






目录
TensorFlow 策略梯度方法:深度强化学习中的关键技术
在强化学习(Reinforcement Learning,RL)中,策略梯度(Policy Gradient)方法是一种非常重要的算法,广泛应用于解决高维、连续动作空间问题。与值函数方法不同,策略梯度方法直接优化策略,使得在给定状态下的行为(即动作)能够最大化累积奖励。这篇博客将深入探讨策略梯度方法的原理、实现和应用,重点介绍如何使用TensorFlow实现策略梯度算法。
1. 策略梯度方法概述
1.1 策略与值函数
在强化学习中,代理(Agent)通过与环境的交互来学习如何最大化累积奖励。强化学习问题通常可以表示为马尔可夫决策过程(MDP)。每个状态 下,代理根据策略
选择动作
,并根据环境反馈获得奖励
。
- 值函数(Value Function):估计在某一状态下,代理能够获得的期望奖励。
- 策略(Policy):策略是从状态到动作的映射,决定了代理如何选择动作。策略可以是确定性的(如
)或随机的(如
)。
1.2 策略梯度方法简介
策略梯度方法直接优化策略函数 ,目标是通过调整策略,使得累积奖励最大化。策略梯度算法的核心是通过梯度上升方法,估计并更新策略参数,从而使得代理在每个状态下采取的动作尽可能地优。
策略梯度的更新公式如下:
![]()
其中, 是策略的参数,
是学习率,
是目标函数,表示在给定策略下的累积奖励期望。
2. 策略梯度的推导
2.1 目标函数
我们希望最大化的目标是预期的回报(或期望奖励)。策略梯度的目标函数定义为:
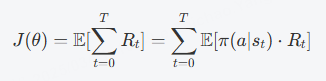
其中, 是从时间步
开始的累积奖励。
2.2 计算梯度
通过对目标函数 进行梯度上升,得到策略梯度的公式。使用 策略梯度定理,我们可以推导出:
![]()
这个公式表明,我们可以通过计算策略的梯度,并乘以奖励信号来更新策略参数。
3. 策略梯度算法的实现
在实际应用中,策略梯度方法的实现通常使用蒙特卡洛方法或时序差分学习(TD学习)来估计回报。下面,我们将使用TensorFlow实现一个简单的策略梯度算法,基于CartPole环境。
3.1 CartPole 环境介绍
CartPole是一个经典的强化学习环境,目标是使得一个杆子保持直立。代理通过控制滑块的左右运动,调整杆子的角度,尽量使杆子不倒。每个时间步,代理的目标是通过选择合适的动作(左或右),最大化回报。
3.2 使用TensorFlow实现策略梯度
首先,我们使用OpenAI Gym创建环境,并基于TensorFlow实现策略梯度算法。
import gym
import tensorflow as tf
import numpy as np
# 创建环境
env = gym.make('CartPole-v1')
# 网络结构
class PolicyNetwork(tf.keras.Model):
def __init__(self):
super(PolicyNetwork, self).__init__()
self.dense1 = tf.keras.layers.Dense(24, activation='relu')
self.dense2 = tf.keras.layers.Dense(24, activation='relu')
self.logits = tf.keras.layers.Dense(2, activation=None) # 输出动作的概率
def call(self, state):
x = self.dense1(state)
x = self.dense2(x)
return self.logits(x)
# 策略梯度训练
def train_step(states, actions, rewards, model, optimizer):
with tf.GradientTape() as tape:
logits = model(states)
# 计算每个动作的概率
neg_log_prob = tf.nn.sparse_softmax_cross_entropy_with_logits(logits=logits, labels=actions)
# 计算回报加权的策略梯度
loss = tf.reduce_mean(neg_log_prob * rewards)
grads = tape.gradient(loss, model.trainable_variables)
optimizer.apply_gradients(zip(grads, model.trainable_variables))
# 训练过程
def train():
model = PolicyNetwork()
optimizer = tf.keras.optimizers.Adam(learning_rate=0.01)
for episode in range(1000):
state = env.reset()
episode_reward = 0
states, actions, rewards = [], [], []
for t in range(200):
state = np.expand_dims(state, axis=0) # 处理输入格式
state = tf.convert_to_tensor(state, dtype=tf.float32)
logits = model(state) # 获取策略输出
action_probs = tf.nn.softmax(logits) # 计算动作概率
action = np.random.choice(2, p=action_probs.numpy().flatten()) # 根据概率选择动作
next_state, reward, done, _ = env.step(action)
states.append(state)
actions.append(action)
rewards.append(reward)
episode_reward += reward
state = next_state
if done:
break
# 计算回报的折扣值
discounted_rewards = np.array(rewards)
discounted_rewards = (discounted_rewards - np.mean(discounted_rewards)) / (np.std(discounted_rewards) + 1e-10)
# 执行训练步骤
train_step(np.array(states), np.array(actions), discounted_rewards, model, optimizer)
print(f"Episode {episode+1}: Total Reward = {episode_reward}")
# 开始训练
train()
3.3 代码解释
-
环境创建:使用
gym.make('CartPole-v1')创建一个CartPole环境,该环境有一个滑块可以左右移动,目的是保持一个杆子平衡。 -
策略网络:我们定义了一个简单的神经网络模型,包含两层全连接层,输出是一个二维的logits向量,表示两个动作(左或右)的未归一化的概率。
-
训练过程:每个episode结束后,我们计算所有时间步的奖励(
rewards),并使用标准化的奖励计算策略梯度更新参数。 -
优化:通过
Adam优化器对网络进行训练。损失函数是负对数概率与奖励的乘积,梯度下降的目标是最大化预期的回报。
4. 策略梯度方法的优势与挑战
4.1 优势
- 适用于高维动作空间:策略梯度方法不需要对每个动作进行离散化处理,因此在连续动作空间中表现优越。
- 不依赖于值函数:策略梯度方法直接优化策略,避免了值函数方法可能遇到的估计偏差。
4.2 挑战
- 高方差:策略梯度方法通常存在较大的方差,这可能导致训练过程不稳定。
- 样本效率低:需要大量的交互数据来估计梯度,因此计算开销较大。
5. 改进方法:基于优势的策略梯度(A2C)
为了减少方差并提高样本效率,许多改进方法如**优势 Actor-Critic(A2C)**方法被提出。A2C方法将策略梯度与值函数结合,使用值函数估计每个状态的预期回报,从而计算优势(advantage)。优势可以用来对奖励进行加权,减少方差,提高学习效率。
# A2C实现示例(简化版)
class ValueNetwork(tf.keras.Model):
def __init__(self):
super(ValueNetwork, self).__init__()
self.dense1 = tf.keras.layers.Dense(24, activation='relu')
self.dense2 = tf.keras.layers.Dense(24, activation='relu')
self.value = tf.keras.layers.Dense(1, activation=None)
def call(self, state):
x = self.dense1(state)
x = self.dense2(x)
return self.value(x)
# A2C的训练过程结合了策略网络和价值网络
6. 总结
本文介绍了策略梯度方法的基本原理,并通过TensorFlow实现了一个简单的强化学习示例。策略梯度方法直接优化策略,能够解决高维、连续动作空间的问题,适合复杂环境中的应用。然而,策略梯度方法也面临着高方差和样本效率低的问题。为了改善这些问题,基于优势的策略梯度方法(如A2C)为其提供了有效的改进。
通过本篇博客的学习,读者应能够理解策略梯度方法的基本思想,并能够使用TensorFlow实现简单的强化学习模型。
推荐阅读:
Q-learning和Deep Q Network (DQN) 深度解析-优快云博客


















 1044
1044

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











