







继承关系
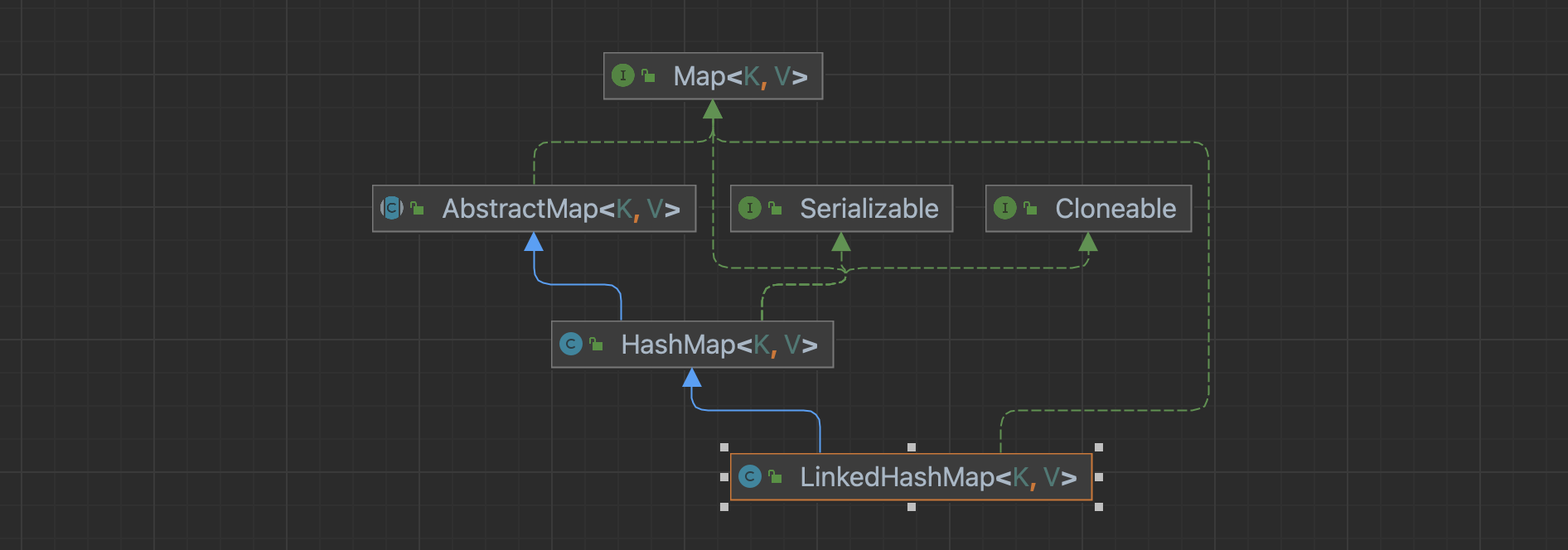
继承图上,可以看到这个LinkedHashMap继承整个HashMap,获得HashMap的全部特征,和HashMap相比,除此之外增加的特性是维护节点间的链表关系。而为了实现LinkedHashMap,JDK大叔设计的方式是在HashMap里面放一些钩子函数,当HashMap完成一定的动作后,调用钩子函数做些事情。除此之外,就是重写父类的某些关键的方法。
存储结构
存储结构上来说,LinkedHashMap与HashMap一致,只不过其节点内新增了前后节点的引用:
static class Entry<K,V> extends HashMap.Node<K,V> {
Entry<K,V> before, after;
Entry(int hash, K key, V value, Node<K,V> next) {
super(hash, key, value, next);
}
}
可以看到LinkedHashMap使用的Entry 继承自HashMap的Node,在此基础上维护before、after引用。
重要的字段
/**
* The head (eldest) of the doubly linked list.
*/
transient LinkedHashMap.Entry<K,V> head;
/**
* The tail (youngest) of the doubly linked list.
*/
transient LinkedHashMap.Entry<K,V> tail;
/**
* The iteration ordering method for this linked hash map: <tt>true</tt>
* for access-order, <tt>false</tt> for insertion-order.
*
* @serial
*/
final boolean accessOrder;
可以看到在LinkedHashMap中,增加了三个自动字段,分别是头结点和尾节点的实例引用。还有布尔值accessOrder来控制LinkedHashMap的行为
构造方法
public LinkedHashMap(int initialCapacity, float loadFactor) {
super(initialCapacity, loadFactor);
accessOrder = false;
}
public LinkedHashMap(int initialCapacity) {
super(initialCapacity);
accessOrder = false;
}
public LinkedHashMap() {
super();
accessOrder = false;
}
public LinkedHashMap(Map<? extends K, ? extends V> m) {
super();
accessOrder = false;
putMapEntries(m, false);
}
public LinkedHashMap(int initialCapacity,
float loadFactor,
boolean accessOrder) {
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 236
236

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









