







 本文介绍了在处理不平衡分类数据集时,如何使用合成少数类过采样技术(SMOTE)来改善模型性能。SMOTE通过从少数类中合成新样本来平衡数据,而不是简单地复制少数类样本。此外,还探讨了SMOTE的变种,如Borderline-SMOTE和ADASYN,它们分别基于支持向量机和样本密度来生成更接近决策边界的合成样本。
本文介绍了在处理不平衡分类数据集时,如何使用合成少数类过采样技术(SMOTE)来改善模型性能。SMOTE通过从少数类中合成新样本来平衡数据,而不是简单地复制少数类样本。此外,还探讨了SMOTE的变种,如Borderline-SMOTE和ADASYN,它们分别基于支持向量机和样本密度来生成更接近决策边界的合成样本。
Last Updated on August 21, 2020
Imbalanced classification involves developing predictive models on classification datasets that have a severe class imbalance.
The challenge of working with imbalanced datasets is that most machine learning techniques will ignore, and in turn have poor performance on, the minority class, although typically it is performance on the minority class that is most important.
One approach to addressing imbalanced datasets is to oversample the minority class. The simplest approach involves duplicating examples in the minority class, although these examples don’t add any new information to the model. Instead, new examples can be synthesized from the existing examples. This is a type of data augmentation for the minority class and is referred to as the Synthetic Minority Oversampling Technique, or SMOTE for short.
In this tutorial, you will discover the SMOTE for oversampling imbalanced classification datasets.
After completing this tutorial, you will know:
- How the SMOTE synthesizes new examples for the minority class.
- How to correctly fit and evaluate machine learning models on SMOTE-transformed training datasets.
- How to use extensions of the SMOTE that generate synthetic examples along the class decision boundary.
Kick-start your project with my new book Imbalanced Classification with Python, including step-by-step tutorials and the Python source code files for all examples.
Let’s get started.
SMOTE Oversampling for Imbalanced Classification with Python
Photo by Victor U, some rights reserved.
Tutorial Overview
This tutorial is divided into five parts; they are:
- Synthetic Minority Oversampling Technique
- Imbalanced-Learn Library
- SMOTE for Balancing Data
- SMOTE for Classification
- SMOTE With Selective Synthetic Sample Generation
- Borderline-SMOTE
- Borderline-SMOTE SVM
- Adaptive Synthetic Sampling (ADASYN)
Synthetic Minority Oversampling Technique
A problem with imbalanced classification is that there are too few examples of the minority class for a model to effectively learn the decision boundary.
One way to solve this problem is to oversample the examples in the minority class. This can be achieved by simply duplicating examples from the minority class in the training dataset prior to fitting a model. This can balance the class distribution but does not provide any additional information to the model.
An improvement on duplicating examples from the minority class is to synthesize new examples from the minority class. This is a type of data augmentation for tabular data and can be very effective.
Perhaps the most widely used approach to synthesizing new examples is called the Synthetic Minority Oversampling TEchnique, or SMOTE for short. This technique was described by Nitesh Chawla, et al. in their 2002 paper named for the technique titled “SMOTE: Synthetic Minority Over-sampling Technique.”
SMOTE works by selecting examples that are close in the feature space, drawing a line between the examples in the feature space and drawing a new sample at a point along that line.
Specifically, a random example from the minority class is first chosen. Then k of the nearest neighbors for that example are found (typically k=5). A randomly selected neighbor is chosen and a synthetic example is created at a randomly selected point between the two examples in feature space.
… SMOTE first selects a minority class instance a at random and finds its k nearest minority class neighbors. The synthetic instance is then created by choosing one of the k nearest neighbors b at random and connecting a and b to form a line segment in the feature space. The synthetic instances are generated as a convex combination of the two chosen instances a and b.
— Page 47, Imbalanced Learning: Foundations, Algorithms, and Applications, 2013.
This procedure can be used to create as many synthetic examples for the minority class as are required. As described in the paper, it suggests first using random undersampling to trim the number of examples in the majority class, then use SMOTE to oversample the minority class to balance the class distribution.
The combination of SMOTE and under-sampling performs better than plain under-sampling.
— SMOTE: Synthetic Minority Over-sampling Technique, 2011.
The approach is effective because new synthetic examples from the minority class are created that are plausible, that is, are relatively close in feature space to existing examples from the minority class.
Our method of synthetic over-sampling works to cause the classifier to build larger decision regions that contain nearby minority class points.
— SMOTE: Synthetic Minority Over-sampling Technique, 2011.
A general downside of the approach is that synthetic examples are created without considering the majority class, possibly resulting in ambiguous examples if there is a strong overlap for the classes.
Now that we are familiar with the technique, let’s look at a worked example for an imbalanced classification problem.
Imbalanced-Learn Library
In these examples, we will use the implementations provided by the imbalanced-learn Python library, which can be installed via pip as follows:
sudo pip install imbalanced-learn
| 1 |
sudo pip install imbalanced-learn |
You can confirm that the installation was successful by printing the version of the installed library:
# check version number import imblearn print(imblearn.__version__)
| 1 2 3 |
# check version number import imblearn print(imblearn.__version__) |
Running the example will print the version number of the installed library; for example:
0.5.0
| 1 |
0.5.0 |
Want to Get Started With Imbalance Classification?
Take my free 7-day email crash course now (with sample code).
Click to sign-up and also get a free PDF Ebook version of the course.
Download Your FREE Mini-Course
SMOTE for Balancing Data
In this section, we will develop an intuition for the SMOTE by applying it to an imbalanced binary classification problem.
First, we can use the make_classification() scikit-learn function to create a synthetic binary classification dataset with 10,000 examples and a 1:100 class distribution.
... # define dataset X, y = make_classification(n_samples=10000, n_features=2, n_redundant=0, n_clusters_per_class=1, weights=[0.99], flip_y=0, random_state=1)
| 1 2 3 4 |
... # define dataset X, y = make_classification(n_samples=10000, n_features=2, n_redundant=0, n_clusters_per_class=1, weights=[0.99], flip_y=0, random_state=1) |
We can use the Counter object to summarize the number of examples in each class to confirm the dataset was created correctly.
... # summarize class distribution counter = Counter(y) print(counter)
| 1 2 3 4 |
... # summarize class distribution counter = Counter(y) print(counter) |
Finally, we can create a scatter plot of the dataset and color the examples for each class a different color to clearly see the spatial nature of the class imbalance.
... # scatter plot of examples by class label for label, _ in counter.items(): row_ix = where(y == label)[0] pyplot.scatter(X[row_ix, 0], X[row_ix, 1], label=str(label)) pyplot.legend() pyplot.show()
| 1 2 3 4 5 6 7 |
... # scatter plot of examples by class label for label, _ in counter.items(): row_ix = where(y == label)[0] pyplot.scatter(X[row_ix, 0], X[row_ix, 1], label=str(label)) pyplot.legend() pyplot.show() |
Tying this all together, the complete example of generating and plotting a synthetic binary classification problem is listed below.
# Generate and plot a synthetic imbalanced classification dataset from collections import Counter from sklearn.datasets import make_classification from matplotlib import pyplot from numpy import where # define dataset X, y = make_classification(n_samples=10000, n_features=2, n_redundant=0, n_clusters_per_class=1, weights=[0.99], flip_y=0, random_state=1) # summarize class distribution counter = Counter(y) print(counter) # scatter plot of examples by class label for label, _ in counter.items(): row_ix = where(y == label)[0] pyplot.scatter(X[row_ix, 0], X[row_ix, 1], label=str(label)) pyplot.legend() pyplot.show()
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
# Generate and plot a synthetic imbalanced classification dataset from collections import Counter from sklearn.datasets import make_classification from matplotlib import pyplot from numpy import where # define dataset X, y = make_classification(n_samples=10000, n_features=2, n_redundant=0, n_clusters_per_class=1, weights=[0.99], flip_y=0, random_state=1) # summarize class distribution counter = Counter(y) print(counter) # scatter plot of examples by class label for label, _ in counter.items(): row_ix = where(y == label)[0] pyplot.scatter(X[row_ix, 0], X[row_ix, 1], label=str(label)) pyplot.legend() pyplot.show() |
Running the example first summarizes the class distribution, confirms the 1:100 ratio, in this case with about 9,900 examples in the majority class and 100 in the minority class.
Counter({0: 9900, 1: 100})
| 1 |
Counter({0: 9900, 1: 100}) |
A scatter plot of the dataset is created showing the large mass of points that belong to the majority class (blue) and a small number of points spread out for the minority class (orange). We can see some measure of overlap between the two classes.
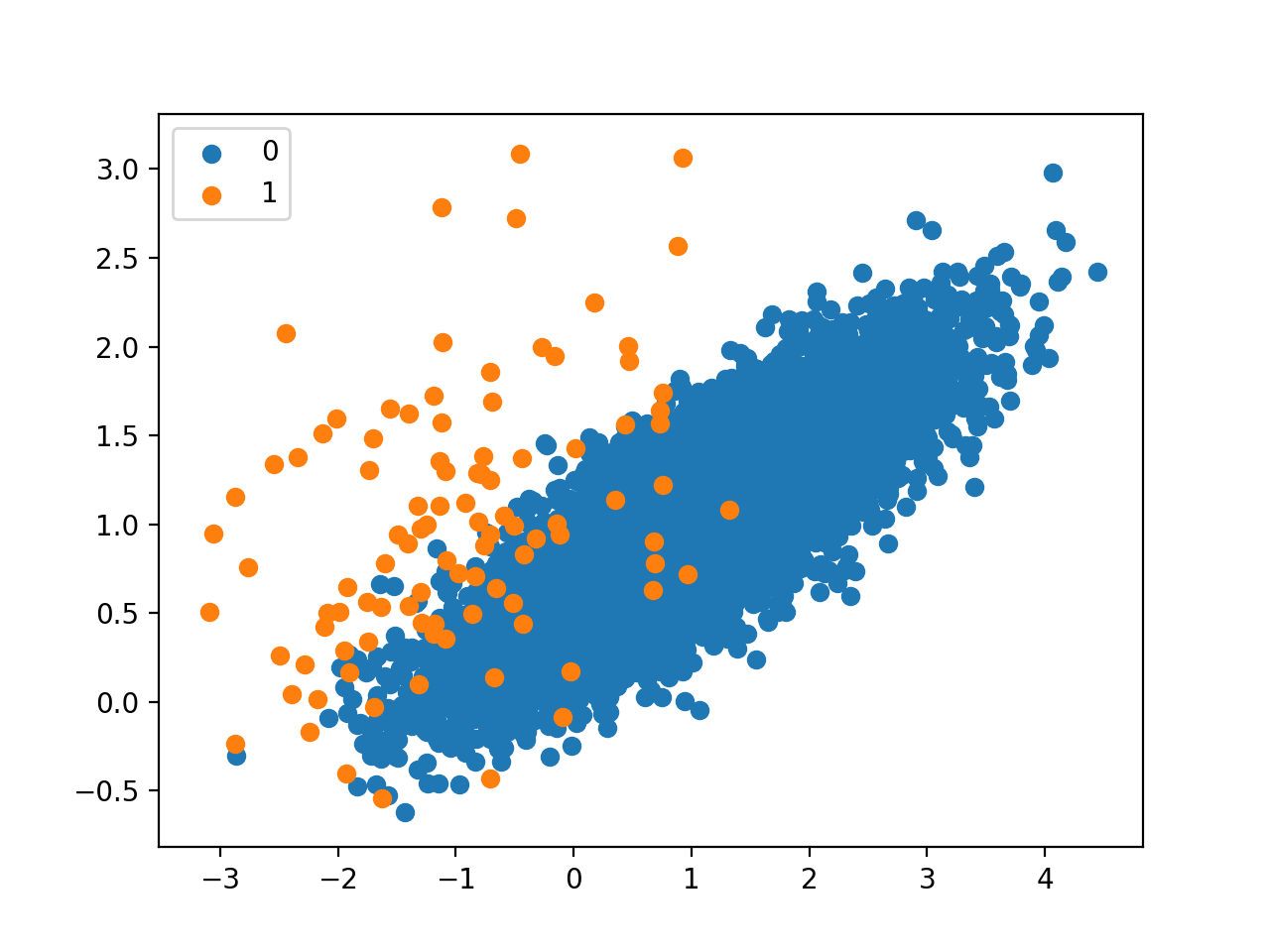
Scatter Plot of Imbalanced Binary Classification Problem
Next, we can oversample the minority class using SMOTE and plot the transformed dataset.
We can use the SMOTE implementation provided by the imbalanced-learn Python library in the SMOTE class.
The SMOTE class acts like a data transform object fro
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 92
92

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









