







今天我们来聊一聊LFM(Latent Factor Model)的故事,这也算是我们在推荐系统里第一个用到的学习算法了吧,前面讲的两个协同过滤都是基于统计来的。
协同过滤的思路就是基于用户和物品的交互行为,要么计算用户间的相似度,推荐相似度高的用户喜欢的物品,因为这两个用户可能兴趣相投;要么就是计算物品间的相似度,推荐和历史记录相似度很高的物品,因为他们可能属于同一类别的商品。我们做决策的基础都是默认了商品是有类别的,可能有的用户都喜欢某一类商品,所以这些用户之间相似度高,可能有的商品是属于同一类别的,因此这些商品的相似度很高。那既然这样,有没有可能直接得到商品的类别呢?这样我们就可以直接根据类别去进行推荐了~
LFM就是基于这样的想法,假设商品存在若干个种类,那么每个用户对每个类会有一个兴趣度,同样的,每个类内又有若干种商品,每个商品在这个类内又会有一个对应的权重。这样,对于任何一个用户-商品对,我们都可以用下述公式来表达
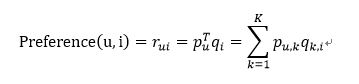
OK,那么下一步就是去计算矩阵P和Q,最常见的方法就是在训练集上不停迭代更新参数直至参数收敛。既然需要迭代,那我们得有一个损失函数或者目标函数作为我们迭代的依据,这里我们选用的是最常见的预测值和实际值差值的平方和,并且加上了正则项防止过拟合,具体如下
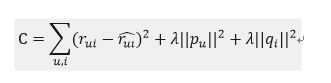
熟悉机器学习的同学应该很清楚,接下来就是基于梯度下降去优化这个损失函数,这里就不赘述了。但是我们还有一个问题,对于显式反馈的数据,我们直接用评分数据作为训练集,但是对于隐式反馈而言,只有正样本,我们可以把这些数据标注为1,但同时我们也需要负样本,所以往往需要我们从所有样本里选择样本构建负样本集。这里在构建负样本的时候有一个小小的trick,要尽量选择那些非常热门但是用户却没有发生交互的物品,因为这样构建的样本往往更具有代表性,也有利于我们的training。在movielens数据集中,我们以样本出现的次数作为权重,随机选择样本构建负样本集,实现如下
def Random_Negative_Sampling(self, items):
ret = {}
for i in items:
ret[i] = 1
count = 0
for i in range(0, len(items)*5):
item = self.items_pool[random.randint(0, len(self.items_pool)-1)]
if item in items:
continue
ret[item] = 0
count += 1
if count > 2*len(items):
break
return ret在实际实现LFM算法的过程中,自己遇到了一个大坑,提出来希望大家注意。
先问问你,如何去计算一个用户对一个物品的喜爱程度?是不是直接用上面那个公式,用用户对类的喜爱程度和该物品在此类中的权重乘积的累加呀。那么恭喜你,如果这样做,效果非常不好,一是太难收敛,二
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 2569
2569

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









