







 本文详细介绍了Hadoop2.8.5完全分布式集群的安装过程,以及Spark2.4.3的安装步骤,包括Java和Scala环境搭建。还说明了Spark环境变量的配置,如在/etc/profile、spark-env.sh和slaves中的配置,最后通过测试验证安装配置并启动成功。
本文详细介绍了Hadoop2.8.5完全分布式集群的安装过程,以及Spark2.4.3的安装步骤,包括Java和Scala环境搭建。还说明了Spark环境变量的配置,如在/etc/profile、spark-env.sh和slaves中的配置,最后通过测试验证安装配置并启动成功。
一.安装Hadoop2.8.5完全分布式集群
二.Spark2.4.3安装
2.1 Java1.8环境搭建(Hadoop2.8.5安装已安装)
2.2 Scala-2.13.0环境搭建
1) 创建/usr/hadoop/scala目录
2)下载scala安装包
- 下载地址
- 将页面拉到最下面,下载如图安装包
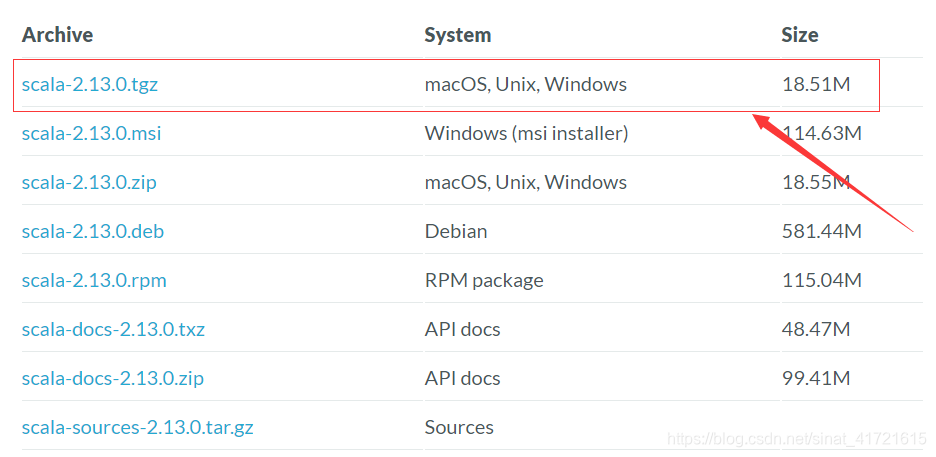
3) 解压安装包:tar -zxvf scala-2.13.0.tgz
4) 配置环境变量
vi /etc/profile
#scala install
export SCALA_HOME=/usr/hadoop/scala/scala-2.13.0
export PATH=$PATH:$SCALA_HOME/bin退出使立即生效:[root@master]source /etc/profile
5)验证安装

6) 复制到其他节点
在master节点上安装配置完成Scala后,将整个Scala目录拷贝到其他节点,并在各个节点上更新/etc/profile文件中的环境变量
2.3 下载安装spark
1)创建 /usr/hadoop/spark目录
2)下载对应hadoop版本的安装包:Downloads | Apache Spark
3)下载后解压,到/usr/hadoop/spark目录下。
三.配置Spark环境变量
1) /etc/profile配置
#spark install
export SPARK_HOME=/usr/hadoop/spark/spark-2.4.3-bin-hadoop2.7
export PATH=$PATH:$SPARK_HOME/bin
2) spark-env.sh配置
[root@master]# cd /usr/hadoop/spark/spark-2.4.3-bin-hadoop2.7/conf
[root@master]# vi spark-env.sh
#添加如下代码
export JAVA_HOME=/usr/hadoop/jdk1.8.0_201
export SCALA_HOME=/usr/hadoop/scala/scala-2.13.0/
export HADOOP_HOME=/usr/hadoop/hadoop-2.8.5
export HADOOP_CONF_DIR=/usr/hadoop/hadoop-2.8.5/etc/hadoop
export SPARK_MASTER_IP=master
export SPARK_MASTER_HOST=master
export SPARK_LOCAL_IP=master
export SPARK_WORKER_MEMORY=1g
export SPARK_WORKER_CORES=2
export SPARK_HOME=/usr/hadoop/spark/spark-2.4.3-bin-hadoop2.7export SPARK_MASTER_WEBUI_PORT=8888 #spark web访问端口号
export SPARK_DIST_CLASSPATH=$(/usr/hadoop/hadoop-2.8.5/bin/hadoop classpath)
注意:export SPARK_LOCAL_IP=master 在子节点中需要将master改为子节点的名称
3) slaves配置
slave1
slave2
4) 复制到其他节点
在master节点上安装配置完成Spark后,将整个spark目录拷贝到其他节点,并在各个节点上更新/etc/profile文件中的环境变量
5) 测试Spark
- 在master节点启动Hadoop集群
[root@master /hadoop-2.8.5] # sbin/start-all.sh
- 在master节点启动spark
[root@master spark-2.4.3-bin-hadoop2.7]# sbin/start-all.sh
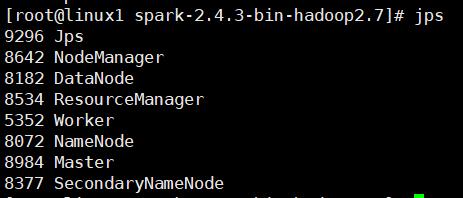
master:
slave:
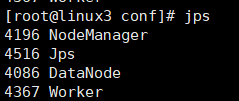
打开浏览器输入192.168.xx.xx:8080,看到如下活动的Workers,证明安装配置并启动成功:


















 521
521

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









