







目录
Q-learning和Deep Q Network (DQN) 深度解析
Q-learning代码示例(基于Python和TensorFlow)
在强化学习领域,Q-learning和**Deep Q Network (DQN)**是两种非常重要且被广泛应用的算法。Q-learning是最经典的强化学习算法之一,而DQN则是其深度学习版本,解决了Q-learning在处理高维状态空间时的难题。本文将深入讲解Q-learning和DQN的原理,使用TensorFlow实现它们,并详细对比二者的优缺点,帮助读者全面了解这两种算法。
1. Q-learning概述
1.1 Q-learning的基本思想
Q-learning是一种基于值函数的强化学习算法。其核心思想是通过学习一个Q函数来表示在某一状态下采取某一动作所获得的最大期望回报。Q-learning的目标是找到最优策略,通过最大化每个状态的Q值来获得最优的行为策略。
Q函数定义:
Q函数是状态-动作价值函数,用于表示在某一状态下采取某一动作所获得的未来回报的期望值。它通过如下公式进行更新:
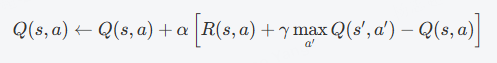
:当前状态s下,选择动作a的价值
:当前状态s下,选择动作a所获得的即时奖励
:折扣因子,决定了未来奖励的重要性
:学习率,决定了新信息的更新速度
:状态转移后得到的最大Q值
1.2 Q-learning算法步骤
Q-learning的学习过程可以分为以下几个步骤:
- 初始化Q表:为每一对状态-动作对初始化Q值,通常可以初始化为0。
- 在环境中进行探索:从初始状态出发,通过与环境交互来收集状态、动作、奖励的信息。
- 更新Q值:通过上述公式更新Q值。
- 选择动作:根据Q表选择最大Q值的动作进行执行。常用的选择策略有ε-贪婪策略(ε-greedy)。
Q-learning代码示例(基于Python和TensorFlow)
import numpy as np
import random
class QLearningAgent:
def __init__(self, n_actions, alpha=0.1, gamma=0.9, epsilon=0.1):
self.n_actions = n_actions # 动作的数量
self.alpha = alpha # 学习率
self.gamma = gamma # 折扣因子
self.epsilon = epsilon # 探索率
self.Q = np.zeros(n_actions) # 初始化Q表
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











