



 Redis是一个高性能的内存数据库,提供多种数据结构如string、list、hash等。其单线程模型通过I/O多路复用实现高效网络通信。过期机制包括惰性删除和定期删除,内存淘汰策略有LRU、TTL等。Redis的持久化包括快照和AOF,确保数据安全。此外,还介绍了缓存穿透的解决方案,如布隆过滤器,以及缓存雪崩的应对措施。Redis支持主从复制和哨兵机制,保证高可用性。
Redis是一个高性能的内存数据库,提供多种数据结构如string、list、hash等。其单线程模型通过I/O多路复用实现高效网络通信。过期机制包括惰性删除和定期删除,内存淘汰策略有LRU、TTL等。Redis的持久化包括快照和AOF,确保数据安全。此外,还介绍了缓存穿透的解决方案,如布隆过滤器,以及缓存雪崩的应对措施。Redis支持主从复制和哨兵机制,保证高可用性。
简介
Redis是一个使用C语言开发的数据库,数据存在内存中,读写非常快,被广泛应用于缓存、分布式锁甚至消息队列。
数据结构
string
既可保存文本,也可保存二进制,不会造成缓冲区溢出。
适合需要计数的场景,如访问次数、点赞量等。
list
双向链表。

适合消息队列场景。
hash
类似JDK1.8前的HashMap,维护一个string类型的field和value的映射表。
特别适合存储对象数据
set
类似HashSet,无序集合。
适合需要存储不能重复的数据以及需要获取交集、并集、差集的场景(如共同关注)。
sorted set
在set基础上增加了一个权重参数score,以此进行有序排列。
适合需要排序的场景,如礼物排行榜。
bitmap
存储二进制数字,使用一个bit位表示某个值或状态。
适合需要保存状态信息的场景,如是否签到、是否点赞等。
Redis单线程模型
Redis 基于 Reactor 模式开发了自己的文件事件处理器(file event handler):使用 I/O 多路复用程序来同时监听多个socket,并根据socket当前任务关联不同的事件处理器。虽然文件事件处理器以单线程方式运行,但通过使用 I/O 多路复用程序来监听多个套接字,文件事件处理器既实现了高性能的网络通信模型,又可以很好地与 Redis 服务器中其他同样以单线程方式运行的模块进行对接,这保持了 Redis 内部单线程设计的简单性。
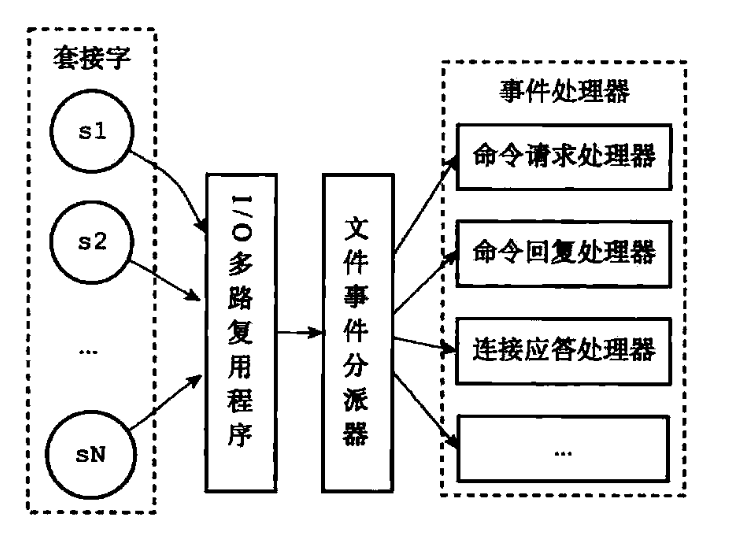
Redis6.0引入多线程,主要为了提高网络IO读写性能。(Redis 的性能瓶颈不在 CPU ,主要在内存和网络)
过期机制
因为内存有限,所以Redis自带给缓存数据设置过期时间的功能。
通过维护一个过期字典(可视为hash表)来实现,字典的键指向Redis的key,字典的值(long long类型的整数)保存该key的过期时间。
过期数据的删除策略:
- 惰性删除:只在取出key时才进行过期检查。对CPU友好,但内存可能存在大量过期key
- 定期删除:每隔一段时间抽取一批key执行过期删除操作。Redis底层通过限制删除操作的执行时长和频率来减少对CPU的影响。
内存淘汰机制
Redis提供的数据淘汰策略:
- volatile-lru(least recently used):从已设置过期时间的数据集中挑选最近最少使用的数据淘汰
- volatile-ttl:从已设置过期时间的数据集中挑选将要过期的数据淘汰
- volatile-random:从已设置过期时间的数据集中任意选择数据淘汰
- allkeys-lru(least recently used):当内存不足以容纳新写入数据时,在键空间中,移除最近最少使用的 key(最常用)
- allkeys-random:从数据集中任意选择数据淘汰
- no-eviction:禁止驱逐数据,也就是说当内存不足以容纳新写入数据时,新写入操作会报错。(这个应该没人使用吧! )
4.0 版本后增加以下两种:
- volatile-lfu(least frequently used):从已设置过期时间的数据集中挑选最不经常使用的数据淘汰
- allkeys-lfu(least frequently used):当内存不足以容纳新写入数据时,在键空间中,移除最不经常使用的 key
持久化机制
Redis支持两种持久化操作:
快照持久化
通过创建快照来获得内存数据在某个时间点上的副本,从而用于主从复制或重启时还原。Redis默认持久化方式。
只追加文件(append-only file)持久化
AOF持久化的实时性比快照更好,可通过appendonly yes参数开启。
开启后,每执行一条更改数据的命令,Redis就会将该命令写入到内存缓存server.aof_buf中,然后根据appendfsync配置来决定何时将其同步到硬盘中的AOF文件appendonly.aof。
- appendfsync always
每次有数据修改发生时都会写入AOF文件,这样会严重降低Redis的速度。 - appendfsync everysec
每秒钟同步一次,显示地将多个写命令同步到硬盘。(最常用) - appendfsync no
让操作系统决定何时进行同步。
缓存穿透
问题描述:大量请求的 key 不存在于缓存中,导致请求直接到了数据库上,根本没有经过缓存这一层。
解决办法:
- 缓存无效key
对于数据库都查不到的key,添加到Redis中并设置过期时间。
只能解决请求的key变化不频繁的情况。 - 布隆过滤器
把所有可能存在的请求的值都存放在布隆过滤器中,当用户请求过来,先判断用户发来的请求的值是否存在于布隆过滤器中。不存在的话,直接返回请求参数错误信息给客户端,存在的话才进行缓存和数据库的查询流程。
https://github.com/Snailclimb/JavaGuide/blob/master/docs/cs-basics/data-structure/bloom-filter.md
缓存雪崩
问题描述:缓存在同一时间大面积的失效,后面的请求都直接落到了数据库上,造成数据库短时间内承受大量请求。
解决办法:
- 采用Redis集群,避免单机出现问题导致整个缓存服务都失效
- 限流,避免同时处理海量请求
- 设置不同的过期时间(如随机时间或永不失效)
读写策略
旁路缓存模式(Cache Aside Pattern)
- 读
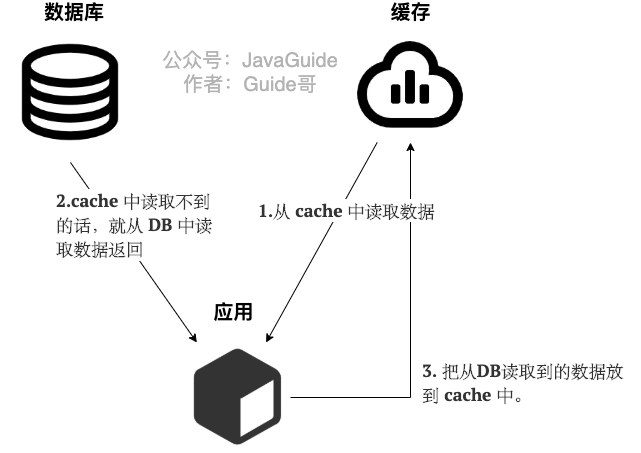
- 写
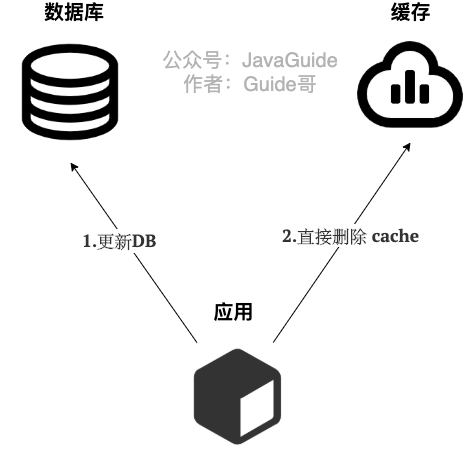
不能先删cache再写DB,因为缓存的写入速度远快于数据库,可以尽量避免数据不一致的问题。 - 缺陷
1.首次请求的数据一定不在缓存
解决:提前将热点数据放入缓存
2.写操作频繁会导致缓存频繁被删除,影响命中率
解决:更新DB同时更新cache ①需保证强一致性的场景,更新cache时要加锁 ②允许短暂不一致的场景,更新cache时设置一个较短的过期时间
读写穿透模式(Read/Write Through Pattern)
-
读
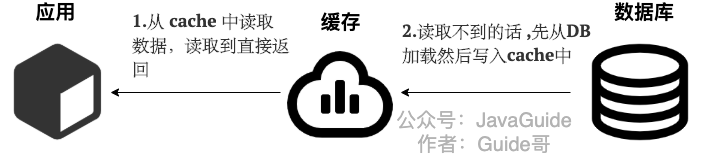
从DB加载这一工作由应用端交给缓存服务 -
写
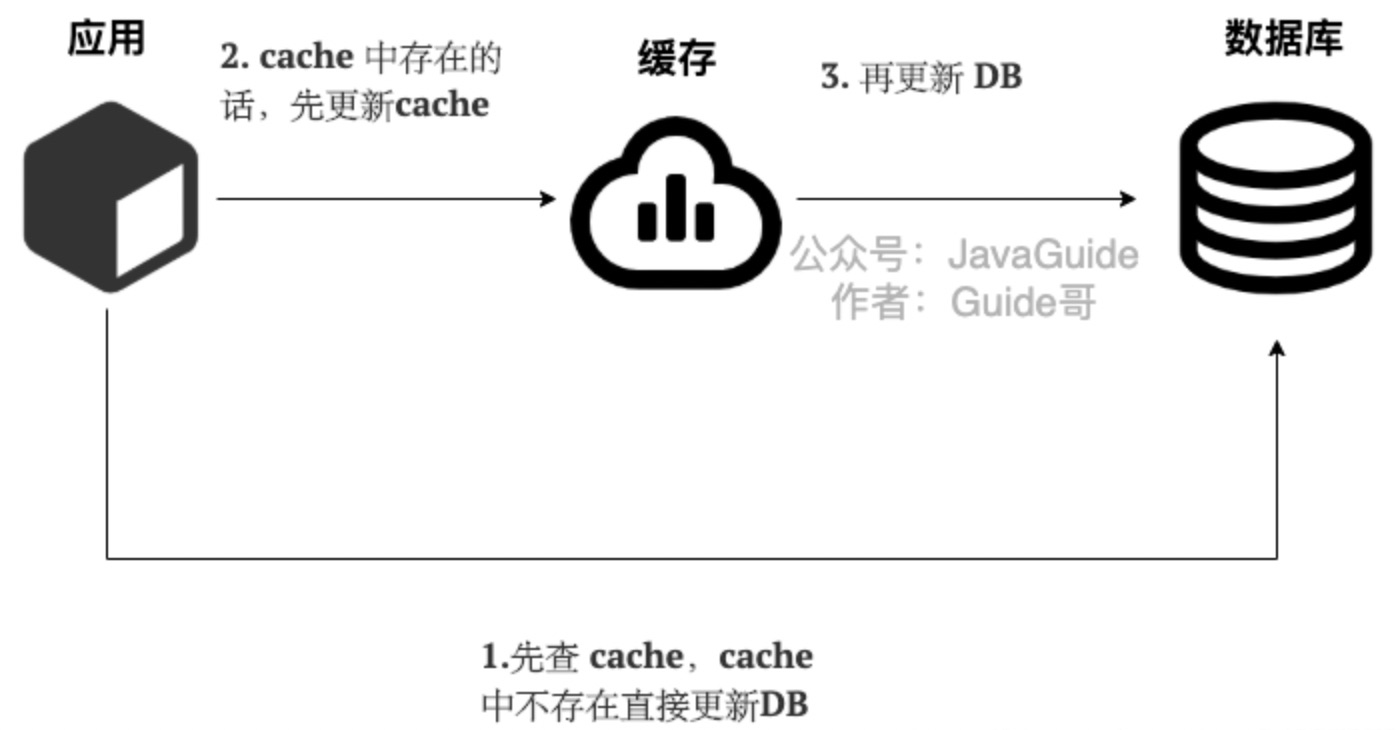
由缓存服务写入数据库(Redis不支持)
异步缓存写入模式(Write Behind Pattern)
类似读写穿透模式,由cache服务来负责缓存和数据库的读写。但读写穿透同步更新缓存和数据库,而异步缓存写入只更新缓存, 通过异步批量的方式更新数据库。
消息队列中消息的异步写入磁盘、MySQL 的 InnoDB Buffer Pool 机制都用到了这种策略,适合数据变化频繁但对一致性要求不高的场景(浏览量、点赞量)。
主从复制
- 复制初始化
从库发起请求,主库推送快照,从库写入磁盘 - 复制同步
每当主库收到写命令就同步给从库 - 增量复制
主从断开再连接时,不再初始化而是增量复制
哨兵机制
Redis主从复制中,主库为了性能一般禁用持久化,由从库做数据备份。
所以从库崩溃,直接重启即可;而主库崩库,直接重启会丢失数据,需将一个从库升为主库,然后将原主库设为从库。手动处理崩溃麻烦且易错,Redis提供哨兵机制来自动操作。
哨兵的功能:
1.监控主从库是否正常运行;
2.主库故障时自动将主库转为从库;
Redis集群
主从复制中,每个节点都保存全量数据,因此最大存储容量受限于内存最小的节点,形成木桶效应。
旧版Redis使用客户端分片,即客户端决定每个key交由哪个节点来存储。缺点是增删节点时需下线再手动迁移数据。
redis3.0开始支持集群,特点如下
- 拥有和单机实例同样的性能;
- 在网络分区后提供一定的可访问性以及对主库故障恢复的支持;
- redis集群并不支持处理多个key的命令(如mget),这是因为在不同的节点间移动数据会达不到像单机redis那样的性能,在高负载的情况下可能会导致不可预料的错误;
- 只能使用0号数据库,如果用select切换则报错;
- 支持数据分片和主从复制;

















 173万+
173万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









