






Hive笔记
–hive本质
将 SQL 语句转换为 MapReduce 任务运行
–hive组件
1).用户接口
CLI:shell命令行
JDBC/ODBC:Java的API接口
webGUI:web访问hive
2). MetaStore元数据存储
存储在关系型数据库如MySQL,Derby中。元数据主要包括表名,列,分区,属性,数据目录等
3).Driver组件
compiler(编译器):将HiveQL转化为抽象语法树再转为查询块然后转为逻辑查询计划再转为物理查询计划最终选择最佳决策的过程
optimizer(优化器)
executor(执行器)
–hive原理
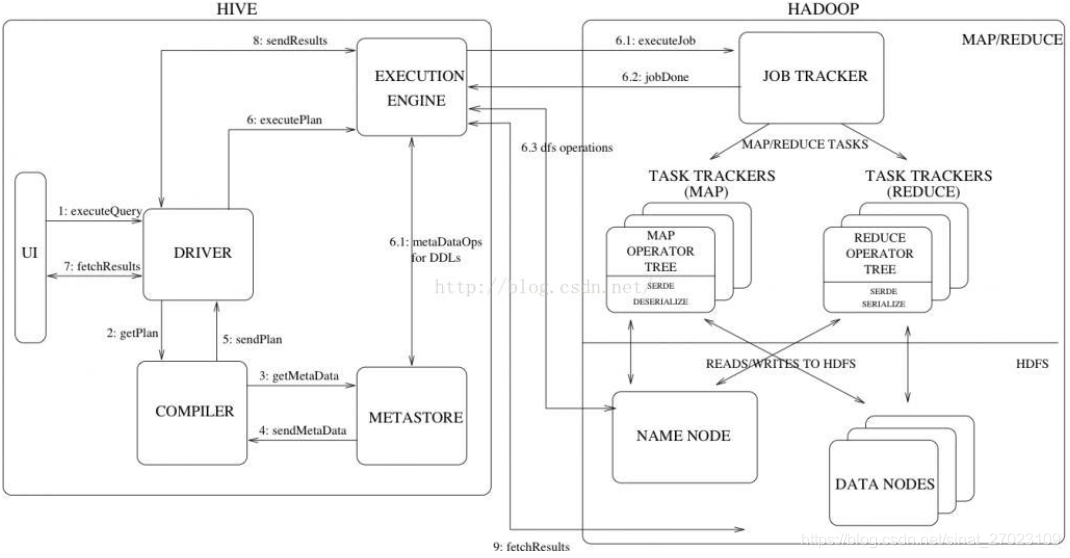
大致流程:
1.用户提交查询等任务给Driver
2.compiler获得该任务plan
3.compiler根据用户任务去meta store获取所需的hive元数据信息
4.compiler得到元数据信息,对任务进行编译,先将hql转换为抽象语法树,然后抽象语法树转换成查询块,将查询块转化为逻辑的查询计划,重写逻辑查询计划,将逻辑计划转化为物理计划(mapreduce),最后选择最佳策略
5.将最终计划提交给Driver
6.Dirver将计划转交给ExecutionEngine去执行,获取元数据信息,提交给JobTracker或者SourceManager执行该任务,任务会直接读取HDFS中文件进行相应的操作
7.获取执行结果
8.取得并返回执行结果
–查看hive版本
hive version
–hive命令
hive #进入hive控制台
–查看数据库
show databases;
–使用数据库
use default #默认default数据库
–查看数据库下表
show tables;
–创建表(内部表)
create table test(
id string comment ‘ID’,
name string comment ‘姓名’,
age string comment ‘年龄’,
date string comment ‘日期’
)
comment ‘测试表’
partitioned by(dt string comment ‘日期’)
row format delimited
fields terminated by ‘,’ --列分割:默认逗号
lines terminated by ‘\n’ --行分割:默认换行符
stored as textfile
;
–查看建表语句
show create table test;
–查看表信息
desc test;
–修改注释
alter table test change column id id string comment ‘’;
–删除表
drop table test; #数据一并删除
–导入数据(本地/HDFS)
load data [local] inpath ‘url’ [overwrite] into table test; --local:导入本地数据; overwrite:重写该表
–sqoop从关系型数据库导出数据到hive
–导出数据(本地/HDFS)
insert overwrite (local) directory ‘路径’ row format delimited fields terminated by ‘分隔符’ select * from table;
–sqoop从hive导出数据到关系型数据库
–查看HDFS上hive路径
hdfs dfs -ls /user/hive/warehouse/
–查看HDFS上hive文件前10行,后10行
hdfs dfs -cat /user/hive/warehouse/default/test/000_0 | head -10
hdfs dfs -cat /user/hive/warehouse/default/test/000_0 | tail -10
–跳过行首尾若干行(建表语句最后)
tblproperties(“skip.header.line.count”=“n”, “skip.footer.line.count”=“n”)
–设置hive执行引擎(当前会话)
set hive.execution.engine=spark #spark计算引擎
set hive.execution.engine=mr #默认mr引擎
–hive优化
set hive.exec.parallel #控制一个SQL中多个可并行执行job,默认false
set hive.exec.dynamic.partition # 是否动态分区,在0.9.0及以后默认为true,当分区不存在时可自动创建
– hive UDF
1.打包
maven->package
2.添加jar到hive
hive>add jar jar_path;
3.创建UDF函数
hive>create temporary function function_name as ‘function_path’;
4.查看函数
hive>show functions;

















 526
526

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









