




 本文介绍了C++ STL算法的基础知识,包括algorithm、numeric和functional头文件的作用,区分质变与非质变算法,展示了sort函数实例和迭代器的重要性。重点讲解了STL算法的泛型化过程,以find函数为例,演示了如何将算法应用于不同数据结构。最后,通过模板技术实现了一个通用的find函数,适用于各种容器。
本文介绍了C++ STL算法的基础知识,包括algorithm、numeric和functional头文件的作用,区分质变与非质变算法,展示了sort函数实例和迭代器的重要性。重点讲解了STL算法的泛型化过程,以find函数为例,演示了如何将算法应用于不同数据结构。最后,通过模板技术实现了一个通用的find函数,适用于各种容器。
一、STL算法介绍
STL算法部分主要是由三个头文件承担: algorithm、numeric、functional
- algorithm:意思是算法,只要想使用STL库中的算法函数就得包含该头文件。
- numeric:包含了一系列用于计算数值序列的算法,其具有一定的灵活性,也能够适用于部分非数值序列的计算
- functional:定义了一些模板,可以用来声明函数对象。
二、STL算法分类
质变与非质变算法:
- 质变算法:会改变操作对象的值。所有的STL算法都作用在[first,last)所标示的区间上,在运算过程中改变区间元素值。例如:copy,swap,replace,fill,remove,permulation,partition,sort等。
- 非质变算法:不改变操作对象之值。例如:find,search,count,equal,max,min等。
举个例子
int test[] = {100,23,45,53,56,90,98,96,95};
vector<int> temp(test,test+sizeof(test)/sizeof (int));
vector<int>::const_iterator crita1 = temp.begin();
vector<int>::const_iterator crita2 = temp.end();
sort(crita1, crita2);以上sort操作,编译器会报错
三、STL算法的一般形式
STL算法的一般形式——泛型算法。所有泛型算法的前两个参数都是一对迭代器,通常称为first,last,以标示算法的操作区间,前闭后开。这个[first,last)区间的必要条件是:必须能够经由increment(累加)操作的反复运用,从first到last。编译器本身无法强求这一点,如果这个条件不成立,会导致未可预期的后果。
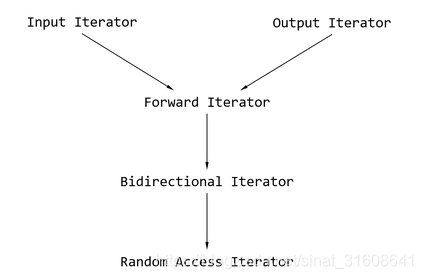
根据行进特性,迭代器分五种:Input Iterator、Output Iterator、Forward Iterator、Bidirectional Iterator、Random Access Iterator。这五种迭代器的逻辑层次见下图。每一个STL算法的声明都表现出它所需要的最低程度的迭代器类型。比如 find() 函数,它需要一个Input Iterator,但你给它传Forward Iterator或Bidirectional Iterator等都可以,就是不能传Output Iterator,否则会导致错误。同样,将无效的迭代器传给某个算法并不能保证在编译的时候能被捕捉,因此一定要小心使用。
许多STL算法不止支持一个版本。这一类的算法的某个版本采用缺省运算行为,另一个版本提供额外参数,接受外界传入一个仿函数,以便采用其他策略,这种函数一般会用"_if"结尾表示。
质变算法通常提供两个版本,就地的和复制到他处的,一般复制到他处的会以"_copy"结尾表示。当然并非所有质变算法都有copy版本,如 sort() 就没有。
所有的数值算法都实现于 <stl_numeric.h> 中,但这是内部文件,规定用户必须包含其上层的 <numeric> 。其他的算法实现于 <stl_algo.h> 和 <stl_algobase.h> 中,也都是内部文件,欲使用这些算法须包含上层头文件 <algorithm> 。
四、算法的泛化过程
如设计一个算法,使它适用于任何(大多数)数据结构?
将算法独立于其所处理的数据结构之外,不受数据结构的羁绊。关键在于:将操作对象的型别抽象化,把操作对象的标识符和区间目标的移动行为抽象化。整个算法也就在一个抽象的层面上了。整个过程称为泛型化(generalized),简称泛化。
让我们看看算法泛化的一个实例,以简单的循序查找为例。假设我们要写一个find()函数,在array中寻找特定值。面对array,我们的直觉反应是:
int* find(int *arrayHead,int arraySize,int value)
{
int i;
for(i=0;i<arraySize;i++)
{ if(arrayHead[i]==value)
break;
}
return &(arrayHead[i]);
}该函数在某一个区间内查找,返回的是一个指针,指向符合标准的第一个元素。
为例让find()函数适用于所有类型的容器,其操作应当抽象化些,让find()接受两个指针作为参数,标示出一个操作区间,这就是很好的做法:
int* find(int* begin,int* end,int value)
{
while(begin!=end&&*begin!=value)
++begin;
return begin;
}由于find()函数之内并无任何操作是针对特定的整数array而发的,所以我们将它改成一个template:
template<class T>
T* find(T* begin,T*end,const T& value)
{
while(begin!=end&&*begin!=value)
++begin;
return begin;
}C++有一个极大的优点,几乎所有的东西都可以改为程序员自定义的形式或行为,上述这些操作符和操作行为都可以被重载(overloaded),既是如此,何必将find局限于使用指针呢?从原生指针中的思想框架逃离出来。
比如我们以一个原生指针指向某个List(链表),则对该指针进行“++”操作并不能使它指向下一个串行节点,但如果我们设计class,拥有原生指针的行为,并使其“++”操作指向list的下一个节点,那么find()就可以施行于List容器身上了。这便是迭代器的观念。迭代器是一种行为类似指针的对象,换句话说,是一种smart pointers。现以迭代器重新写过:
template<class Iterator,class T>
Iterator* find(Iterator* begin,Iterator* end,const T& value)
{
while(begin!=end&&*begin!=value)
++begin;
return begin;
}这便是一个完全泛化的find()函数,你可以在C++标准库的某一个头文件中看到它,长相几乎一模一样。
参考:
https://blog.youkuaiyun.com/qq_43549984/article/details/99691556
https://blog.youkuaiyun.com/qq_34777600/article/details/80503190

















 1648
1648

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









