



Qwen3 是 Qwen LLM 系列的下一版本,在自然语言处理和多模态能力方面带来了新的突破。在前辈的成功基础上,Qwen3 模型配备了更大的数据集、增强的架构和更优的微调能力,使其能够处理更复杂的推理、语言理解和生成任务。这些模型扩展了令牌限制,确保它们能够生成更长、更连贯的响应,并管理更复杂的对话流程。
Qwen3 代表了 Qwen 系列中最新一代的大型语言模型,提供了丰富的密集模型和专家混合(MoE)模型。基于广泛的训练,Qwen3 在推理、指令遵循、代理能力和多语言支持方面实现了重大突破,具有:
- 支持超过 100 种语言和方言,在多语言指令遵循和翻译方面表现出色。
- 独特的能力,能够在思考模式(用于复杂逻辑推理、数学和编码)和非思考模式(用于高效、通用的对话)之间无缝切换,在各种任务中优化性能。
- 在推理方面取得了显著的提升,在思考模式下超越之前的 QwQ 模型,在非思考模式下超越 Qwen2.5 指令模型,在数学、代码生成和常识逻辑推理方面表现出色。
- 卓越的人类偏好对齐,在创意写作、角色扮演、多轮对话和指令执行方面表现出色,提供更自然、更具吸引力和沉浸感的对话体验。
- 先进的代理能力,能够在思考和非思考模式下与外部工具进行精准交互,在复杂的代理驱动任务中实现了开源模型中的最先进成果。
Qwen3-235B-A22B 在编码、数学、通用能力等多个基准测试中表现出竞争力,位列 DeepSeek-R1、o1、o3-mini、Grok-3 和 Gemini-2.5-Pro 等其他领先模型之列。与此同时,较小的 MoE 模型 Qwen3-30B-A3B,尽管激活参数只有十分之一,但超越了 QwQ-32B。甚至,紧凑的 Qwen3-4B 在性能上也能与更大规模的 Qwen2.5-72B-Instruct 相媲美。
如何使用:
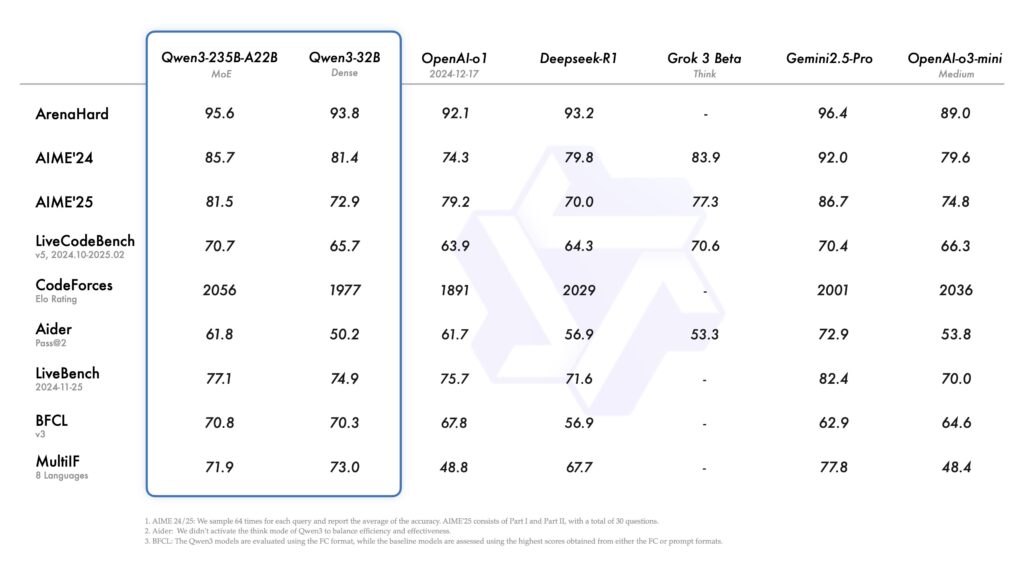
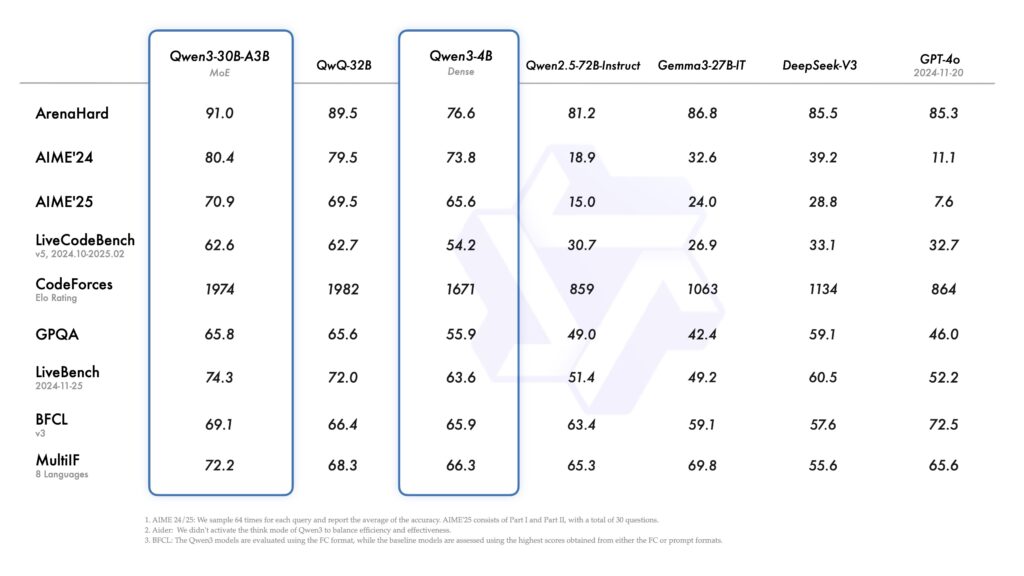
Qwen3-235B-A22B 是一款拥有 2350 亿总参数和 220 亿激活参数的大型模型,而 Qwen3-30B-A3B 是一款具有 300 亿总参数和 30 亿激活参数的较小 MoE 模型,二者均已提供。此外,六款密集模型——Qwen3-32B、Qwen3-14B、Qwen3-8B、Qwen3-4B、Qwen3-1.7B 和 Qwen3-0.6B——均为开源权重,采用 Apache 2.0 许可证发布。
诸如 Qwen3-30B-A3B 及其预训练版本(例如 Qwen3-30B-A3B-Base)等后训练模型,现已在 Hugging Face、ModelScope 和 Kaggle 等平台上提供。对于部署,我们推荐使用 SGLang 和 vLLM 等框架。对于本地使用,强烈推荐 Ollama、LMStudio、MLX、llama.cpp 和 KTransformers 等工具。这些选项使用户能够轻松将 Qwen3 集成到其研究、开发和生产环境中的工作流程中。
我们相信,Qwen3 的发布和开源将推动大型基础模型的研究与开发取得重大进展。我们的使命是赋能全球的研究人员、开发者和组织,利用这些最先进的模型创造创新的解决方案。
您还可以通过 Qwen Chat Web(chat.qwen.ai)和 Qwen 移动应用程序亲身体验 Qwen3!
Key Features 主要特性
Hybrid Thinking Modes 混合思维模式
Qwen3 模型引入了一种混合解决问题的方法,支持两种不同的模式:
- 思考模式:在此模式下,模型会逐步推理后再给出答案,适合需要深入分析的复杂问题。
- 非思考模式:此模式提供快速、几乎即时的响应,适用于优先考虑速度而非详细推理的简单任务。
这种灵活性允许用户根据具体任务调整模型应用的“思考”程度。复杂的挑战可以通过延伸推理来应对,而简单的查询可以立即处理。
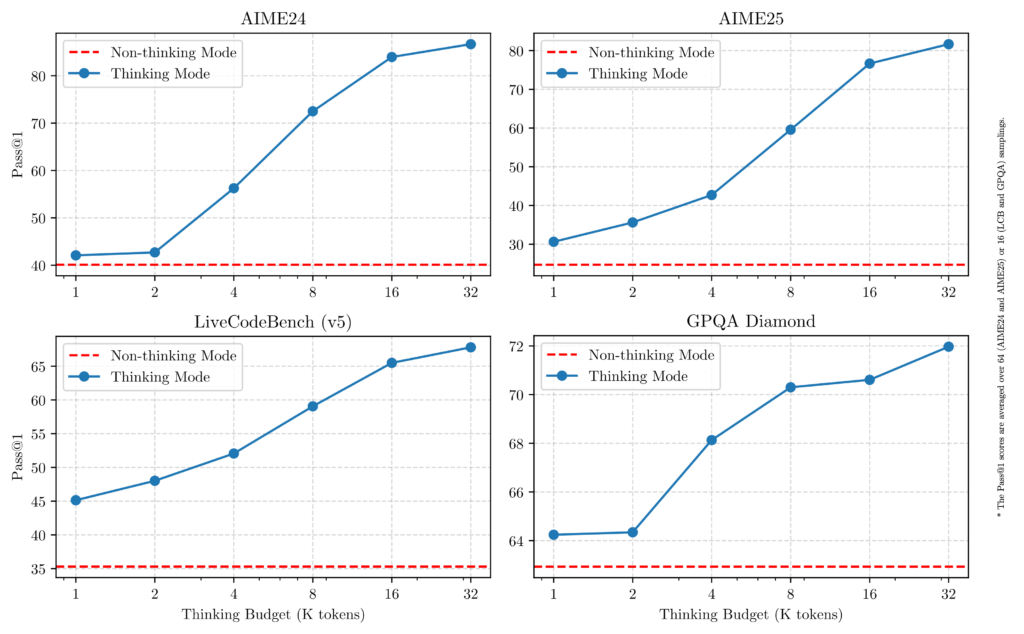
重要的是,这两种模式的集成显著提高了模型高效管理思维预算的能力。如所示,Qwen3 展现出与分配的计算推理预算直接相关的可扩展且平稳的性能提升。这一设计使用户更容易配置任务特定的预算,优化成本效率与推理质量之间的平衡。
Multilingual Support 多语言支持
Qwen3 模型支持 119 种语言和方言,极大地扩展了其在全球应用中的实用性。这种广泛的多语言能力使全球用户能够在不同的语言和文化背景下充分发挥 Qwen3 的潜力。
语言家族和覆盖范围:**
| Language Family 语言家族 | Languages & Dialects 语言与方言 |
|---|---|
| Indo-European 印欧语系 | English, French, Portuguese, German, Romanian, Swedish, Danish, Bulgarian, Russian, Czech, Greek, Ukrainian, Spanish, Dutch, Slovak, Croatian, Polish, Lithuanian, Norwegian Bokmål, Norwegian Nynorsk, Persian, Slovenian, Gujarati, Latvian, Italian, Occitan, Nepali, Marathi, Belarusian, Serbian, Luxembourgish, Venetian, Assamese, Welsh, Silesian, Asturian, Chhattisgarhi, Awadhi, Maithili, Bhojpuri, Sindhi, Irish, Faroese, Hindi, Punjabi, Bengali, Oriya, Tajik, Eastern Yiddish, Lombard, Ligurian, Sicilian, Friulian, Sardinian, Galician, Catalan, Icelandic, Tosk Albanian, Limburgish, Dari, Afrikaans, Macedonian, Sinhala, Urdu, Magahi, Bosnian, Armenian 英语、法语、葡萄牙语、德语、罗马尼亚语、瑞典语、丹麦语、保加利亚语、俄语、捷克语、希腊语、乌克兰语、西班牙语、荷兰语、斯洛伐克语、克罗地亚语、波兰语、立陶宛语、挪威布克莫尔语、挪威尼诺斯克语、波斯语、斯洛文尼亚语、古吉拉特语、拉脱维亚语、意大利语、奥克语、尼泊尔语、马拉地语、白俄罗斯语、塞尔维亚语、卢森堡语、威尼斯语、阿萨姆语、威尔士语、锡列西亚语、阿斯图里亚斯语、恰蒂斯加尔语、阿瓦迪语、迈蒂利语、博杰普尔语、信德语、爱尔兰语、法罗语、印地语、旁遮普语、孟加拉语、奥里亚语、塔吉克语、东意第绪语、伦巴第语、利古里亚语、西西里语、弗留利语、撒丁语、加利西亚语、加泰罗尼亚语、冰岛语、托斯克阿尔巴尼亚语、林堡语、达里语、南非荷兰语、马其顿语、僧伽罗语、乌尔都语、马加希语、波斯尼亚语、亚美尼亚语 |
| Sino-Tibetan 汉藏语系 | Chinese (Simplified, Traditional, Cantonese), Burmese 中文(简体、繁体、粤语)、缅甸语 |
| Afro-Asiatic 亚非语系 | Arabic (Standard, Najdi, Levantine, Egyptian, Moroccan, Mesopotamian, Ta’izzi-Adeni, Tunisian), Hebrew, Maltese 阿拉伯语(标准阿拉伯语、纳吉迪语、黎凡特语、埃及语、摩洛哥语、两河流域语、塔伊兹-阿登语、突尼斯语)、希伯来语、马耳他语 |
| Austronesian 南岛语系 | Indonesian, Malay, Tagalog, Cebuano, Javanese, Sundanese, Minangkabau, Balinese, Banjar, Pangasinan, Iloko, Waray (Philippines) 印尼语、马来语、他加禄语、宿务语、爪哇语、巽他语、闽南语、巴厘语、班贾尔语、邦阿斯宁语、伊洛克语、Waray(菲律宾) |
| Dravidian 达罗毗荼语系 | Tamil, Telugu, Kannada, Malayalam 泰米尔语、泰卢固语、卡纳达语、马拉雅拉姆语 |
| Turkic 突厥语系 | Turkish, North Azerbaijani, Northern Uzbek, Kazakh, Bashkir, Tatar 土耳其语、北阿塞拜疆语、北乌兹别克语、哈萨克语、巴什基尔语、鞑靼语 |
| Tai-Kadai 泰-卡达语 | Thai, Lao 泰语、老挝语 |
| Uralic 乌拉尔语 | Finnish, Estonian, Hungarian 芬兰语、爱沙尼亚语、匈牙利语 |
| Austroasiatic 南亚语系 | Vietnamese, Khmer 越南语、高棉语 |
| Other 其他 | Japanese, Korean, Georgian, Basque, Haitian, Papiamento, Kabuverdianu, Tok Pisin, Swahili 日语、韩语、格鲁吉亚语、巴斯克语、海地克里奥尔语、帕皮阿门托语、卡布韦尔迪亚努语、托克皮辛语、斯瓦希里语 |
Improved Agentic Capabilities提升的自主能力
Qwen3 模型在编码和代理驱动任务方面已得到显著优化。此外,对 MCP(多上下文处理)的支持也得到了进一步加强。
以下,我们提供示例,展示 Qwen3 模型如何推理、与环境互动以及在复杂的代理工作流程中表现。
你是否还希望我根据你的用途,将其稍作润色,变成更偏“市场推广”风格或更偏“技术文档”风格?
Pre-training 预训练
对于 Qwen3,预训练数据集相比 Qwen2.5 有了显著扩展。虽然 Qwen2.5 的训练数据为 18 万亿个标记,但 Qwen3 几乎是其两倍,约为 36 万亿个标记,涵盖 119 种语言和方言。
为了构建这个大规模的数据集,我们不仅从网络获取数据,还从类似 PDF 的文档中获取。文档中的文本提取使用了 Qwen2.5-VL,而 Qwen2.5 则用于提升提取内容的质量。为了丰富数据集中的数学和编码示例,还使用 Qwen2.5-Math 和 Qwen2.5-Coder 生成了合成数据,包括教科书、问答对和代码片段。
预训练过程分为三个阶段:
- 阶段一(S1):模型在超过 30 万亿个标记上进行了预训练,具有 4K 标记的上下文长度,建立了坚实的基础语言技能和通用知识。
- 阶段二(S2):通过增加知识密集型内容的比例(如 STEM 主题、编码挑战和推理任务)对数据集进行了进一步优化。然后,模型在额外的 5 万亿个标记上进行了预训练。
- 最终阶段:采用高质量、长上下文数据,将模型的上下文窗口扩展到 32K 标记,确保其能够有效处理更长的输入。
由于模型架构的改进、扩展的训练数据以及更高效的训练技术,Qwen3 密集基础模型现在的性能与——在某些情况下甚至超过——更大规模的 Qwen2.5 基础模型相匹配。
例如,Qwen3-1.7B/4B/8B/14B/32B-基础模型在性能上与 Qwen2.5-3B/7B/14B/32B/72B-基础模型相当。特别是,Qwen3 密集基础模型在 STEM、编码和推理任务中显示出显著优势。
同时,Qwen3-MoE 基础模型在参数使用仅为 10%的情况下,达到了与 Qwen2.5 密集模型相当的性能——在训练和推理成本方面都实现了显著节省。
Post-training 训练后
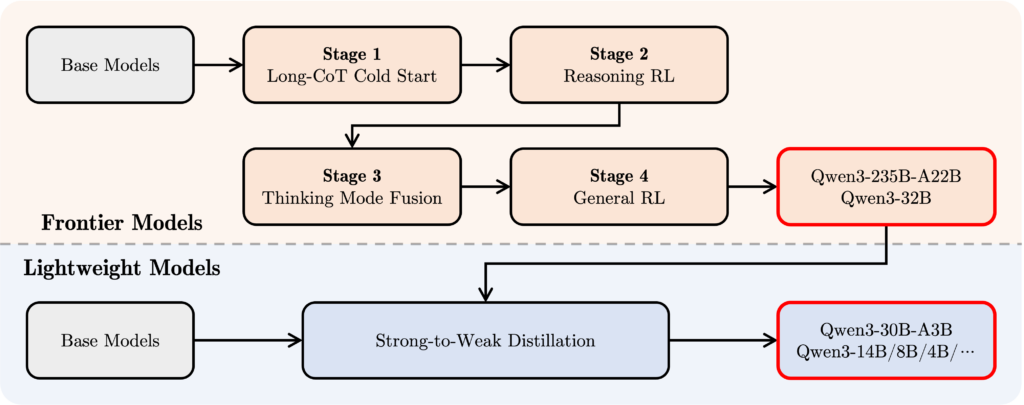
Hybrid Model Training Pipeline混合模型训练流程
为了开发一种既能进行逐步推理又能快速响应的混合模型,阿里巴巴开发团队设计了一个四阶段的训练流程:
- 长链式思维(CoT)冷启动:在这个初始阶段,模型在各种长链式思维数据集上进行了微调,涵盖数学、编码、逻辑推理和 STEM 挑战等任务。这一训练奠定了模型的基础推理能力。
- 基于推理的强化学习(RL):第二阶段专注于通过扩大计算资源和在强化学习中应用基于规则的奖励机制,提升模型的探索和利用能力。
- 思维模式融合:在这个阶段,将非思维(快速响应)能力融入推理模型。通过在长链式思维数据和由第二阶段增强模型生成的标准指令调优数据集上微调,实现了深度推理与快速响应模式的无缝切换。
- 通用强化学习(General RL):最终,强化学习被应用到 20 多个通用领域任务中,进一步提升了模型的整体能力并减轻了不良行为。这些任务包括指令执行、格式遵守、代理行为等。
- 原文: https://qwen3.org/
- 一键接入全球顶尖模型:https://aihubmax.com/


















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









