







HashMap能干什么?HashMap底层数据结构?
数据结构:HashMap 是一个散列表(Hash table,也叫哈希表),它存储的内容是键值对(key-value)映射。
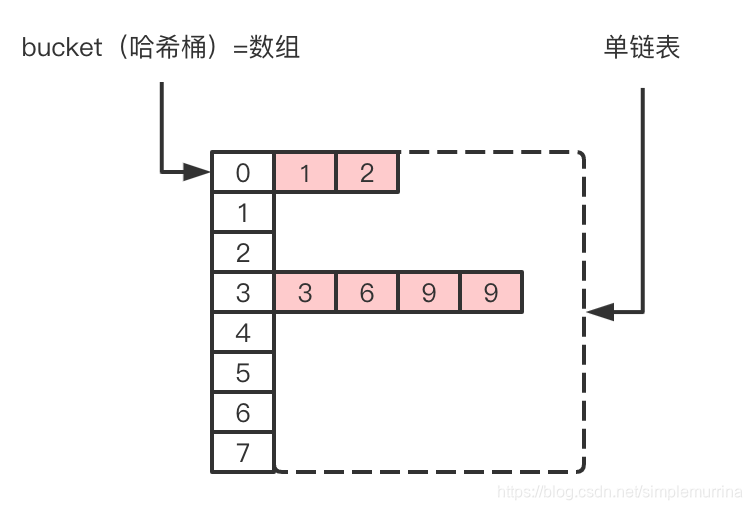
底层技术:采用数组+链表实现。
put(key,value)方法向Map中添加元素
int index=hash(key);//数组下标计算,采用Hash算法。此时可能由于hash碰撞💥,导致数据分布不均匀,通常我们称之为数据倾斜。
拉链法解决冲突的做法是:将所有关键字为同义词的结点链接在同一个单链表中。
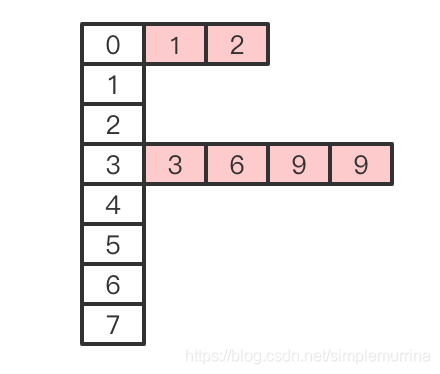
在解释下,Java中HashMap是利用“拉链法”处理HashCode的碰撞问题。
在调用HashMap的put方法或get方法时,都会首先调用hashcode方法,去查找相关的key,当有冲突时,再调用equals方法。
hashMap基于hasing原理,我们通过put和get方法存取对象。
Hash算法和扩容机制?
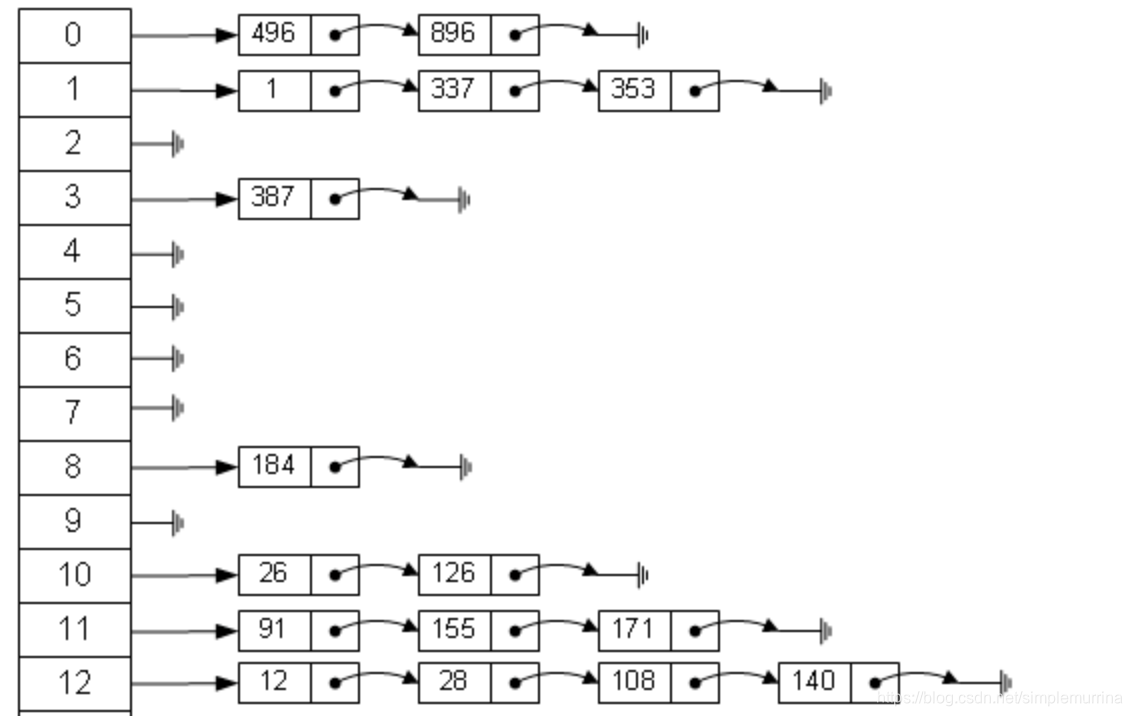
面试中常会问什么时候HashMap进行扩容?并且描述扩容过程中数据是如何迁移的?
HashMap 的实例有两个参数影响其性能:“初始容量” 和 “加载因子”。容量 是哈希表中桶的数量,初始容量 只是哈希表在创建时的容量。加载因子 是哈希表在其容量自动增加之前可以达到多满的一种尺度。当哈希表中的条目数超出了加载因子与当前容量的乘积时,并且要存放的位置已经有元素了(hash碰撞),必须满足这两个条件,才要对该哈希表进行 rehash 操作,会将容量扩大为原来两倍。通常,默认加载因子是 0.75, 这是在时间和空间成本上寻求一种折衷。加载因子过高虽然减少了空间开销,但同时也增加了查询成本。
一步一步看。
- 再Hash手段防止Hash冲突频率
- 扩容2次幂:为了提高性能,大量的二进制计算&
红黑树在HashMap中如何体现?
引入红黑树是为了提高HashMap的查询效率。假设一种情况:当HashMap中的碰撞越来越多,链表越来越长的时候,其获取单个元素所需要的时间就会越来越高(因为链表的查询速度比较慢)。为了解决这个问题jdk1.8引入了红黑树。因为红黑树的查询速度比链表要高很多。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











