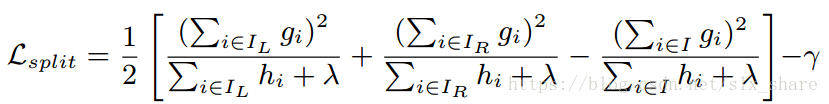
预测
前面已经说完树的构建问题,即训练的过程,得到了一系列树,且每棵树的所有叶节点都有相应的权重 w j w_j wj。预测过程中,当某个样本从树根经过层层if-then判断到达叶节点时,该叶节点的权重也就是相应的输出值。对于回归问题,每棵树的输出权重之和即为预测值,对于分类问题,二分类用logistic转化为属于正类的概率值(权重为负意味着在该棵树中该节点输出负类),多分类用SoftMax转化为每个类的概率值即可。
XGBoost的特点
Boosting算法可以分两个步骤进行。第一,基于上一轮模型的预测结果(如提升树算法选用预测残差)构建基本树;第二,将新基本树加入加法模型中。XGBoost相比GBDT方法的改进有如下三点:
- XGBoost不仅采用梯度,还采用目标函数的二阶导数来构建下一轮的学习目标
- XGBoost解决新基本树的构建问题时不同于以往的平方误差最小原则,而是使带有正则化项的目标函数下降最大为原则确定切分点
- XGBoost确定叶节点输出值不再采用取叶节点包含样本均值的方式,而是计算出每个叶节点最优权重 w j w_j wj
其他减少过拟合技术
Shrinkage(缩减): Shrinkage类似于学习率,即对每棵树的学习残差目标进行打折,从而降低当前树的影响程度。例如,第t次迭代的残差为
Δ
\Delta
Δ,缩减后为
η
Δ
\eta\Delta
ηΔ。
Feature Subsampling: 最先应用在随机森林中,即随机从所有特征中选取几个特征。
调参技巧
Gradient Boosting的调参
Tree-Specific Parameters
min_samples_split:对一个节点劈裂的条件之一就是该节点包含样本数大于min_samples_split。该值过高则可能过拟合,过小则欠拟合。
min_samples_leaf:叶节点包含的最少样本数。参数目的同min_samples_split。通常训练集中类不均衡时,该值需要设置小点,以防止小类被大类覆盖。
min_weight_fraction_leaf:同min_samples_leaf,只不过改成叶节点包含样本数量占总样本的比例下限。两者仅设其一。
max_depth: 树的最大深度,不容易调整,通常要采用CV(cross validate)方式。
max_leaf_nodes: 叶节点最大数量。作用同最大深度。两者仅设其一。
max_features: 寻找最优切分点时,考虑的最大特征的个数。随机选取。经验规则是设为总特征数量的开方,但在调参过程中考虑总数的30%-40%范围。该超参设置过高可能导致过拟合。
Boosting Parameters
learning_rate:确定了每棵基本树的输出结果在最终结果中的影响权重。通常较小的值使得模型鲁棒性更好,但需要更多的基本树,导致计算量较大。
n_estimators:基本基本树的个数。
subsample:从总的训练数据集中挑选样本的比例,以构建某个基本树的专有的训练数据集。通常设置为0.8。
Miscellaneous Parameters
loss: 损失函数。通常默认的效果不错。
init: 将已有的决策树设为基本树。
warm_start:设置为True则表示可以借用前面已经训练好的基本树训练接下来添加的基本树。合理设置可以加快训练速度。
调参过程
参考资料2中,Aarshay分享了他的调参经验,核心的思想是先调节影响最大的参数,再调节次要的参数。
- 设置较大的learning_rate以及相应的最优n_estimator
- 调节Tree-Specific Parameters
- 调节max_depth以及min_samples_split
- 调节min_samples_leaf
- 调节max_features
- 降低learning_rate,并相应地增加n_estimator
XGBoost的调参
general parameters
使用何种基本模型。通常是决策树或线性模型。
booster parameters
基本树必需的超参数。
gamma: 正则化项T前系数。
reg_lambda: L2正则化项前系数。
reg_alpha:L1正则化项前系数。
min_child_weight :节点包含样本的权重之和的下限。即如果某个节点所有样本的权重之和低于该值,则不劈裂。其作用类似于GB的min_samples_leaf。
colsample_bytree:构建某棵基本树时,从所有特征中随机抽取特征数量比例。
colsample_bylevel: 选择最优切分点时,考虑的特征数量所占比例。其作用类似于GB中的max_features。
其他参数参考GB。
task parameters
学习过程必须的超参数。目标函数形式、模型评价标准等。
调参过程
参考GB的调参过程。对于XGBoost, max_depth、min_child_weight以及gamma是影响基本树预测准确率最为重要的三个因素。
代码
以下用Python实现简单的XGBoost,损失函数为平方误差损失函数,采用精确搜索切分点。
# 实现XGBoost回归, 以MSE损失函数为例
import numpy as np
class Node:
def __init__(self, sp=None, left=None, right=None, w=None):
self.sp = sp # 非叶节点的切分,特征以及对应的特征下的值组成的元组
self.left = left
self.right = right
self.w = w # 叶节点权重,也即叶节点输出值
def isLeaf(self):
return self.w
class Tree:
def __init__(self, _gamma, _lambda, max_depth):
self._gamma = _gamma # 正则化项中T前面的系数
self._lambda = _lambda # 正则化项w前面的系数
self.max_depth = max_depth
self.root = None
def _candSplits(self, X_data):
# 计算候选切分点
splits = []
for fea in range(X_data.shape[1]):
for val in X_data[fea]:
splits.append((fea, val))
return splits
def split(self, X_data, sp):
# 劈裂数据集,返回左右子数据集索引
lind = np.where(X_data[:, sp[0]] <= sp[1])[0]
rind = list(set(range(X_data.shape[0])) - set(lind))
return lind, rind
def calWeight(self, garr, harr):
# 计算叶节点权重,也即位于该节点上的样本预测值
return - sum(garr) / (sum(harr) + self._lambda)
def calObj(self, garr, harr):
# 计算某个叶节点的目标(损失)函数值
return (-1.0 / 2) * sum(garr) ** 2 / (sum(harr) + self._lambda) + self._gamma
def getBestSplit(self, X_data, garr, harr, splits):
# 搜索最优切分点
if not splits:
return None
else:
bestSplit = None
maxScore = -float('inf')
score_pre = self.calObj(garr, harr)
subinds = None
for sp in splits:
lind, rind = self.split(X_data, sp)
if len(rind) < 2 or len(lind) < 2:
continue
gl = garr[lind]
gr = garr[rind]
hl = harr[lind]
hr = harr[rind]
score = score_pre - self.calObj(gl, hl) - self.calObj(gr, hr) # 切分后目标函数值下降量
if score > maxScore:
maxScore = score
bestSplit = sp
subinds = (lind, rind)
if maxScore < 0: # pre-stopping
return None
else:
return bestSplit, subinds
def buildTree(self, X_data, garr, harr, splits, depth):
# 递归构建树
res = self.getBestSplit(X_data, garr, harr, splits)
depth += 1
if not res or depth >= self.max_depth:
return Node(w=self.calWeight(garr, harr))
bestSplit, subinds = res
splits.remove(bestSplit)
left = self.buildTree(X_data[subinds[0]], garr[subinds[0]], harr[subinds[0]], splits, depth)
right = self.buildTree(X_data[subinds[1]], garr[subinds[1]], harr[subinds[1]], splits, depth)
return Node(sp=bestSplit, right=right, left=left)
def fit(self, X_data, garr, harr):
splits = self._candSplits(X_data)
self.root = self.buildTree(X_data, garr, harr, splits, 0)
def predict(self, x):
def helper(currentNode):
if currentNode.isLeaf():
return currentNode.w
fea, val = currentNode.sp
if x[fea] <= val:
return helper(currentNode.left)
else:
return helper(currentNode.right)
return helper(self.root)
def _display(self):
def helper(currentNode):
if currentNode.isLeaf():
print(currentNode.w)
else:
print(currentNode.sp)
if currentNode.left:
helper(currentNode.left)
if currentNode.right:
helper(currentNode.right)
helper(self.root)
class Forest:
def __init__(self, n_iter, _gamma, _lambda, max_depth, eta=1.0):
self.n_iter = n_iter # 迭代次数,即基本树的个数
self._gamma = _gamma
self._lambda = _lambda
self.max_depth = max_depth # 单颗基本树最大深度
self.eta = eta # 收缩系数, 默认1.0,即不收缩
self.trees = []
def calGrad(self, y_pred, y_data):
# 计算一阶导数
return 2 * (y_pred - y_data)
def calHess(self, y_pred, y_data):
# 计算二阶导数
return 2 * np.ones_like(y_data)
def fit(self, X_data, y_data):
step = 0
while step < self.n_iter:
tree = Tree(self._gamma, self._lambda, self.max_depth)
y_pred = self.predict(X_data)
garr, harr = self.calGrad(y_pred, y_data), self.calHess(y_pred, y_data)
tree.fit(X_data, garr, harr)
self.trees.append(tree)
step += 1
def predict(self, X_data):
if self.trees:
y_pred = []
for x in X_data:
y_pred.append(self.eta * sum([tree.predict(x) for tree in self.trees]))
return np.array(y_pred)
else:
return np.zeros(X_data.shape[0])
if __name__ == '__main__':
from sklearn.datasets import load_boston
from sklearn.model_selection import train_test_split
from sklearn.metrics import mean_absolute_error
import matplotlib.pyplot as plt
boston = load_boston()
y = boston['target']
X = boston['data']
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.33, random_state=42)
f = Forest(50, 0, 1.0, 4, eta=0.8)
f.fit(X_train, y_train)
y_pred = f.predict(X_test)
print(mean_absolute_error(y_test, y_pred))
plt.scatter(np.arange(y_pred.shape[0]), y_test - y_pred)
plt.show()参考资料
- https://xgboost.readthedocs.io/en/latest/index.html
- https://www.analyticsvidhya.com/blog/2016/02/complete-guide-parameter-tuning-gradient-boosting-gbm-python/
- https://www.analyticsvidhya.com/blog/2016/03/complete-guide-parameter-tuning-xgboost-with-codes-python/
- http://zhanpengfang.github.io/418home.html
注:代码未经严格测试,如有不当之处,请指正。
我的GitHub

















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









