




 本文介绍了数据挖掘中的频繁模式挖掘基础,包括项、事务、事务数据库、项集等概念,以及支持度和关联规则的定义。接着详细探讨了Apriori算法,解释了如何生成频繁项集,分析了Apriori的主要挑战及解决方案。最后,提到了频繁图挖掘的相关内容,如频繁子图挖掘和类Apriori算法。
本文介绍了数据挖掘中的频繁模式挖掘基础,包括项、事务、事务数据库、项集等概念,以及支持度和关联规则的定义。接着详细探讨了Apriori算法,解释了如何生成频繁项集,分析了Apriori的主要挑战及解决方案。最后,提到了频繁图挖掘的相关内容,如频繁子图挖掘和类Apriori算法。
一、基本概念
频繁模式
– 频繁的出现在数据集中的模式– 项集、子序或者子结构
动机
– 发现数据中蕴含的事物的内在规律• 项(Item)
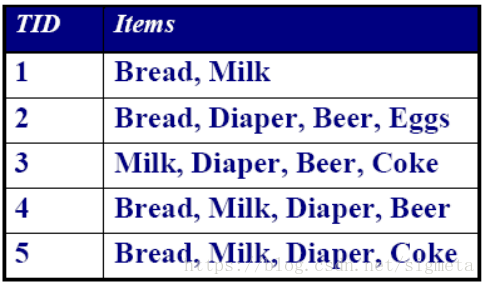
– 最小的处理单位 – 例如:Bread, Milk
• 事务(Transaction)
– 由事务号和项集组成 – 例如:<1, {Bread,Milk}>
• 事务数据库
– 由多个事务组成
• 项集(Itemset)
– 一个或多个项(item) 的集• 例如:{Milk, Bread, Diaper}
– k-项集(k-itemset)
• 包含k个项的集合
• 包含关系
– 令T为一事务,P为一项集,如果P是T的子集,称T包含P ,记T⊇P或P⊆T• 例如{Milk, Bread, Diaper} ⊆T4
• 关联规则(Association Rule)
– 项的集合:I={i1,i2,...,in}– 任务相关数据D是数据库事务的集合,每个事务T则是项的集合,使得T ⊆ I
– 每个事务由事务标识符TID标识;
– A,B为两个项集,事务T包含A当且仅当A ⊆ T
– 则关联规则是如下蕴涵式:
• A →B (s, c)
• 其中,A和B 都是项集,s是规则的支持度,c是置信度
• 支持度计数(Support count)
– 事务数据库中包含某个项集的事务的个数
– 例如:σ({Milk, Bread,Diaper}) = 2
• 支持度(Support)
– 事务数据库中包含某个项集的事务占事务总数的比例。
支持度s是指事务集D中包含A ∪ B的百分比
support(A ⇒ B) = P(A ∪ B)
置信度c是指D中包含A的事务同时也包含B的百分比
confidence (A ⇒ B) = P(B | A) = P(A ∪ B)/ P(A)• 关联规则挖掘目的
– 给定一个事务数据库TD,关联规则挖掘的目标是要找到所有支持度和置信度都不小于指定阈值的规则。• 支持度≥minsup
• 置信度≥minconf
• 关联规则步骤:
– 1、找个这个“同一项集”,相同的项集对应的规则有相同的支持度,找到支持度≥minsup的项集– 2、计算项集中所有规则的置信度,找到置信度≥minconf的规则
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1678
1678

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









