






 本文深入探讨MMU在操作系统中的核心作用,解释进程如何通过MMU映射虚拟内存到物理内存,以及缺页中断处理流程。MMU确保每个进程拥有独立的内存空间,通过页表和TLB加速地址转换。
本文深入探讨MMU在操作系统中的核心作用,解释进程如何通过MMU映射虚拟内存到物理内存,以及缺页中断处理流程。MMU确保每个进程拥有独立的内存空间,通过页表和TLB加速地址转换。
高级操作系统下MMU是必不可少的硬件外设,但大多数情况下,应用程序开发者并不会理会它的存在,只是知道MMU是用来映射物理内存地址使之成为虚拟内存地址并被user空间访问的。
没错,这确实是MMU的主要功能,但作为开源开发者,我们不仅要知其然更要知其所以然。因此我在此将我对MMU的理解与工作实质列出,供对MMU工作原理有兴趣的同学参考,也希望有牛人对我的文章进行指正与评论。
1,MMU之所以存在,是因为但凡进程,都需要让它认为自己是可以使用全部物理内存空间的。这是符合编程时候的情景的,因为每个进程都是被独立编写、编译的。处在进程编写者的角度,他是不会理会其他进程的运行状态与资源占用的。
2,vm_area_struct是一个重要的内存数据结构。进程空间在编译之后会产生堆、bss等数据内存区域。内核在进行进程加载的时候会为数据内存区域主动分配内存。而分配内存的的系统调用最终生成的存储结构就是vm_area_struct。
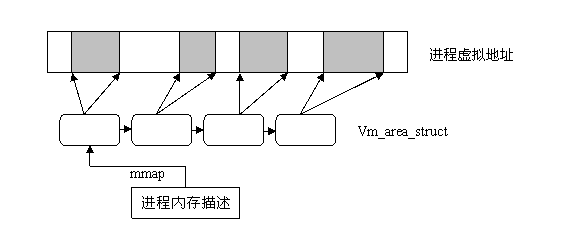
3,当进程需要内存时,从内核获得的仅仅是虚拟的内存区域,而不是实际的物理地址,进程并没有获得物理内存(物理页面——页的概念请大家参考硬件基础一章),获得的仅仅是对一个新的线性地址区间的使用权。实际的物理内存只有当进程真的去访问新获取的虚拟地址时,才会由“请求页机制”产生“缺页”异常,从而进入分配实际页面的例程。
4,虽然应用程序操作的对象是映射到物理内存之上的虚拟内存,但是处理器直接操作的却是物理内存。所以当应用程序访问一个虚拟地址时,首先必须将虚拟地址转化成物理地址,然后处理器才能解析地址访问请求。地址的转换工作需要通过查询页表才能完成,概括地讲,地址转换需要将虚拟地址分段,使每段虚地址都作为一个索引指向页表,而页表项则指向下一级别的页表或者指向最终的物理页面。
每个进程都有自己的页表。进程描述符的pgd域指向的就是进程的页全局目录。
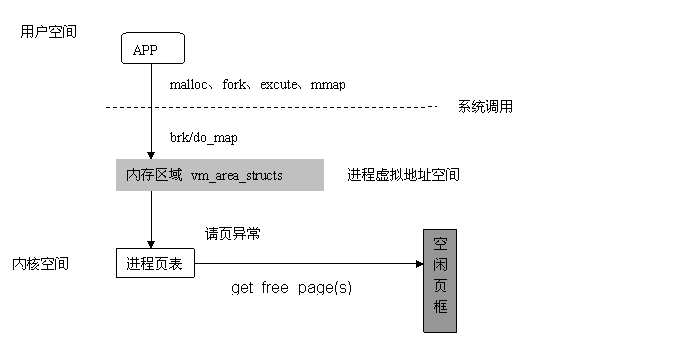
5,用户进程在运行时,会使用malloc等函数进行动态调用。则会进行下图的示意操作。
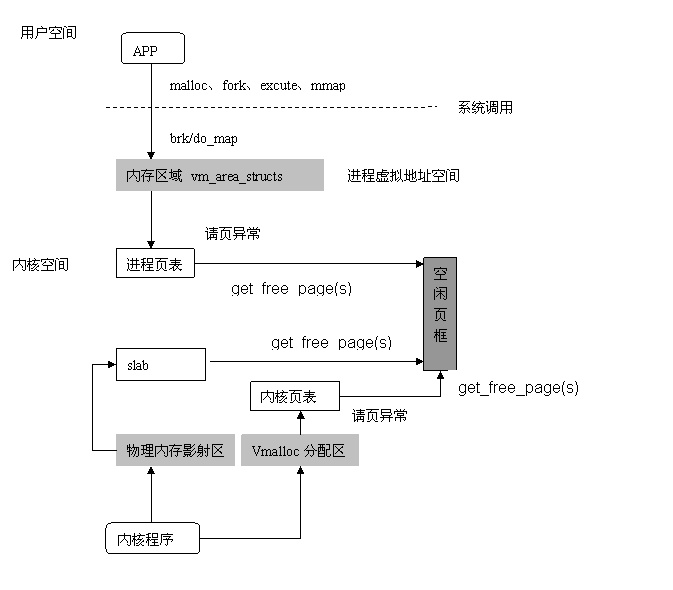
6,内核程序在使用Kmalloc\Vmalloc使,也会触发缺页异常,进而产生页面申请。
7, 缺页中断流程图
这里的流程是在中断处理完成后重新启动命令的,符合缺页中断的处理流程。私以为在配置快表的请求页式存储管理中缺页中断后的快表修改也应由中断处理完成
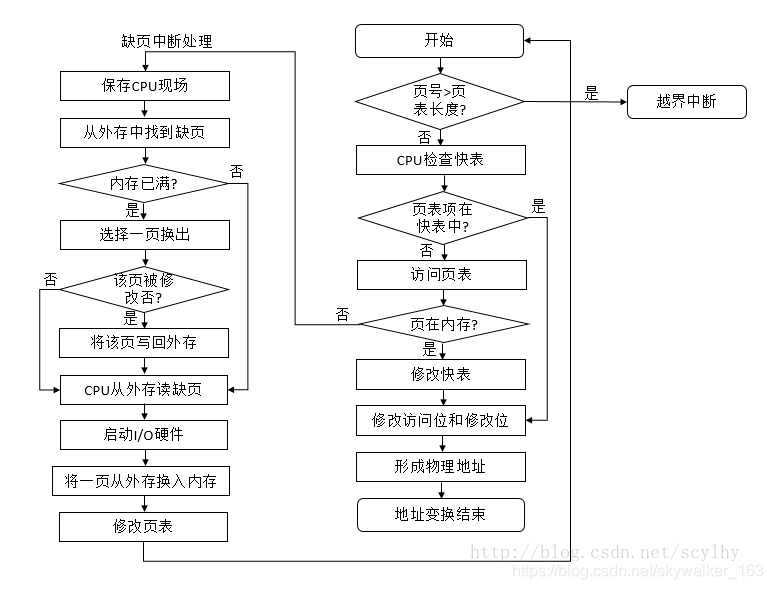
缺页中断
缺页中断不同与一般中断,表现在:
1.缺页中断在指令执行期间触发中断,中断处理完成后,将重启该命令。
2.缺页中断将会发生多次,这与机器的指令和数据分布有关,如跨页指令和数据。
地址转化
1.当发生缺页中断时,系统进行中断处理(有空闲块,调入页面;无空闲根据置换算法,替换一个出去)。
至于快表(TLB)的更新,一般认为也由os在中断处理中完成。09年408OS那道题目就假设中断处理包括TCB也更新.
2.完成中断处理后,重启该命令。
3.该命令让将进行地址转换,先检索TLB,命中,获得物理块,直接运算得出物理地址。
8,MMU实际的底层运行原理
如果CPU是工作在虚拟地址模式下,它实际上是没有办法直接访问到物理地址的。在这种情况下,也即意味着CPU不能够直接查询页表。这时候,必须要有MMU来执行这种页表查询操作。MMU也有自己的chahe,称之为TLB(Translation Look-aside Buffer),用来缓存PTE。
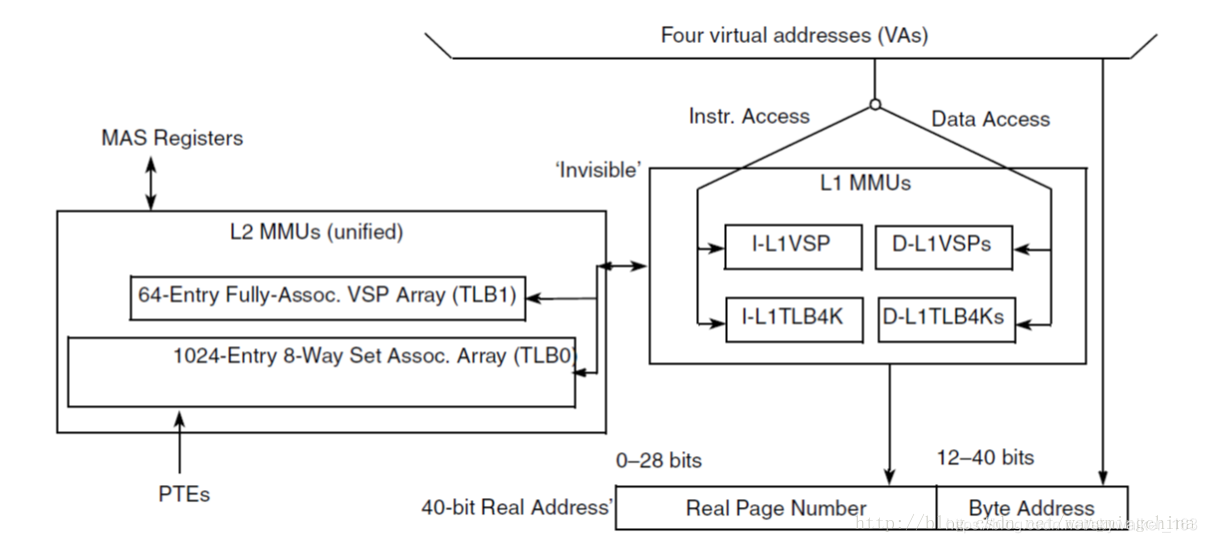
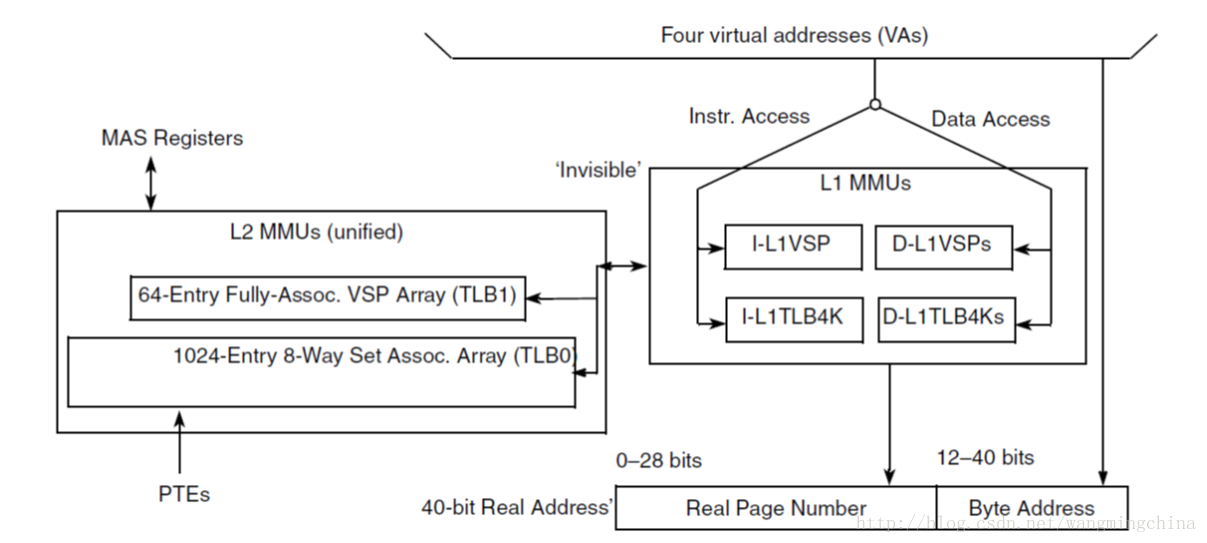
图: e6500 CPU的MMU大致结构
页表是按需创建的,就是说在物理页面分配之后,我们才会创建相应的页表项。这里说下页表项和页表的区别。我这里说的页表是指PGD表,PUD表,PMD表,PTE表,在上一节,我画了一张图表示它们。它们包含了各自的页表项,如PGD,PUD,PMD和PTE。通过页表分级的方法,实现页表项的局部加载。加快查找速度。

在此之种种PXX,PTE是最后直接和MMU相关的结构页表的创建和页面映射的建立(设置PTE)是一个整体。下面是它们的一般流程:

MMU通过将PTE缓存到TLB中,以加速查找过程。类似于CPU cache,MMU也具有L1和L2两级TLB。L1是L2的缓存,L2是L1的后备存储。当在L1中没有查询到相应的PTE时,会在L2中进行再一次查找,如果找到了,则会更新到L1中。同时指令TLB和数据TLB在L1中是分开独立的。
TLB(Translation Look-aside Buffer)就是MMU的缓存,它和CPU缓存具有同样的结构。我们只需要知道在TLB中,数据都是按行存放的,一行称之为一个entry。一个entry包含了若干bit位,下面是它的bit位含义描述:
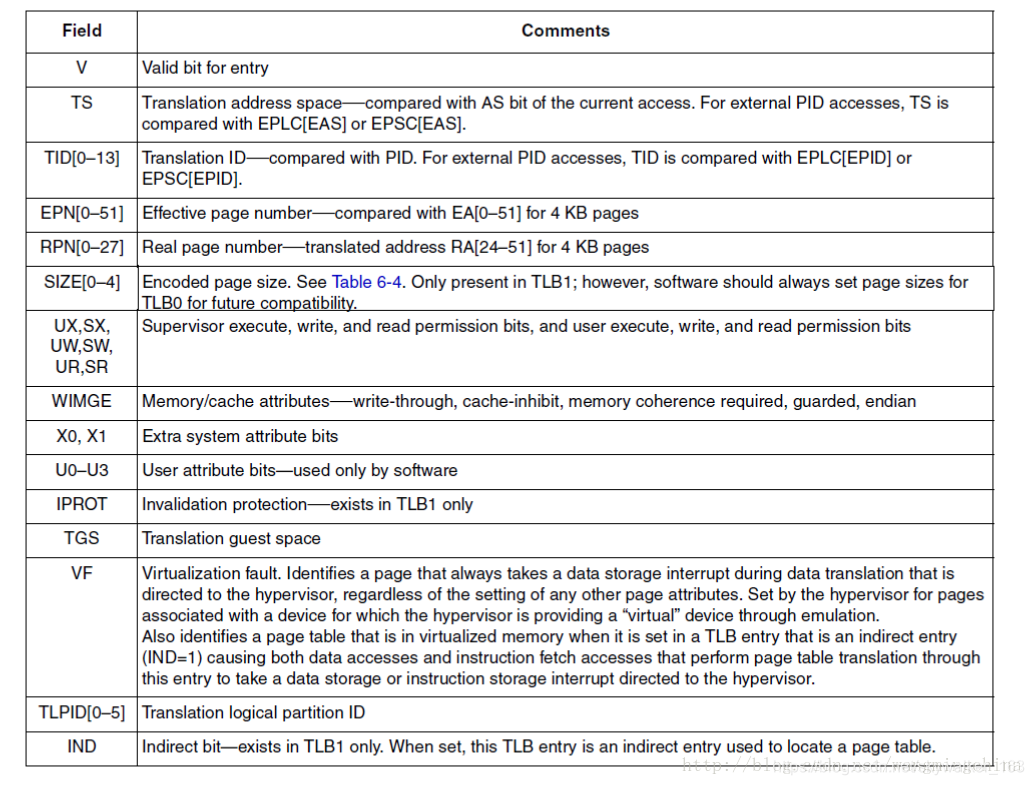
其中TID。这个比较重要,对应于虚拟地址中的PID。前面我说了,L2 TLB和L1的指令TLB是两个CPU硬件线程共享的。这两个CPU硬件线程可以并行的执行两个软件线程,如果这两个软件线程不在同一个进程空间,那么在TLB中,我们怎么区分这两个进程地址空间呢?答案就是,在虚拟地址中,CPU会设置一个当前进程地址空间的PID。通过比较PID与TLB entry中的TID,我们能够区分这两个不同的进程地址空间。
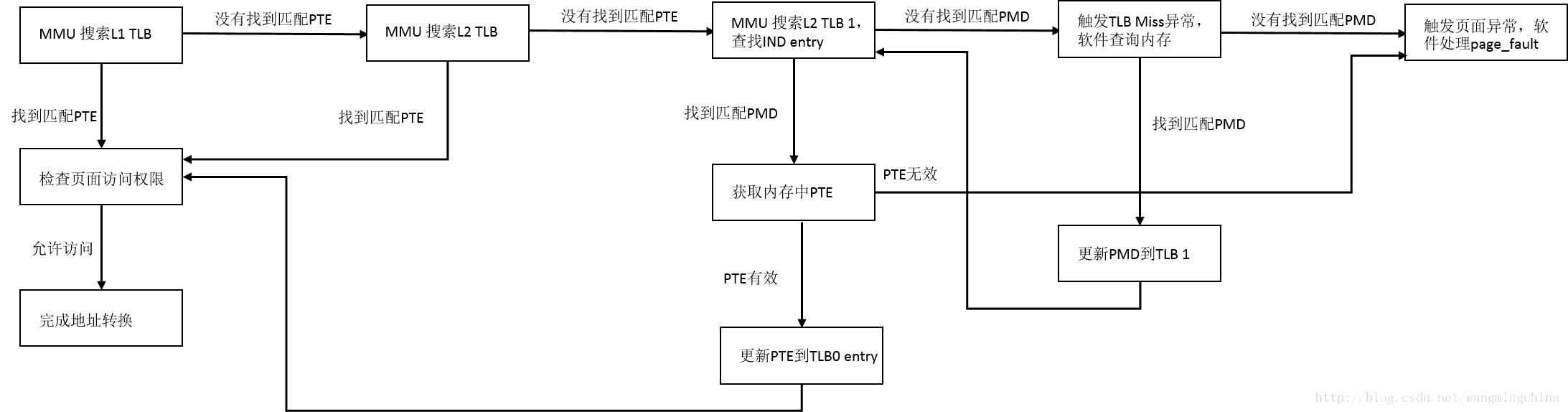
说句题外话,因为新声明的内存,第一次访问时才出现page_fault,因此,第一次访问都是比较慢的。

















 7708
7708

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









