








 本文介绍了MTCNN,其论文提出深度级联多任务框架和新的困难样本挖掘策略提升性能。整体结构上,对输入图片进行金字塔处理,经三个阶段处理:先通过浅层CNN得候选框,再用更复杂CNN删无人脸候选框,最后用更复杂CNN调整结果,输出人脸框和特征点位置。
本文介绍了MTCNN,其论文提出深度级联多任务框架和新的困难样本挖掘策略提升性能。整体结构上,对输入图片进行金字塔处理,经三个阶段处理:先通过浅层CNN得候选框,再用更复杂CNN删无人脸候选框,最后用更复杂CNN调整结果,输出人脸框和特征点位置。
MTCNN
论文全称:Joint Face Detection and Alignment using Multi-task Cascaded Convolutional Networks
论文下载链接:https://arxiv.org/abs/1604.02878v1
论文发表于16年4月
介绍
深度学习的发展使得人脸识别(face detection)和人脸对齐(face alignment)领域有了显著的进步。
论文提出了一个深度级联多任务框架(deep cascaded multi-task framework)和一个新的困难样本挖掘策略极大的提升了实际中的性能。
整体结构
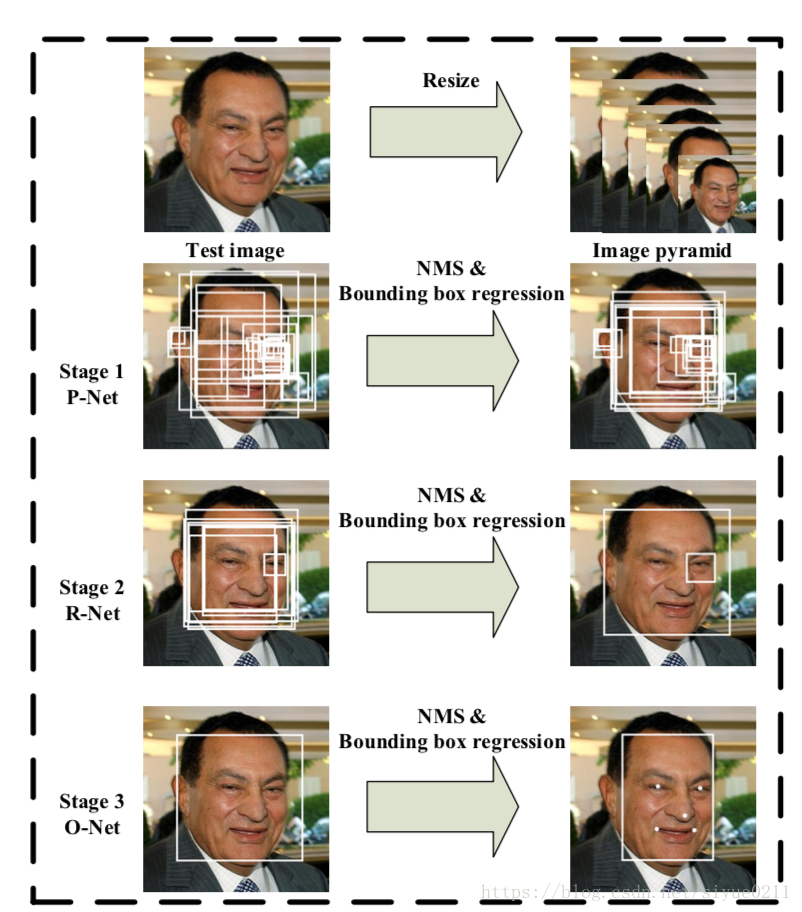
**输入:**对于输入的图片进行图片金字塔处理,最小的图片大小为12*12,最大的为图片本身大小。
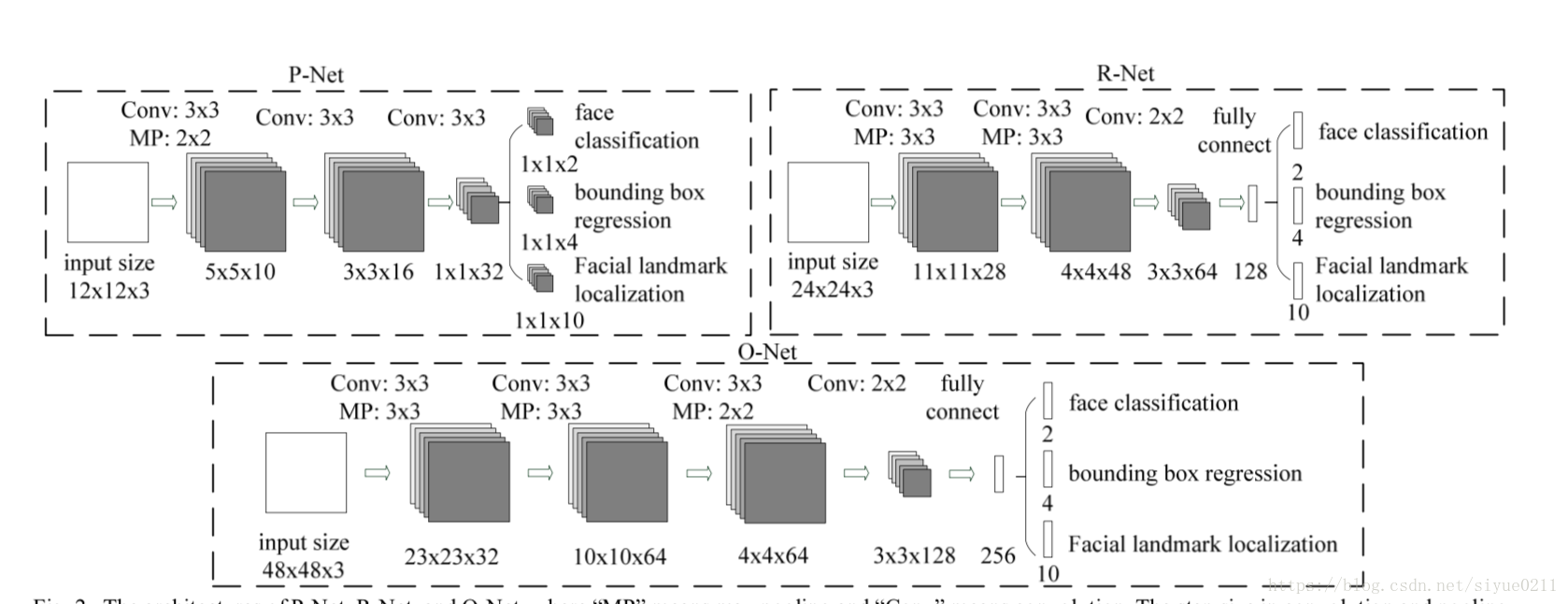
stage1:通过浅层CNN得到候选框
在训练的时候该网络的顶部有3条支路用来分别做人脸分类、人脸框的回归和人脸关键点定位;在测试的时候这一步的输出只有N个bounding box的4个坐标信息和score,当然这4个坐标信息已经用回归支路的输出进行修正了,score可以看做是分类的输出(是人脸的概率),具体可以看代码
stage2:通过更复杂的CNN删除无人脸的候选框
这一步的输入是前面P-Net生成的bounding box,每个bounding box的大小都是24*24,可以通过resize操作得到。同样在测试的时候这一步的输出只有M个bounding box的4个坐标信息和score,4个坐标信息也用回归支路的输出进行修正了
stage3:使用更加复杂的CNN调整结果,输出人脸框和五个特征点的位置
输入大小调整为48*48,输出包含P个bounding box的4个坐标信息、score和关键点信息。
参考
https://blog.youkuaiyun.com/u014380165/article/details/78906898

















 938
938

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









