







 本文探讨了大数据下的梯度下降算法,包括随机梯度下降和mini-batch梯度下降,强调了它们在处理大规模数据时的效率优势。同时介绍了在线学习和MapReduce在大数据处理中的应用,为大规模机器学习提供了有效工具。
本文探讨了大数据下的梯度下降算法,包括随机梯度下降和mini-batch梯度下降,强调了它们在处理大规模数据时的效率优势。同时介绍了在线学习和MapReduce在大数据处理中的应用,为大规模机器学习提供了有效工具。
1 大数据下的梯度下降
在接下来的几个视频里 ,我们会讲大规模的机器学习, 就是用来处理大数据的算法。 如果我们看近5到10年的机器学习的历史 ,现在的学习算法比5年前的好很多, 其中的原因之一就是我们现在拥有很多可以训练算法的数据 。
1.1 大数据
为什么我们喜欢用大的数据集呢?
我们已经知道 得到一个高效的机器学习系统的最好的方式之一是 用一个低偏差的学习算法 ,然后用很多数据来训练它.
当然 ,在我们训练一个上亿条数据的模型之前 ,我们还应该问自己: 为什么不用几千条数据呢 ?也许我们可以随机从上亿条的数据集里选个一千条的子集,然后用我们的算法计算。
通常的方法是画学习曲线 :
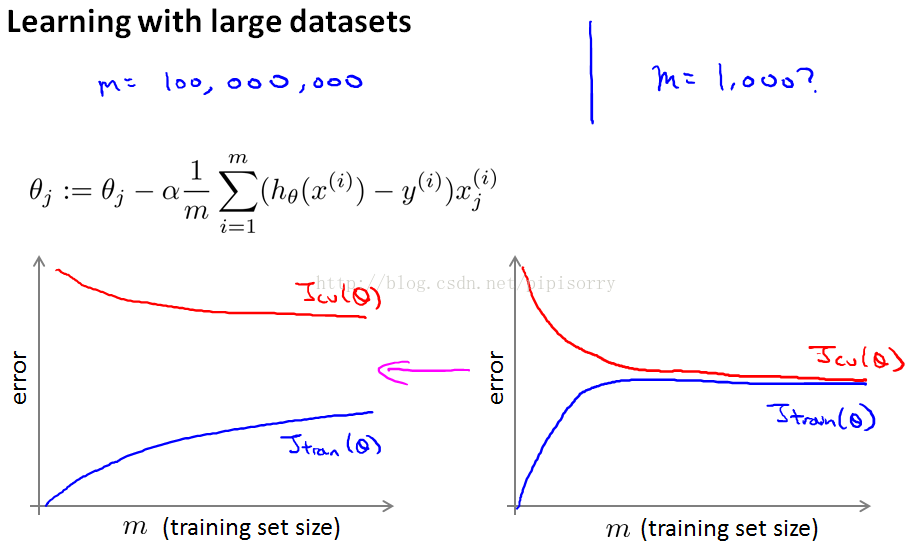
如果你要绘制学习曲线,并且如果你的训练目标看起来像是左边的,而你的交叉验证集目标,theta的Jcv,那么这看起来像是一个高方差学习算法,所以加入额外的训练样例来提高性能。
右边看起来像传统的高偏差学习算法,那么看起来不大可能增加到1亿将会更好,然后你会坚持n等于1000,而不是花费很多的精力弄清楚算法的规模如何。
正确的做法之一是增加额外的特性,或者为神经网络增加额外的隐藏单位等等,这样你就可以得到更接近于左边的情况,在这种情况下可能达到n 等于1000,这样就给了你更多的信心,试图添加基础设施(下部构造)来改变算法,使用更多的例子,可能实际上是一个很好的利用你的时间。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









