




 本文深入解析正则表达式的各个组成部分,包括元字符、量词、断言、组引用等核心概念,以及如何在实际场景中应用这些知识。
本文深入解析正则表达式的各个组成部分,包括元字符、量词、断言、组引用等核心概念,以及如何在实际场景中应用这些知识。
正则表达式
正则表达式不限语言,是一个体积小能量大的神器,不仅仅可以用于编程,还可以在文本编辑器作为工具使用。学好它很有必要。那么开始吧。
以jquery手册网站上的正则表达式速查表作为参考。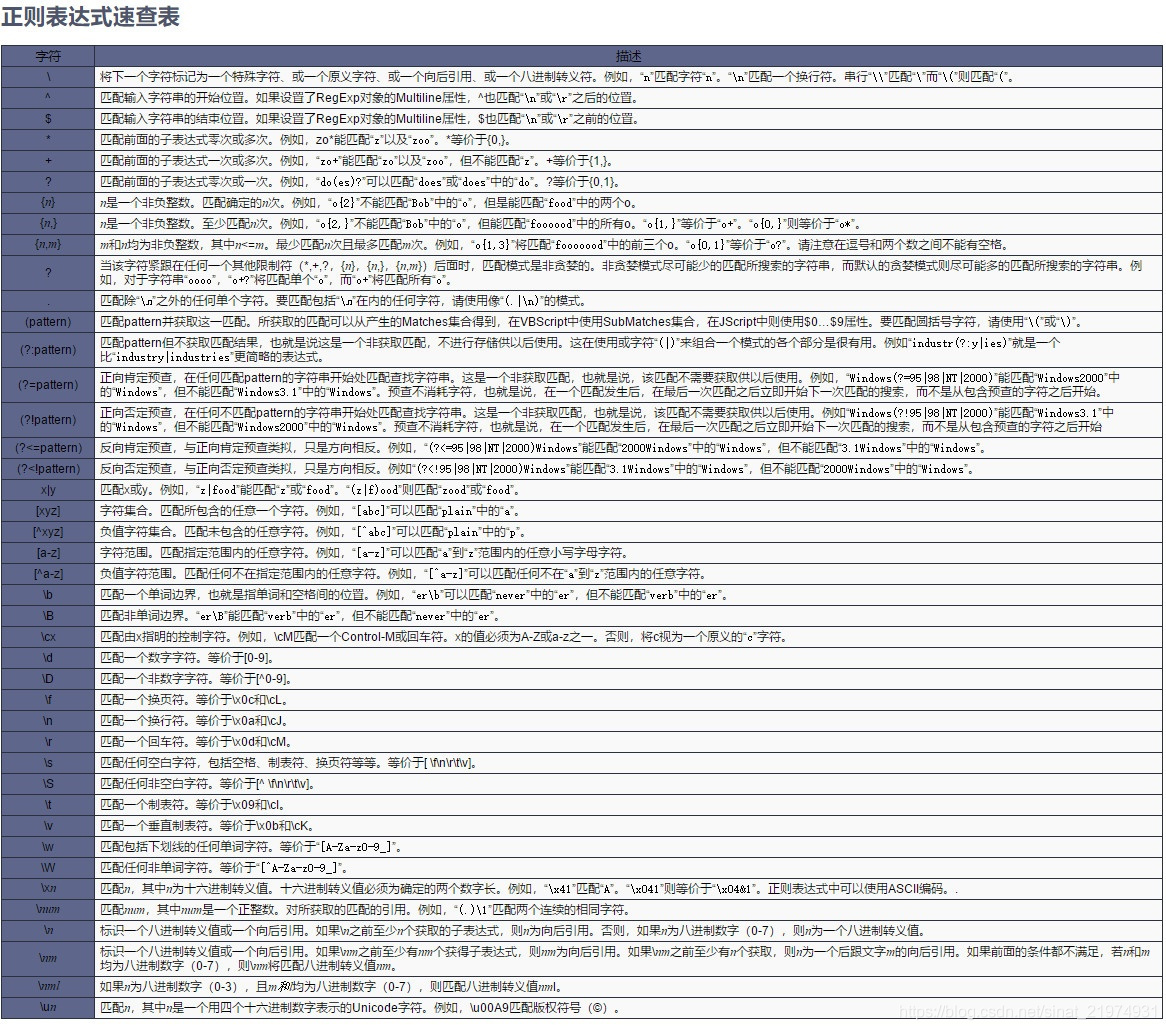
正则表达式基本上分为以下几个主要的部分。
1. 元字符组合方式及量词
-
小括号()
()表示分组,一个括号为一组。如图:

从左往右数,一个左括号为一组。
分组编号是从1开始,而不是0。第0组始终为匹配到的所有字符。如图测试结果:
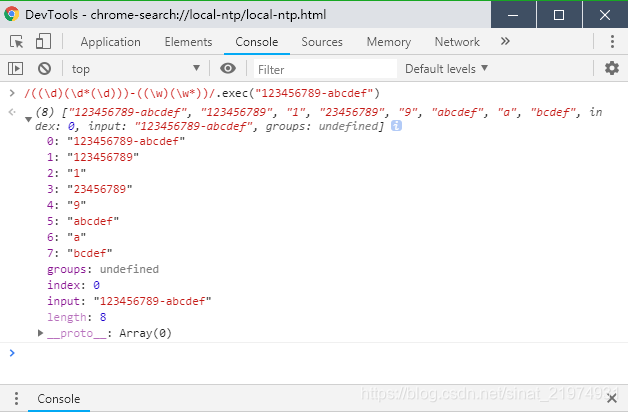
小括号还用于组合基本的匹配pattern。如图(第0组为abd),要匹配连续的abc或者abd:
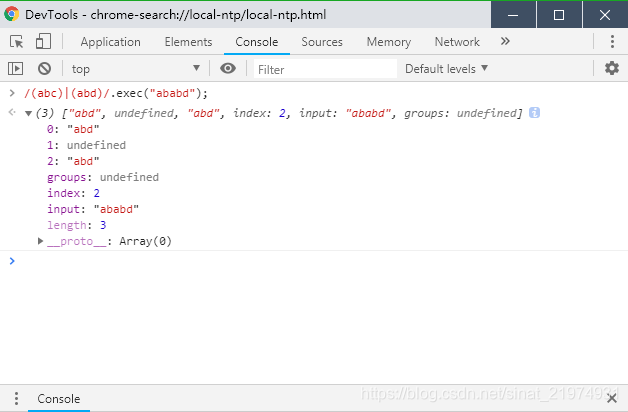
指定多个连续字符用小括号。下面会说到中括号。 -
中括号[]
① [abc]*: 用于匹配中括号中的任意字符,如aaaabbccbbac。中括号中的字符是打散的,不能用于按顺序匹配,要按顺序匹配请使用()。[abc(dg)]匹配efg也是可以匹配到的,
② [a-zA-Z] : 中括号中加-表示字符区间,可以是任意字符区间,数字区间等。比如\u4e00-\u9fa5表示中文汉字区间,匹配所有的汉字。其他字符区间可以查unicode字符编码区间。
③ [^0-9]:表示非数字。中括号内加^表示字符以外的集合。 -
量词
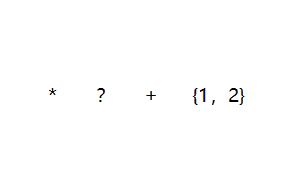
*: 0个到多个,即 n≥0
?:0个或者1个,即n = 0或者n = 1;
+:1个到多个,即n≥1
{1,2}:1个到2个,即1≤n≤2。其变体{0,2}表示n≤2,{1,}表示n≥1,{2}表示n=2。
因此{0,}相当于*,{0,1}相当于?,{1,}相当于+。没有{,2}的写法
以上量词都可以直接用于字符后面,或者小括号中括号后面
测试如下:
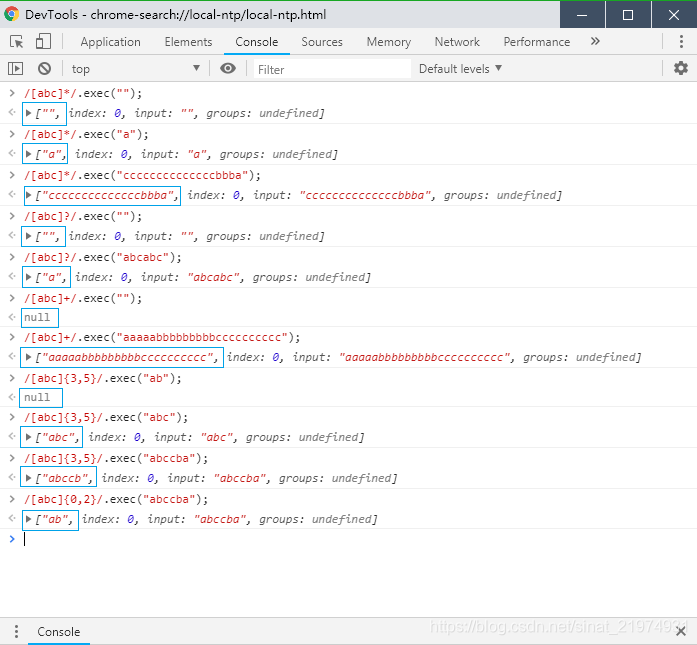
? 还有另一个用法:设定是否贪婪匹配。举个例子,用[a]*匹配aaaaabc,那么匹配了几个a?正则默认是开启贪婪匹配,因此默认会匹配到aaaaa。如果是[a]*?则是关闭贪婪,因此匹配到的a的数量为0个。简单地说,就是,在能匹配到的前提下,尽可能少地重复前面的字符。
那么,ab*?c+?匹配aaaabbbbccc,匹配了几个b,几个c?结果是:abbbbc,b至少要4个才能保证匹配,而只需要一个c即可保证匹配。测试如图:
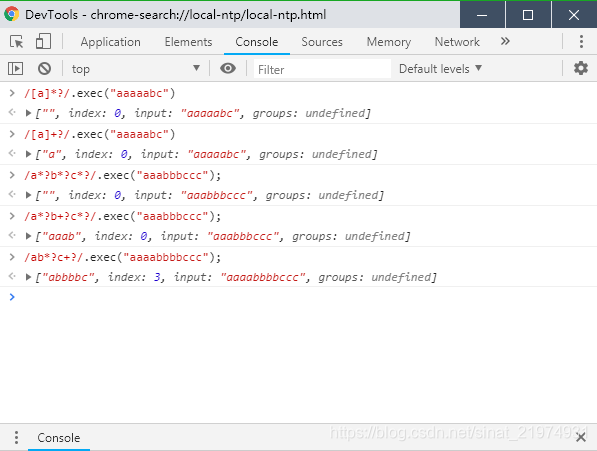
由图中的/a*?b+?c*?/.exec(“aaabbbccc”);还可以看出,对于前面能匹配到的字符a,即使不贪婪匹配,也是不会跳过的。(既然能在0位置完成匹配,那就不必向后移动,也即不会出现bbb的结果)
2. 元字符
常用的元字符如下: 最最常用的就是这4个,其中小写表示是,大写表示否。
| 是 | 不是 | |
|---|---|---|
| 空白字符 | \s | \S |
| 数字 | \d | \D |
| 字母数字下划线 | \w | \W |
| 单词边界 | \b | \B |
- \s、\S
\s表示匹配所有空白字符(看不见的那些:空格,tab,回车换行等),\S表示所有非空白字符,也就是能看见的那些。因此[\s\S]就匹配所有的字符,[\s\S]*匹配整篇文章。 - \d、\D
匹配所有半角数字,即0-9这些,全角的不行。同样地,[\d\D]也匹配所有的字符。 - \w、\W
字母数字下划线,这个词经常听说吧,\w就是匹配这个。等同于a-zA-Z0-9_。[\w\W]匹配所有字符。 - \b、\B
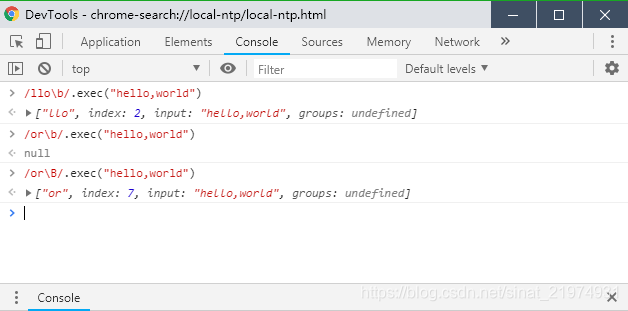
\b用于匹配单词边界。比如对于hello, world,llo\b可以匹配到hello中的llo,因为o后面是边界,而or\b却不能匹配到world中的or,因为or后面不是单词边界,用or\B可以匹配到。
- 其他元字符
| 名称 | 字符 |
|---|---|
| tab | \t |
| 换页符 | \f |
| 垂直制表符 | \v |
| 回车 | \r |
| 换行 | \n |
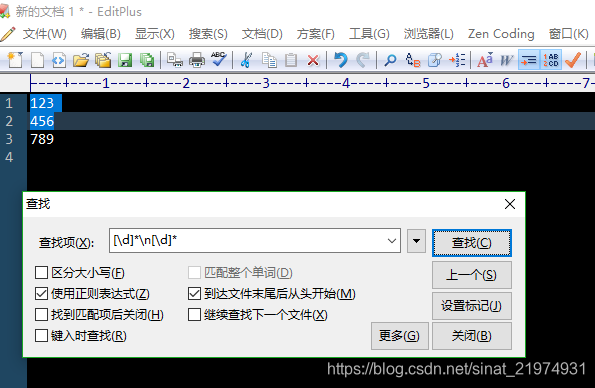
\t匹配tab键,这个我想就不用解释了。\f\v基本不用,反正我是没有使用过,等用到的时候再研究也不迟。\r\n匹配回车换行,这里需要注意一下,有的文本编辑器行末是用\r\n分隔的,而有的是用\n分隔的。eclipse是\n。\n不行就试试\r\n,总有一个可以的。
除此之外还有4个: ^、$、.、|
- ^: 中括号里的^表示非,而正则表达式开头的^则表示匹配行开头或者文章开头(多行模式下)
- $: 同样地,$表示匹配行结尾或文章结尾
- .:点号匹配除换行以外的任意字符(多行模式下)。
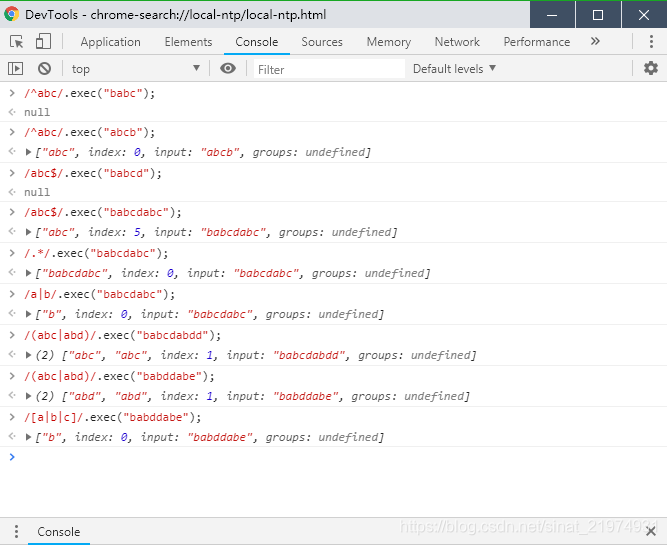
- |:竖线表示或。可以在字符间直接使用,也可以用于小括号或者中括号中,但在中括号中使用没有意义。测试如图:
3. 断言
断言其实很容易理解:
| 左边 | 右边 | |
|---|---|---|
| 是 | (?<=pattern) | (?=pattern) |
| 否 | (?<!pattern) | (?!pattern) |
带!的表示非,否则为是。带<的表示左边,否则是右边。
- (?<=abc)d: 匹配一个d,它的左边是abc。能匹配abcd中的d,不能匹配bbcd中的d
- (?<!abc)d: 匹配一个d,它的左边不是abc。能匹配bbcd中的d,不能匹配abcd中的d
- d(?=abc): 匹配一个d,它的右边是abc。能匹配dabc中的d,不能匹配dbcd中的d
- d(?!abc): 匹配一个d,它的右边不是abc。能匹配db中的d,不能匹配dabc中的d
需要注意d(?=abc)右端断言需要写在d的右边,如果写成是(?=abc)d则对d是无效的。a(?=abc)ab此时右端断言是加在了前面的a上,而不是后面的ab上。
注意点: 断言不占用字符。
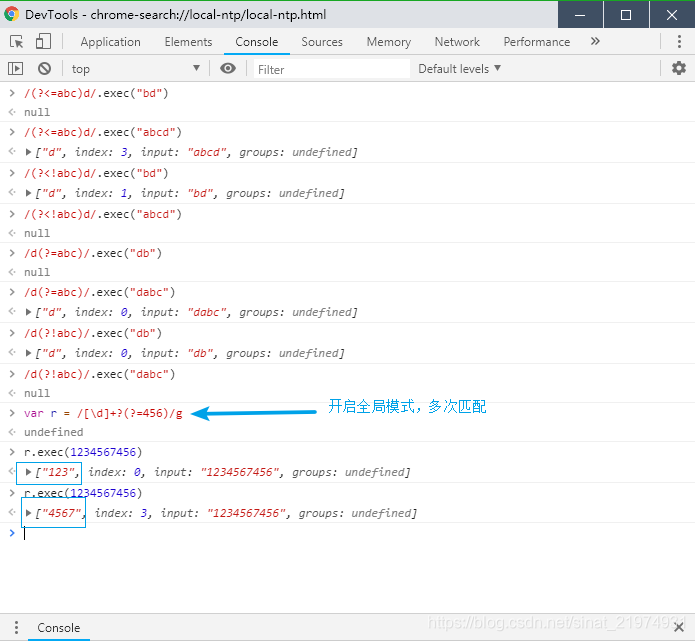
例如:用[\d]+?(?=456)匹配1234567456,第一次匹配到123,第二次是从123后面的456开始匹配,因此结果是4567,而不是跳过456从7开始匹配。测试如图:
除此之外还有一个匹配模式(?:pattern)
这个其实跟普通的()没什么不一样,唯一的区别只是(?:pattern)类型的组不参与分组编号,仅此而已。通常用来忽略不重要的组。如图:
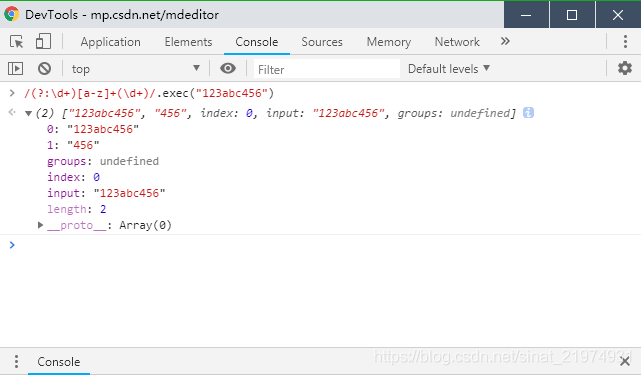
(?:\d+)未参与分组编号,第1组是后面的456
其他
对于在正则表达式中有意义的字符需要使用\进行转义,包括:
- () [] {}
- * + ? .
- ^ $ | \
很有规律的三组字符。
4. 组引用
组引用有两种用法,①用于替换,②用于重复
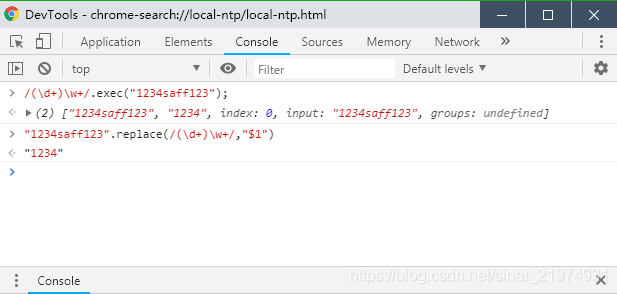
- 把匹配到的字符串替换为指定组的内容。如图:
- 重复
如图所示:
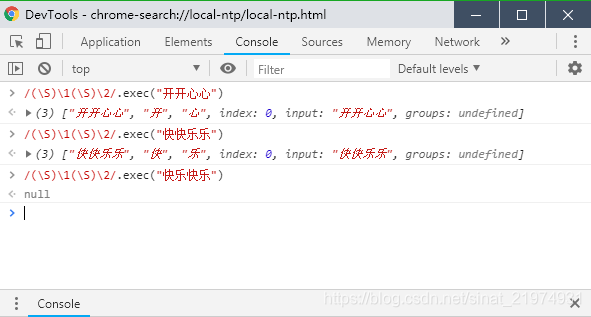
\1引用了前面(\S)匹配到的内容并重复一次。
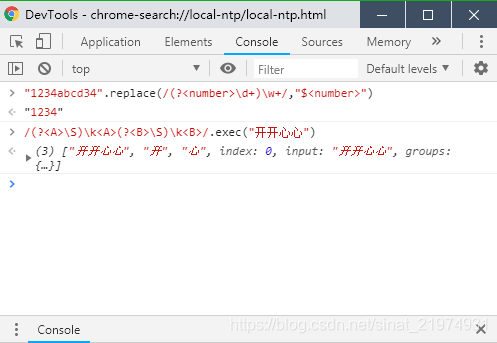
除此以外还有一种命名组的用法,命名组是为了防止括号过多导致查找分组困难的问题。在()内加上?<groupName>,正则表达式内引用使用\k<groupName>,替换时引用使用$<groupName>即可。使用命名组时1,2,3等数字分组依然是生效的。如图:
5. 正则模式g, i, m,s
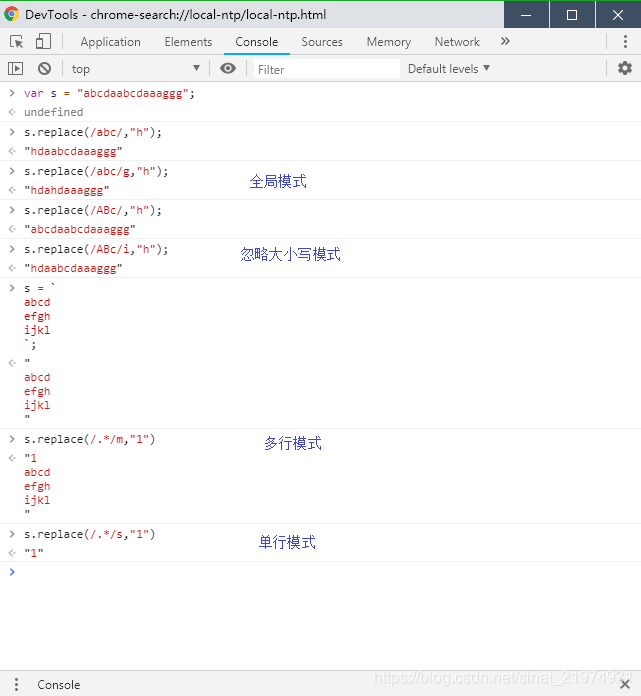
- g 全局模式,开启全局模式后,正则表达式可以从上次结束的地方继续向后查找,而不是每次都从头开始查找。若replace函数使用了全局模式,则相当于replaceAll。(replace默认只替换第一个)
- i 忽略大小写。开启i模式后,a也可以匹配到A
- m 多行模式。默认情况下正则就是多行模式,如果要使用单行模式,加上s标识即可。多行与单行的区别是.号的匹配的内容不同。多行模式下.*只匹配第一行,单行模式下.*匹配整个字符串所有的行。
- s 单行模式。
测试如下:
6. 正则工具使用示例
- 删除entity中的注释
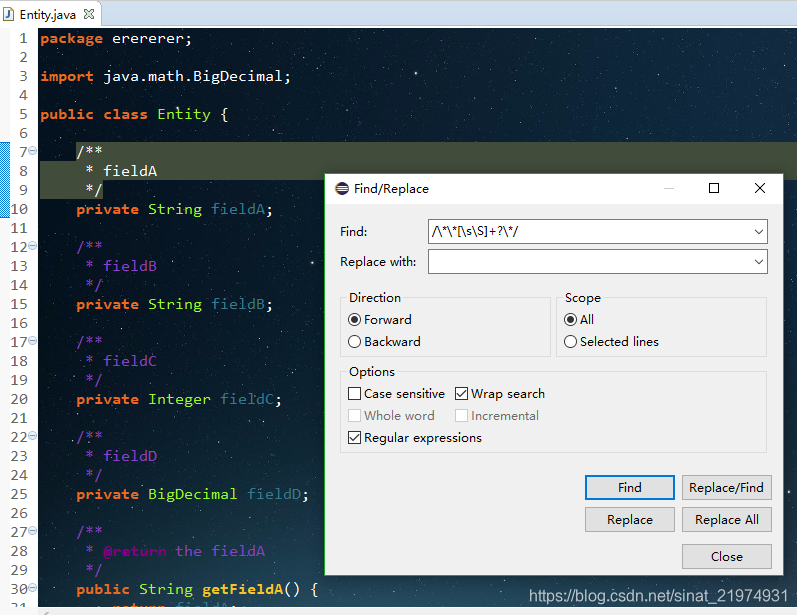
replaceAll即可删除。注意此处关闭了贪婪匹配,如果不关闭贪婪匹配就会是下面这种情况:
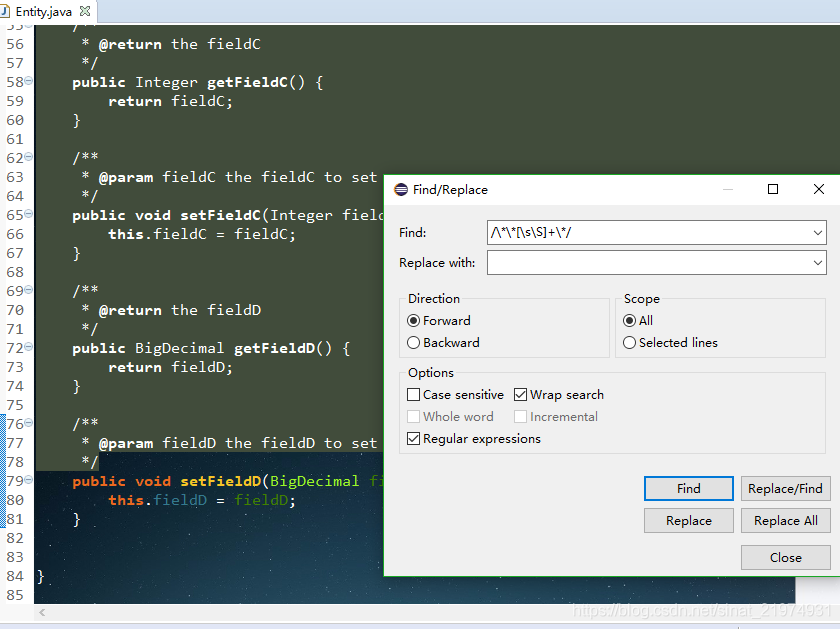
[\s\S]*以最大范围匹配了字符,这显然是不对的。所以可以经常使用[\s\S]*?来最小化匹配范围内的任意内容。 - 提取entity中的field名字
先用1中的方式删除注释,再用如图方式提取field名:
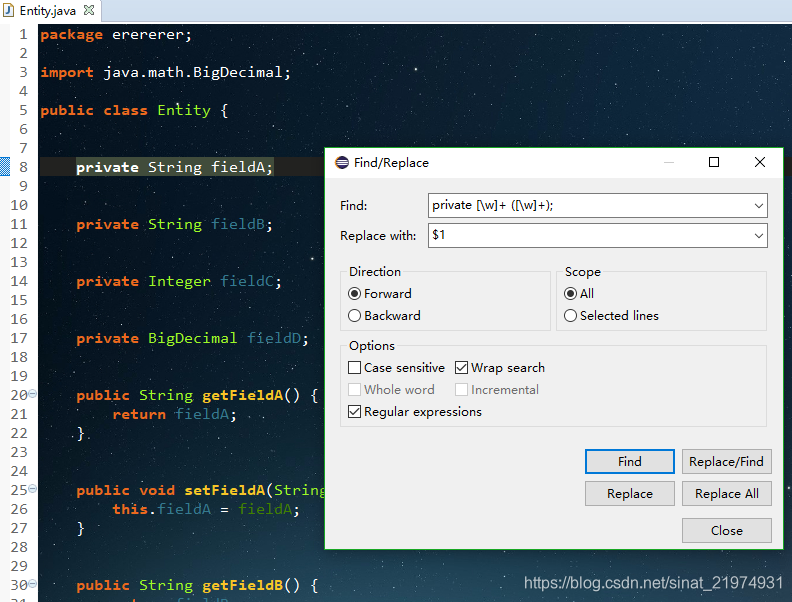
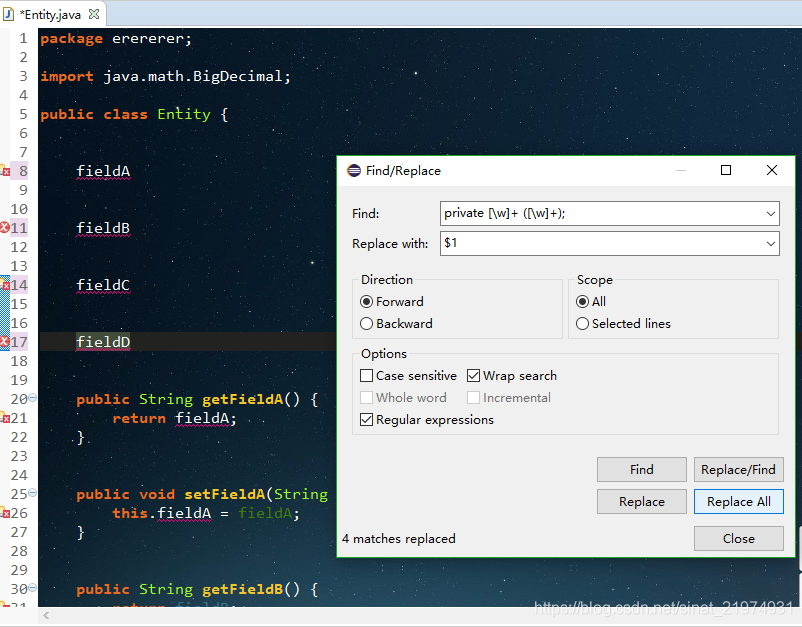
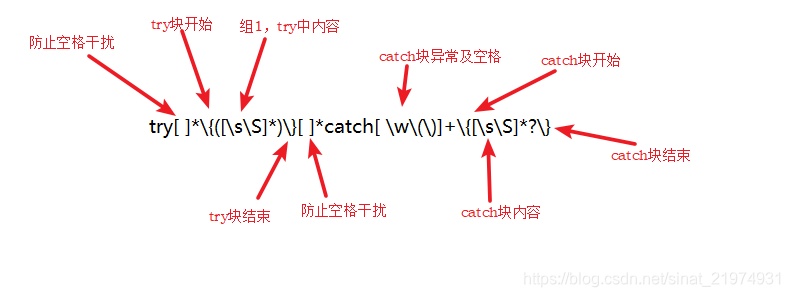
- 删除trycatch语句,提取trycatch中的内容
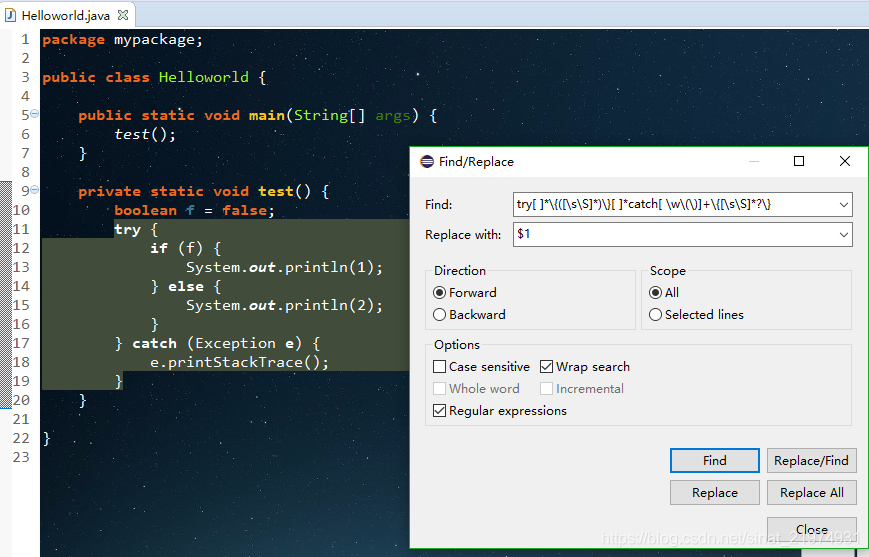
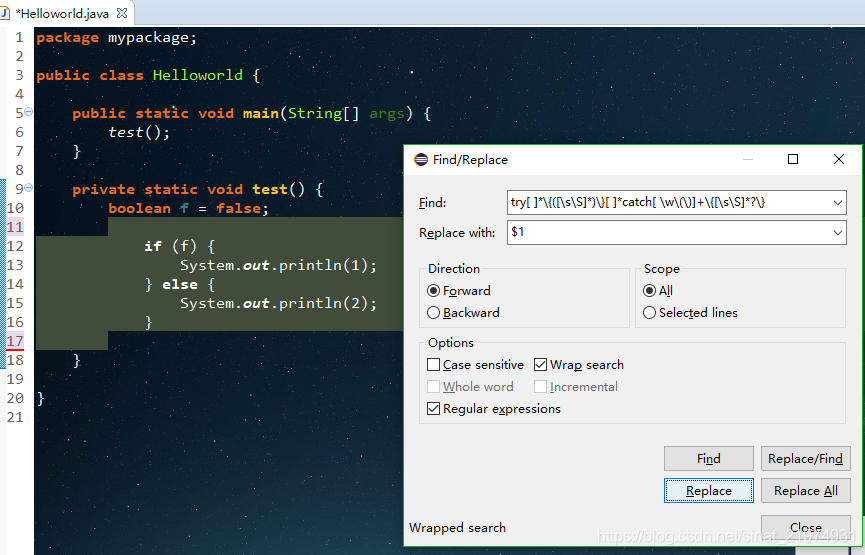
正则解释
7. 正则与性能
进行1000万次获取年月日中的年操作。正则与截取字符串对比:
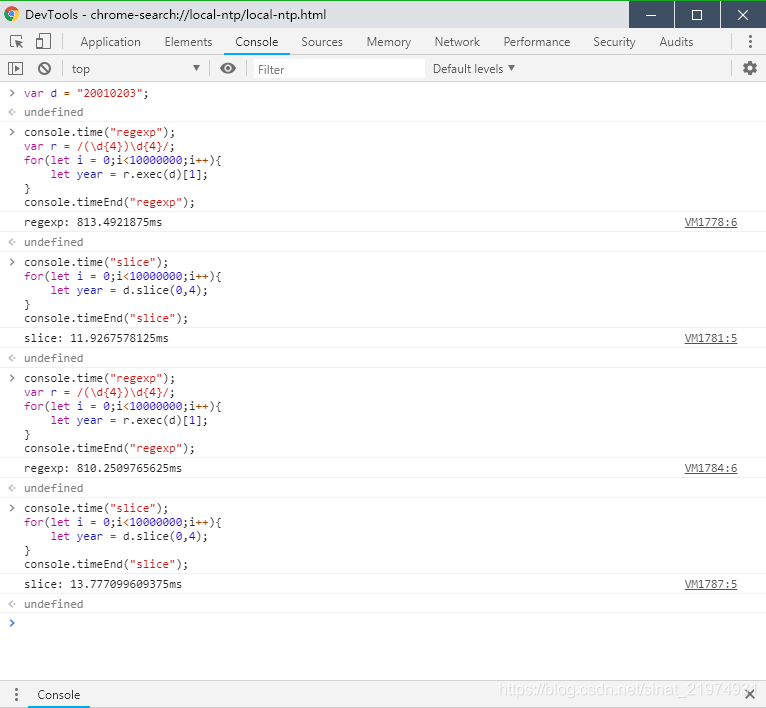
正则需要约810ms,而slice只需要大约12ms。
所以,对于循环中的操作,能用普通字符串函数还是用函数,正则最好在循环外使用。如果不要求性能,那怎么用都可以。
学会了以上的知识,不说100%的情况,至少90%的正则表达式问题都是可以解决的。

















 719
719

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









