



 在TensorFlow 2.x的Keras中,使用LSTM进行训练时发现其训练速度比SimpleRNN更快。尽管LSTM理论上计算更复杂,但原因在于TensorFlow 2.x的LSTM内部进行了优化。通过对比不同版本的SimpleRNN和LSTM的实现,发现在tensorflow.compat.v1.keras.layers.LSTM中找到了与旧版SimpleRNN性能相近的实现,验证了LSTM的训练时间确实增加。
在TensorFlow 2.x的Keras中,使用LSTM进行训练时发现其训练速度比SimpleRNN更快。尽管LSTM理论上计算更复杂,但原因在于TensorFlow 2.x的LSTM内部进行了优化。通过对比不同版本的SimpleRNN和LSTM的实现,发现在tensorflow.compat.v1.keras.layers.LSTM中找到了与旧版SimpleRNN性能相近的实现,验证了LSTM的训练时间确实增加。
今天试验 TensorFlow 2.x , Keras 的 SimpleRNN 和 LSTM,发现同样的输入、同样的超参数设置、同样的参数规模,LSTM 的训练时长竟然远少于 SimpleRNN。
模型定义:


训练参数都这样传入:

我们知道,LSTM 是修正了的 SimpleRNN(我随意想出来的词,“修正”),或者说,是在 SimpleRNN 基础之上又添加了别的措施使模型能考虑到超长序列的标记之间的依赖。 缓解了梯度消失和梯度爆炸的问题。
所以,LSTM 比 SimpleRNN 是多了很多参数矩阵的,且每一步也多了一些计算。而训练过程既有前向,又有反向,不管哪个过程,理论上 LSTM都是比SimpleRNN要花更多时间的,那么为什么我在使用 TensorFlow with Keras 时会出现相反的情况呢?
训练情况(第一个 epoch):
SimpleRNN 的

LSTM的

原因,就在于:版本。
按住 Ctrl,点击两个类名 SimpleRNN 和 LSTM,进入定义的模块,会发现 from tensorflow.keras.layers import SimpleRNN 的 SimpleRNN定义所在的模块分别是这样的
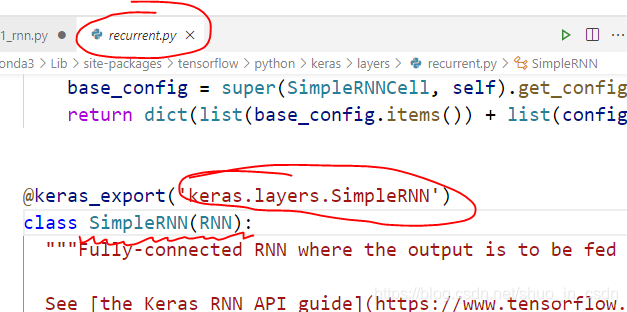
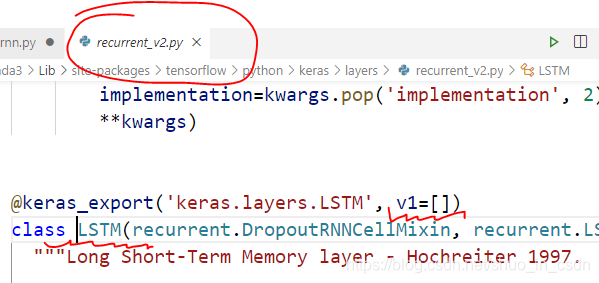
懂了,SimpleRNN 是 TensorFlow 1.xx 的东西,而这个 LSTM 是 TensorFlow 2.xx 的东西,肯定内部做了优化,反正二者一开始就不是一个起跑线上的东西。虽然我们写代码表面上都是from tensorflow.kears.layers 里 import 的,但是这种模块导入真的不能证明他们是放在同一个模块里定义的,因为导入是可以导来导去的,有的一个 import 就找到了它的定义,有的需要经过好几次 import 的传递,就像是个链,从我们的源文件一直到达最终定义的模块,这个 LSTM 隐藏的就很深(或者封装的很好(皮))。
要找到 这个 SimpleRNN 的 counterpart,就须使用 tensorflow.compat.v1.keras.layers.LSTM,找到它,发现
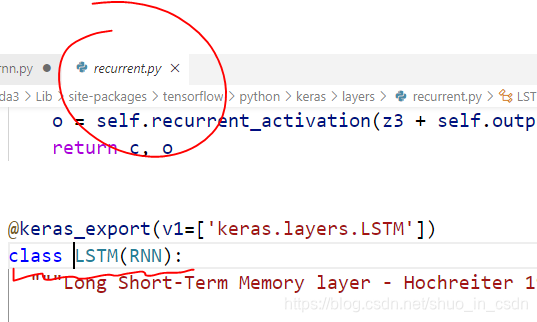
这就与上述 SimpleRNN 所在同一个模块了。
试验训练一下。

果然,比 SimpleRNN 慢得多,合理了。舒服了。
-------------------------------------------
我发现我真的好无聊,整天搞这些没用的。
抓主要矛盾,抓主要矛盾,主要矛盾!!!
下次一定 :)


















 11
11





 到【灌水乐园】发言
到【灌水乐园】发言







