







 该博客通过Word2Vec模型对五部武侠小说的人物和门派进行词向量训练,然后进行聚类分析。结果显示聚类结果与小说内容相吻合,但也存在一些无关词语,提示未来可优化停用词表以提升聚类效果。
该博客通过Word2Vec模型对五部武侠小说的人物和门派进行词向量训练,然后进行聚类分析。结果显示聚类结果与小说内容相吻合,但也存在一些无关词语,提示未来可优化停用词表以提升聚类效果。
文章目录
问题提出
利用Word2Vec模型训练Word Embedding,根据小说中人物、武功、派别或者其他你感兴趣的特征,基于Word Embedding来进行聚类分析。
一、Word2Vec模型简介
传统的自然语言处理将词看作是一个个孤立的符号,这样的处理方式对于系统处理不同的词语没有提供有用的信息。词映射(word embedding)实现了将一个不可量化的单词映射到一个实数向量。Word embedding能够表示出文档中单词的语义和与其他单词的相似性等关系。它已经被广泛应用在了推荐系统和文本分类中。Word2Vec模型则是Word embedding中广泛应用的模型。Word2Vec使用一层神经网络将one-hot(独热编码)形式的词向量映射到分布式形式的词向量。使用了Hierarchical softmax,negative sampling等技巧进行训练速度上的优化。
二、模型原理
1.词的独热表示-One-hot
最简单的也最容易想到的词表示方法是 One-hot Representation,这种方法把每个词表示为一个很长的向量。这个向量的维度是词表大小,其中绝大多数元素为 0,只有一个维度的值为 1,这个向量就代表了当前的词。
“可爱”表示为 [0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 …]
“面包”表示为 [0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 …]
每个词都是茫茫 0 海中的一个 1。这种 One-hot Representation 如果采用稀疏方式存储,会是非常的简洁:也就是给每个词分配一个数字 ID。比如刚才的例子中,可爱记为 3,面包记为 8(假设从 0 开始记)。
这样的表示带来两点问题:
1、向量的维度会随着句子的词的数量类型增大而增大,容易导致维度灾难;
2、任意两个词之间都是孤立的,无法表示语义层面上词汇之间的相关信息,而这一点是致命的。
2.词的分布式表示
传统的独热表示仅仅将词符号化,不包含任何语义信息。如何将语义融入到词表示中?Harris 在 1954 年提出的“分布假说”为这一设想提供了理论基础:上下文相似的词,其语义也相似。Firth 在 1957年对分布假说进行了进一步阐述和明确:词的语义由其上下文决定。
Word Embedding正是这样的模型,而Word2Vec则是其中的一个典型,Word2Vec包含两种模型,即CBOW模型和Skip-gram模型。
以CBOW模型为例,如果有一个句子“the cat sits one the mat”,在训练的时候,将“the cat sits one the”作为输入,预测出最后一个词是“mat”。
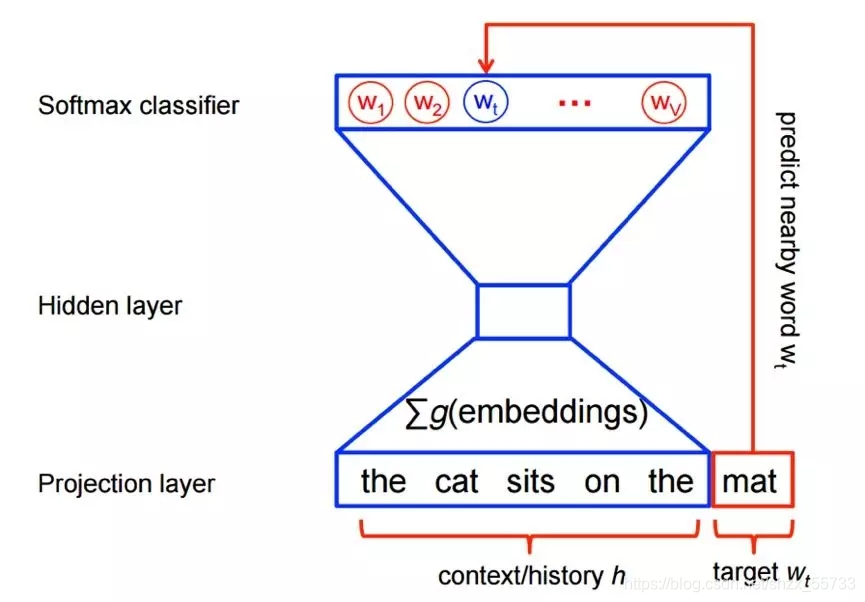
我们将上下文单词输入时,可能会遇到多种上下文的形式,所以,情况可能会为下图所示:
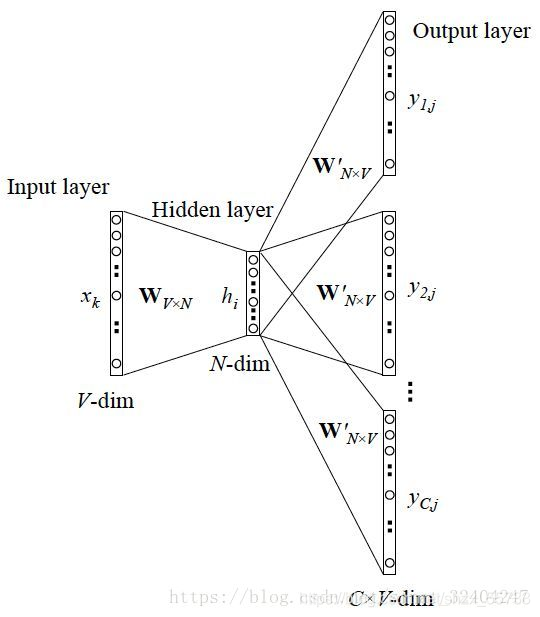
即多种情况对应同一个单词的预测输出。
Skip-Gram model则是通过目标单词推测语境,在大规模的数据集中Skip-Gram model训练速度快。Skip-Gram 的训练流程如下图所示:
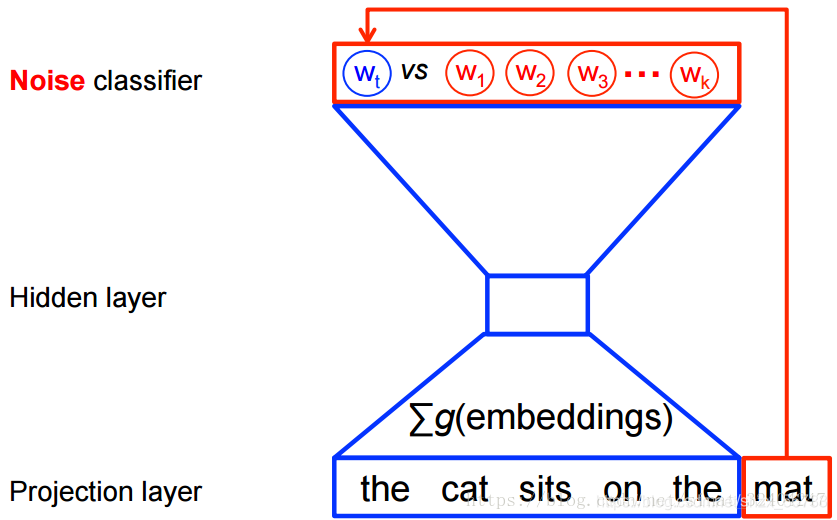
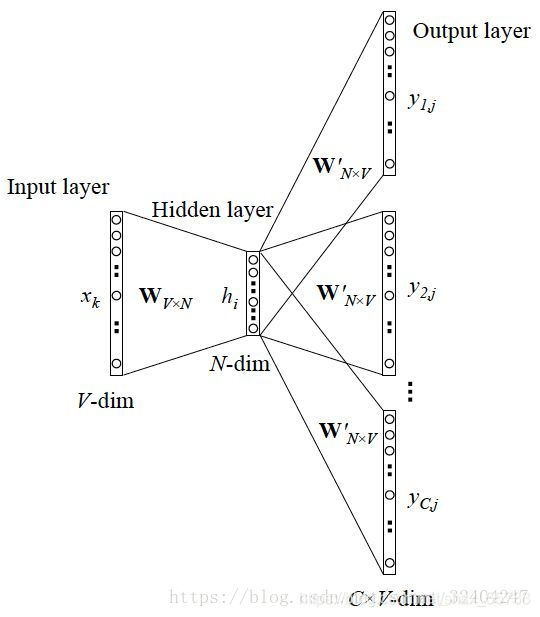
同样的,Skip-Gram也有更一般的情形,也就是再输入一个目标单词时,可能会得到多个上下文单词结果,情况如下图所示:
三、实验过程
1.预处理
在读取语料后,首先利用jieba分词对语料进行分词,去除一些无意义的广告和标点符号等内容,将分词后的语料重新写入新的txt保存下来,代码如下:
def read_novel(path_in, path_out): # 读取语料内容
content = []
names = os.listdir(path_in)
for name in names:
novel_name = path_in + '\\' + name
fenci_name = path_out + '\\' + name
fenci_name = fenci_name.replace('.txt', '')
fenci_name = fenci_name + 'fenci' + '.txt'
for line in open(novel_name, 'r', encoding='ANSI'):
line.strip('\n')
line = re.sub("[A-Za-z0-9\:\·\—\,\。\“\”\\n \《\》\!\?\、\...]", "", line)
line = content_deal(line)
con = jieba.cut(line, cut_all=False) # 结巴分词
# content.append(con)
content.append(" ".join(con))
with open(fenci_name, "w", encoding='utf-8') as f:
f.writelines(content)
return content, names
def content_deal(content): # 语料预处理,进行断句,去除一些广告和无意义内容
ad = ['本书来自www.cr173.com免费txt小说下载站\n更多更新免费电子书请关注www.cr173.com', '----〖新语丝电子文库(www.xys.org)〗', '新语丝电子文库',
'\u3000', '\n', '。' 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









