







一、stack
头文件: #include <stack>
定义:stack<data_type> stack_name;
如:stack <int> s;
操作:
empty() -- 返回bool型,表示栈内是否为空 (s.empty() )
size() -- 返回栈内元素个数 (s.size() )
top() -- 返回栈顶元素值 (s.top() )
pop() -- 移除栈顶元素(s.pop(); )
push(data_type a) -- 向栈压入一个元素 a(s.push(a); )
#include <iostream>
#include <stack>
#include <algorithm>
using namespace std;
int main(){
stack<int>s;
s.push(1);
s.push(2);
s.push(3);
cout << "Top: " << s.top() << endl;
cout << "Size: " << s.size() << endl;
s.pop();
cout << "Size: " << s.size() << endl;
if(s.empty()){
cout << "Is empty" << endl;
}else{
cout << "Is not empty" << endl;
}
return 0;
}
二、queue队列
头文件: #include <queue>
定义:queue <data_type> queue_name;
如:queue <int> q;
操作:
empty() -- 返回bool型,表示queue是否为空 (q.empty() )
size() -- 返回queue内元素个数 (q.size() )
front() -- 返回queue内的下一个元素 (q.front() )
back() -- 返回queue内的最后一个元素(q.back() )
pop() -- 移除queue中的一个元素(q.pop(); )
push(data_type a) -- 将一个元素a置入queue中(q.push(a); )
#include <iostream>
#include <queue>
#include <algorithm>
using namespace std;
int main(){
queue<int>s;
s.push(1);
s.push(2);
s.push(3);
cout << "Front: " << s.front() << endl;
cout << "Back: " << s.back() << endl;
s.pop();//去顶端
cout << "Size: " << s.size() << endl;
cout << "Front: " << s.front() << endl;
cout << "Back: " << s.back() << endl;
return 0;
}
三、priority_queue(优先队列)
一个拥有权值观念的queue,自动依照元素的权值排列,权值最高排在前面。缺省情况下,priority_queue是利用一个max_heap完成的
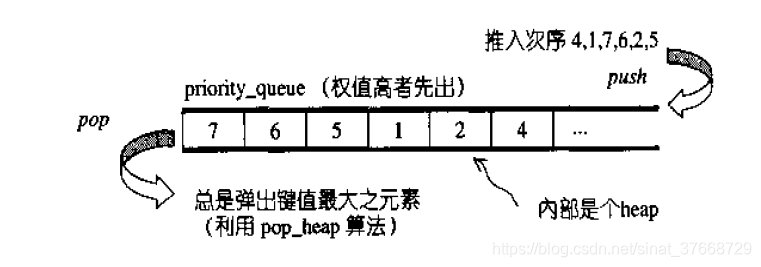
头文件: #include <queue>
定义:priority_queue <data_type> priority_queue_name;
如:priority_queue <int> q;//默认是大顶堆
操作:
q.push(elem) 将元素elem置入优先队列
q.top() 返回优先队列的下一个元素
q.pop() 移除一个元素
q.size() 返回队列中元素的个数
q.empty() 返回优先队列是否为空
#include <iostream>
#include <queue>
#include <algorithm>
using namespace std;
#define pow2(a) ((a)*(a))
#define dist2(x, y) (pow2(x) + pow2(y))
struct coord{
int x, y;
const bool operator<(const coord &b)const{
return (dist2(x, y) < dist2(b.x, b.y));
}
};
int main(){
priority_queue<coord> s;
coord a;
a.x = 3, a.y = 2;
s.push(a);
a.x = 1, a.y = 2;
s.push(a);
a.x = 2, a.y = 2;
s.push(a);
cout << "Size: " << s.size() << endl;
cout << "Top: " << s.top().x << ", " << s.top().y << endl;
s.pop();
cout << "Top: " << s.top().x << ", " << s.top().y << endl;
return 0;
}
四、vector(向量)
头文件: #include <vector>
定义:vector <data_type> vector_name;
如:vector <int> v;
操作:
vector<T> c 产生空的vector
vector<T> c1(c2) 产生同类型的c1,并将复制c2的所有元素
vector<T> c(n) 利用类型T的默认构造函数和拷贝构造函数生成一个大小为n的vector
vector<T> c(n,e) 产生一个大小为n的vector,每个元素都是e
vector<T> c(beg,end) 产生一个vector,以区间[beg,end]为元素初值
~vector<T>() 销毁所有元素并释放内存。
empty() -- 返回bool型,表示vector是否为空 (v.empty() )
size() -- 返回vector内元素个数 (v.size() )
push_back(data_type a) 将元素a插入最尾端
pop_back() 将最尾端元素删除
v[i] 类似数组取第i个位置的元素(v[0] )
#include <iostream>
#include <algorithm>
#include <vector>
using namespace std;
int main(){
vector<int> a;
for (int i = 0; i < 5; ++i){
a.push_back(5 - i);
}
cout << "Size: " << a.size() << endl;
a.pop_back();
a[0] = 1;
cout << "Size: " << a.size() << endl;
for (int i = 0; i < (int)a.size(); ++i){
cout << a[i] << ", " << endl;
}
cout << endl;
return 0;
}
五、map和multimap
所有元素都会根据元素的键值自动排序,map的所有元素都是pair,pair的第一个元素被视为键值,第二个元素为实值。map不允许两个元素有相同的键值,但multimap可以。
头文件: #include <map>
定义:map <data_type1, data_type2> map_name;
如:map <string, int> m;//默认按string由小到大排序
操作:
m.size() 返回容器大小
m.empty() 返回容器是否为空
m.count(key) 返回键值等于key的元素的个数
m.lower_bound(key) 返回键值等于key的元素的第一个可安插 的位置
m.upper_bound(key) 返回键值等于key的元素的最后一个可安 插的位置
m.begin() 返回一个双向迭代器,指向第一个元素。
m.end() 返回一个双向迭代器,指向最后一个元素的下一个 位置。
m.clear() 讲整个容器清空。
m.erase(elem) 移除键值为elem的所有元素,返回个数,对 于map来说非0即1。
m.erase(pos) 移除迭代器pos所指位置上的元素。
直接元素存取:m[key] = value; 查找的时候如果没有键值为key的元素,则安插一个键值为key的新元素,实值为默认(一般0)。
m.insert(elem) 插入一个元素elem
a)运用value_type插入
map<string, float> m;
m.insert(map<string, float>:: value_type ("Robin", 22.3));
b) 运用pair<>
m.insert(pair<string, float>("Robin", 22.3));
c) 运用make_pair()
m.insert(make_pair("Robin", 22.3));
#include <iostream>
#include <map>
#include <algorithm>
using namespace std;
int main(){
map<string, int> m2;
map<string, int>::iterator m2i, p1, p2;
m2["abd"] = 2;
m2["abc"] = 1;
m2["cba"] = 2;
m2.insert(make_pair("aaa", 9));
m2["abf"] = 4;
m2["abe"] = 2;
cout << m2["abc"] << endl;
m2i = m2.find("cba");
if(m2i != m2.end()){
cout << m2i->first << ": " << m2i->second << endl;
}else{
cout << "find nothing" << endl;
}
六、set和multiset
set 和 multiset会根据特定的排序准则,自动将元素排序,两者的不同之处在于multiset可以允许元素重复而set不允许元素重复。
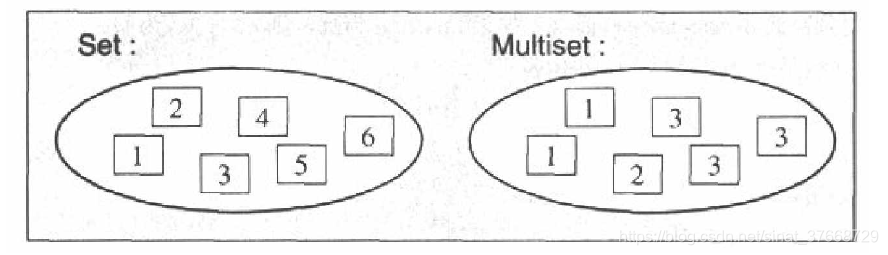
头文件: #include <set>
定义:set <data_type> set_name;
如:set <int> s;//默认由小到大排序
如果想按照自己的方式排序,可以重载小于号。
struct new_type{
int x, y;
bool operator < (const new_type &a)const{
if(x != a.x) return x < a.x;
return y < a.y;
}
}
set <new_type> s;
操作:
s.insert(elem) -- 安插一个elem副本,返回新元素位置。
s.erase(elem) -- 移除与elem元素相等的所有元素,返回被移除 的元素个数。
s.erase(pos) -- 移除迭代器pos所指位置上的元素,无返回值。
s.clear() -- 移除全部元素,将整个容器清空。
s.size() -- 返回容器大小。
s.empty() -- 返回容器是否为空。
s.count(elem) -- 返回元素值为elem的元素的个数。
s.lower_bound(elem) -- 返回elem的第一个可安插的位置。 也就是“元素值>= elem的第一个元素位置”。
s.upper_bound(elem) -- 返回elem的最后一个可安插的位置。也就是“元素值 > elem的第一个元素的位置”。
以上位置均为一个迭代器。
s.begin() -- 返回一个双向迭代器,指向第一个元素。
s.end() -- 返回一个双向迭代器,指向最后一个元素的下一 个位置
#include <iostream>
#include <set>
#include <algorithm>
using namespace std;
int main(){
set<string>s1;
set<string>::iterator iter1;
s1.insert("abc");
s1.insert("abc");
s1.insert("abc");
s1.insert("bca");
s1.insert("aaa");
cout << "ITERATE:" << endl;
for (iter1 = s1.begin(); iter1 != s1.end(); iter1++){ //迭代器
cout << (*iter1) << endl;
}
cout << "FIND:" << endl;
iter1 = s1.find("abc");
if(iter1 != s1.end()) {
cout << *iter1 << endl;
}else{
cout << "NOT FOUND" << endl;
}
return 0;
}
七、sort
头文件: #include <algorithm>
sort(begin, end);
sort(begin, end, cmp);
#include <algorithm>
#include <vector>
#include <iostream>
using namespace std;
int main()
{
int a[10];
vector <int> b;
for(int i=0;i<5;i++)
{
cin>>a[i];
b.push_back(a[i]);
}
sort(a,a+5);
sort(b.begin(),b.end());
for(int i=0;i<5;i++)
cout<<a[i]<<" ";
cout<<endl;
for(int i=0;i<5;i++)
cout<<b[i]<<" ";
return 0;
}
八、
upper_bound(begin, end, value);
查找大于value的最小位置
lower_bound(begin, end, value);
查找大于等于value的最小的位置


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









