





中文分词:将一段文本拆分为一系列单词的过程。中文分词分为基于词典规则与基于机器学习这两大派别。
在基于词典的中文分词中,词典中的字符串就是词。
HanLP中的词典格式是一种以空格分隔的表格形式,易地裂是单词本身,之后两列分别是词性和相应的词频。
词典确定后,句子中可能含有很多词典中的词语,他们可能相互重叠,到底输出哪一个有规则决定。常用的规则有正向最长匹配,逆向最长匹配和双向最长匹配算法。他们都是完全切分过程。
完全切分:找出一段稳重的所有单词,并不是标准意义上的分词。
不考虑效率的情况下,朴素的完全切分其实非常简单。只要遍历文本中连续序列查询该序列是否在词典中即可。
完全切分
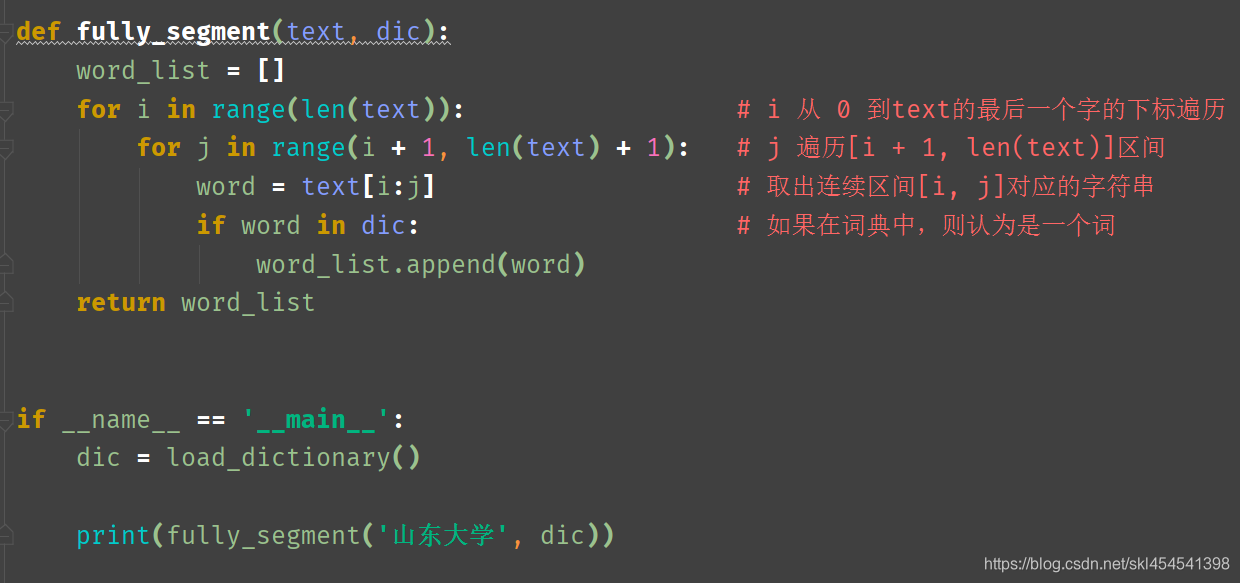 由于词库中含有danzi单字,所以结果中也会出现单字
由于词库中含有danzi单字,所以结果中也会出现单字
正向最长匹配
上面的输出并不是中文分词,我们更需要那种有意义的词语序列,而不是所有出现在词典中的单词所构成的链表。比如我们希望“山东大学”成为一整个词。为了达到这个目的,我们需要完善一下我们的规则。考虑到越长的单词表达的意义越丰富,于是我们定义单词越长优先级越高。具体来说,就是在以某个下标为起点递增查词的过程中,有限输出更长的单词,这种规则被称为最长匹配算法。改下表的扫描顺序从前往后,则成为正向最长匹配,反之则称为逆向最长匹配
正向最长匹配算法如下
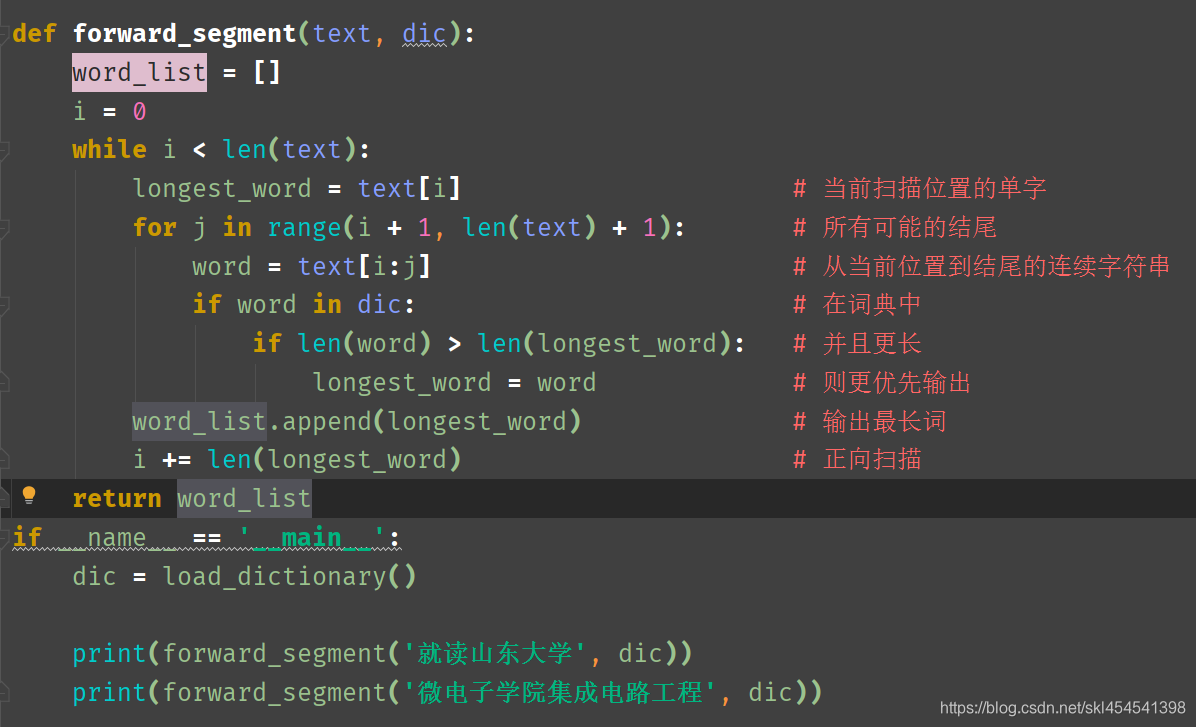
不过有些句子的划分还是与理想有偏差
比如
我们期望的是微电子学院 集成电路工程
于是有些人就想到可否用逆向匹配解决这个问题呢
逆向最长匹配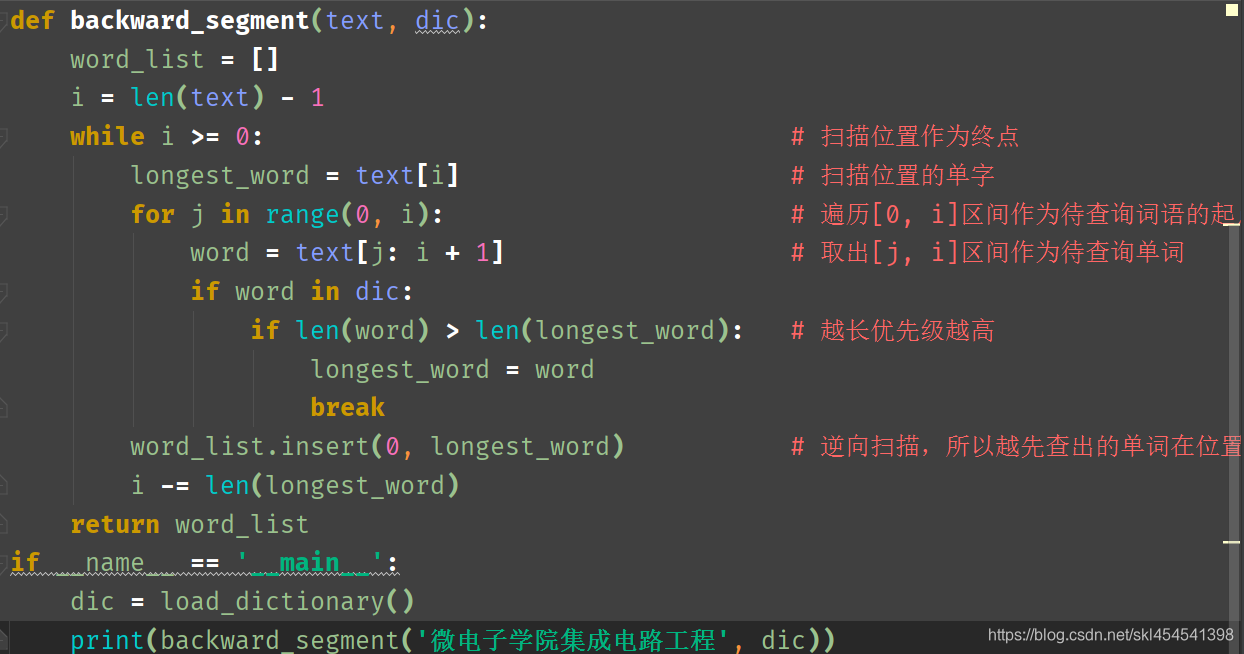
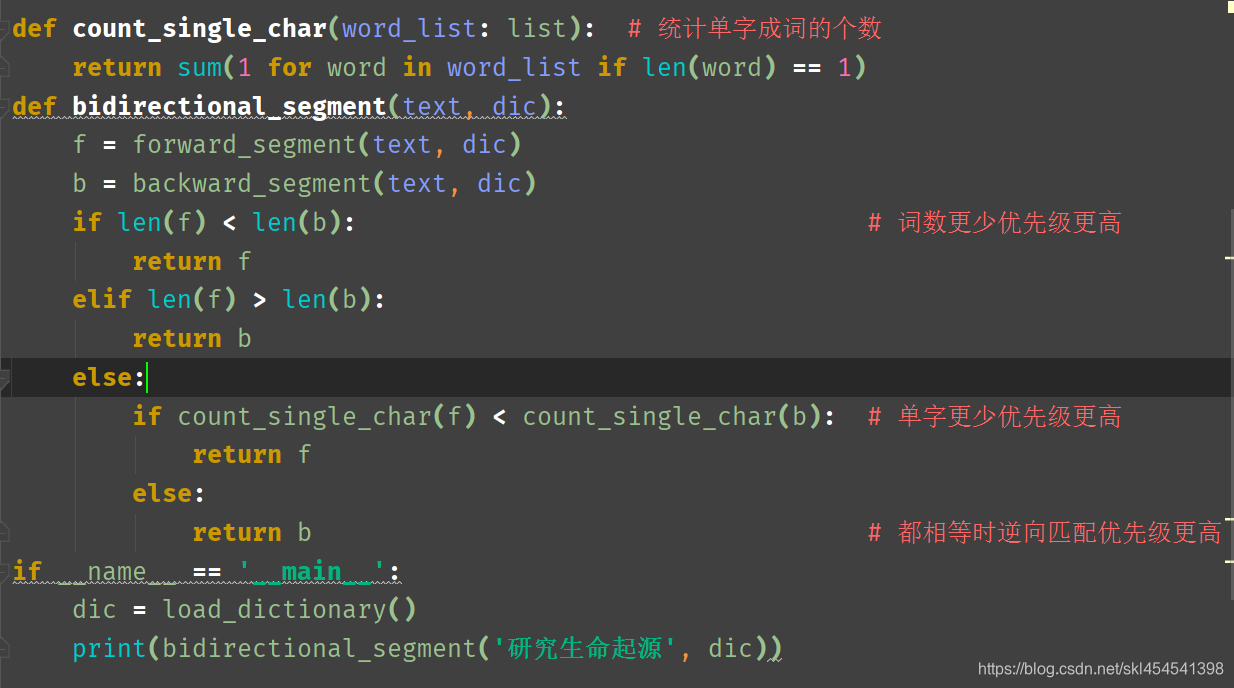
双向最长匹配:
融合两种匹配方法的复杂规则集,流程如下
(1)同时执行正向和逆向最长匹配,若两者的词数不同,则返回词数更少的哪一个
(2)否则,返回两者中单字更少的那个,当单字也相同时,优先返回逆向最长匹配的结果
速度测评

运行结果:
双数组字典树:就是一种状态转移复杂度为常数的数据结构
它由base和check两个数组构成,简称双数组
当状态b接收字符c转移状态p时,双数组满足:
p = base[b]+c
check[p] = base【b】

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









