 TF-IDF技术在达观杯数据竞赛的应用
TF-IDF技术在达观杯数据竞赛的应用





 本文介绍了TF-IDF技术及其在信息检索和数据挖掘中的作用。通过scikit-learn的TfidfTransformer类,将单词频数向量矩阵转化为标准化权重矩阵,以处理文本数据。在达观杯数据竞赛中,使用train_set.csv数据集,文章在字和词级别上进行了脱敏处理,处理过程包括将字和词分开处理后再合并。
本文介绍了TF-IDF技术及其在信息检索和数据挖掘中的作用。通过scikit-learn的TfidfTransformer类,将单词频数向量矩阵转化为标准化权重矩阵,以处理文本数据。在达观杯数据竞赛中,使用train_set.csv数据集,文章在字和词级别上进行了脱敏处理,处理过程包括将字和词分开处理后再合并。
1、理解tf-idf
TF-IDF(term frequency–inverse document frequency)是一种用于信息检索与数据挖掘的常用加权技术。TF意思是词频(Term Frequency),IDF意思是逆文本频率指数(Inverse Document Frequency)。
scikt-learn类库的TfdfTransformer类可以通过将单词频数向量矩阵转换为一个标准化单词频数权重矩阵来缓和这个问题。默认情况下,TfdfTransformer类对真实频数做光滑化处理,并对其运用L2L^2L2范数。光滑化标准后的单词频数可以由如下公式给出:
分子表示单词在文档中出现的频数,分母是单词频数向量的L2L^2L2范数。除了对真实单词频数进行标准化以外,我们还可以通过计算单词频数的对数将频数缩放到一个有限的范围内来改善特征向量。单词频数的对数缩放值如下:
逆文档频率(IDF) 是一种衡量一个单词在语料库中是否稀有或者常见的方式,公式如下:
分子是语料库中的文档总数,分母是语料库中包含该单词的文档总数。scikt-learn类库提供了一个TfidfVectorizer转换器类,它封装了CountVectorizer类和TfidTransformer类。
接下来我们用代码来处理下,详细了解请参考scikit-learn机器学习第四章从文本中提取特征。
2、TfidfVectorizer类处理文本
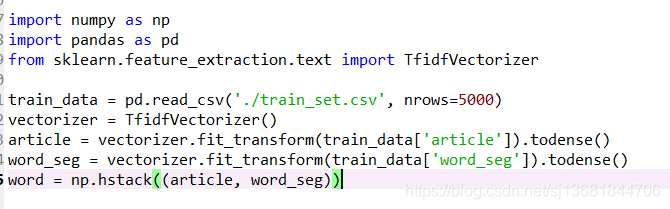
train_set.csv:此数据集用于训练模型,每一行对应一篇文章。文章分别在“字”和“词”的级别上做了脱敏处理。共有四列:
第一列是文章的索引(id),第二列是文章正文在“字”级别上的表示,即字符相隔正文(article);第三列是在“词”级别上的表示,即词语相隔正文(word_seg);第四列是这篇文章的标注(class)。
注:每一个数字对应一个“字”,或“词”,或“标点符号”。“字”的编号与“词”的编号是独立的!
因此此处的处理是单独把字和词分开处理,然后再合并。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









