







最近组内需要做强化学习相关研究,因为面对的是新项目,同事们对强化学习的原理都不太了解,我们就计划轮流在组内做一些不定期分享,补充相关的基础知识。于是我对强化学习的一些经典算法进行了梳理,并在此进行记录,以后也会不断更新。
本文主要分享《深度强化学习综述》中提到的深度强化学习(DRL)模型,后续将发布博客分享PPO, Decision Transformer等新方法。
目录
《深度强化学习综述》论文将深度强化学习(DRL)方法分为7类:
| DRL的类别 |
简要描述 |
| 基于值函数的DRL |
经典,作为下面几种方法的对照组 |
| 基于策略梯度的DRL |
DQN无法表示随机策略、无法表示连续动作,DPG适用范围比DQN更广 |
| 基于搜索与监督的DRL |
适合海量状态数、动作数的问题,如围棋 |
| 分层DRL |
适合严重稀疏反馈的复杂任务 |
| 基于多任务迁移的DRL |
适合需要处理多种任务的场景 |
| 基于多agent的DRL |
适合需要多个agent协作完成的任务 |
| 基于记忆与推理的DRL |
适合状态部分可观察和延迟奖励的任务 |
接下来将分别介绍这7类方法的代表性研究。
基于值函数的DRL
Deep Q Network(DQN):
Q learning算法需要维护一个Q table,只适用于离散的状态/动作空间,而DQN利用神经网络来预测value,不需要维护Q table,能够处理连续的状态空间。
Double DQN(DDQN):
DQN一般采用TD error作为损失函数
Q_π(s,a) <==> r +γQ_π(s',π(s'))
每一步计算损失时需要选择s'中最大Q值所对应的动作,DQN是根据target network选择一个具有最大Q值的动作,从而得到Q',由于选择和评价动作都是基于目标值网络的参数,可能会出现过高估计Q的问题。DDQN为了解决这个问题,先利用current network计算s'中最大Q值所对应的动作,然后由target network计算其Q值;DDQN在其他方面与DQN保持一致。DDQN将动作选择和策略评估分离开,降低了过高估计Q值的风险,Atari 游戏上的实验表明,DDQN可以估计出更加准确的Q值,效果比DQN更稳定。
基于优势学习(Advantage Learning)的DQN:
出发点也是为了缓解深度Q网络中存在的过估计问题,降低Q 值的估计误差。基于优势学习的DQN,通过在贝尔曼方程中定义新的操作符,来增大最优动作值和次优动作值之间的差异,从而获得更精确的Q值:
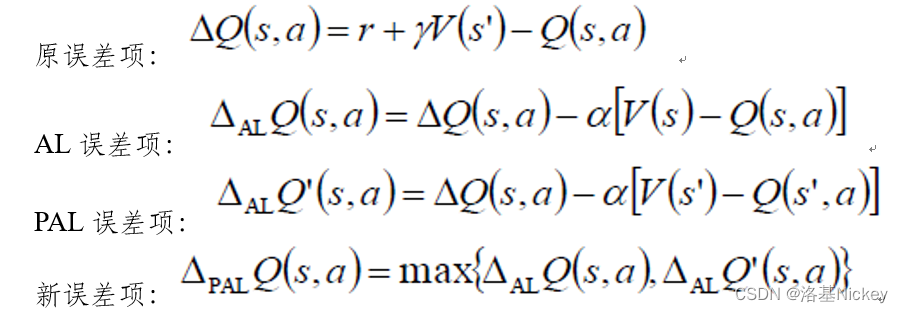
实验表明,用AL 和PAL 误差项来替代贝尔曼方程中的误差项,可以有效地增加最优和次优动作对应值函数之间的差异,从而获得更加精确的Q值。
基于优先级采样的DDQN:
DQN引入了经验回放机制,回放缓冲区里除了有当前策略的最新交互经验,还有旧策略的经验,这样做的出发点有两个:①DRL中耗时多的是与env交互,GPU训练网络耗时反而少,经验"回放"能减少与环境交互的次数 ②我们希望经验越多样越好,避免同质化的经验影响训练(比如可能引起的局部最优问题)。但是DQN是均匀采样所有经验,不区分经验的重要性。针对这个问题,研究者在DDQN中引入了基于优先级的经验采样方法,提高有价值样本的采样概率,从而加快最优策略的学习。
具体的,基于优先级采样的方法将每个样本的TD error作为评价优先级的标准,TD error的绝对值越大,该样本被采样的概率越高(TD-error值越大则表示Q-target与Q-evaluator之间的价值评估的差距越大,从而在梯度上更具学习价值,避免了对无效转移样本的学习)。优先级采样引入了几个关键技术:①重要性采样权重(importance-sampling weights),缓解优先级分布不断更新导致的系统偏差②SumTree总和二叉树,加速实现优先级排序。相比于DDQN,收敛速度有了很大的提高,避免了一些没有价值的迭代,是常用的算法。
Dueling Network:
修改了DQN的网络结构:DQN 将CNN 提取的抽象特征经过全连接层后,直接在输出层输出对应动作的Q 值。而引入竞争网络结构的模型则将CNN 提取的抽象特征分流到两个支路中:其中一路是状态值函数,对状态进行打分;另一路代表优势函数(advantage function
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 3640
3640

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









