






准备
- python基础:简单过一下,主要在用中学
- 机器学习:面试会考各种算法,甚至手推,实际场景难上场,放后面学
- 数据挖掘:numpy、pandas等各种科学包工具,做数据分析用到,做算法用到时查。
- NLP和CV:神经网络、卷积神经网络、递归神经网络。TensorFlow逐渐衰弱、PyTorch重点。
- opencv简单了解、重点YOLO v7(物理目标检测算法) efficientnet了解即可 detr、deformable detf要看
- 图像分割unet:用则看,不用放后面
- ai论文实验与项目实战mmlab:商汤,方便环境简单、模块组合生成、科研重点学习
- 行为识别:slowfast 根据需求看时间
- Transformer:重中之重 物理检测、分割、时间 积累思想 2周 debug源码
- 图神经网络实战:学三四个小时理解一遍。 3D点云实战、目标追踪与姿态估计
- 面向深度学习的无人驾驶实战:轨迹预测、三维重建 面试学学,简历里写
- 对比学习与多模态任务实战:后期学 前沿东西 缺陷检测、行人重识别
- 对抗生成网络实战:GNN 换脸 difussion
- 强化学习:适合论文、不适合项目 落地难
- openai 熟悉 医学深度学习 、模型部署与剪枝优化
- 自然语言处理算法:NLP 不要从基础开始 拼Transformer模型大小 huggingface:NLP社区
- 谷歌BERT 知识图谱
- 语音识别:就业机会不多 不建议走
- 推荐系统:大数据
PyCharm断点debug
- 点击PyCharm行数字后面行成红圈表示断点
- 右键debug运行
- console右面有四个图标
- 第一个图标:按行执行
- 第二个图标:跳入函数中
- 左面绿三角:跳到下一个断点
机器学习
- 人工智能的子领域,通过数据训练模型,使计算机从经验中学习并做出预测或决策而无需显示编程。包括监督学习、无监督学习和强化学习等方法。
- 适合小到中规模数据集和结构化数据,尤其特征工程得当情况,复杂问题需要手动提取特征。如信用评分、欺诈检测、推荐系统等。
- 模型较为简单如:线性回归、决策树、梯度提升树、支持向量机等,易于解释和调试。
- 数据获取
- 特征工程:筛选特征
- 建立模型
- 评估与应用
深度学习
- 机器学习的一个子领域,使用多层神经网络模拟人脑工作方式,自动从大量数据中学习复杂的模式和特征。
- 需要大量数据训练模型。减少手动筛选特征依赖,而是自动获取,适合非结构化数据,从而处理高维数据(图像、音频、文本)有优势。
- 模型复杂、包含大量参数和层次,性能强大但是难以解释,被称为黑盒。
神经网络
- 受生物神经系统启发而设计的计算模型,用于机器学习和人工智能。通过模拟人脑中神经元之间的连接和信息传递方式,从数据中学习复杂的模式和规律。
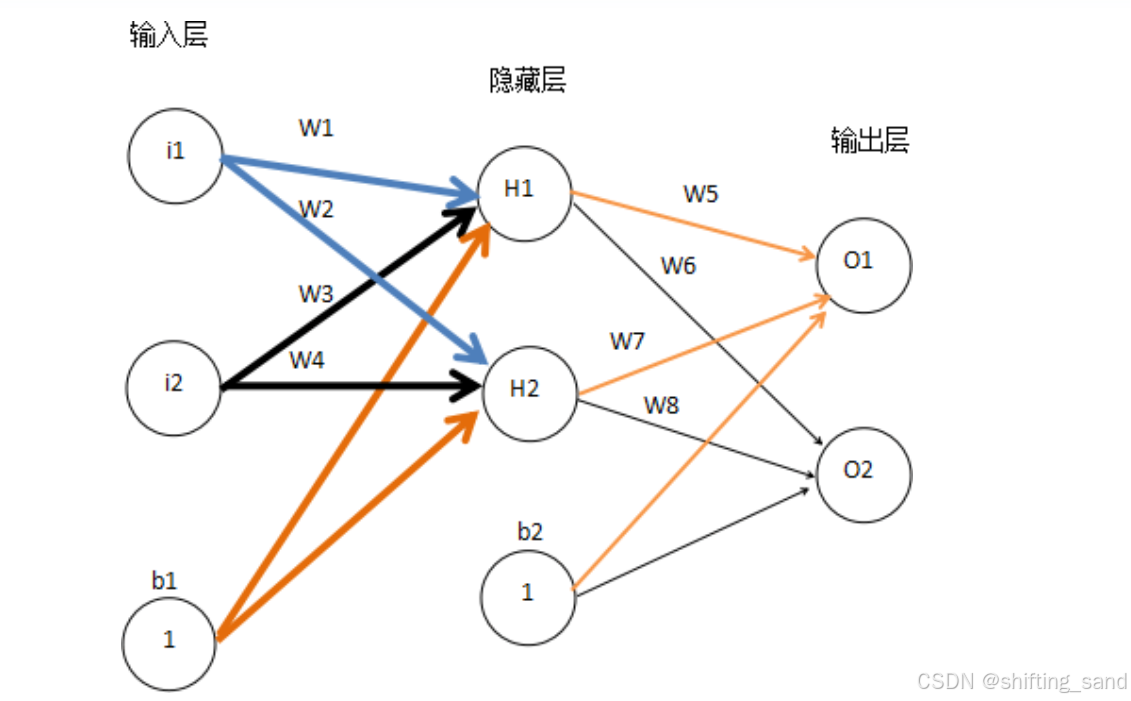
- 神经网络由多个神经元组成。这些神经元按照一定层次结构连接起来。
- 是深度学习的核心组成部分,用于图像识别、自然语言处理、语音识别等领域。
基本组成
-
输入层:第一层,接收数据,每个神经元对应一个输入特征。如图像像素值、文本词向量。只将数据传递到下一层。
-
隐藏层:输入层和输出层之间,有一层或多层。每层由多个神经元组成,各神经元通过权重和偏置对输入数据进行非线性变换。作用:提取数据特征,学习复杂的模式。
-
输出层:最后一层,生成预测结果。神经元数与任务相关,分类任务中等于类别数。结果通过激活函数进行归一化处理。
-
神经元
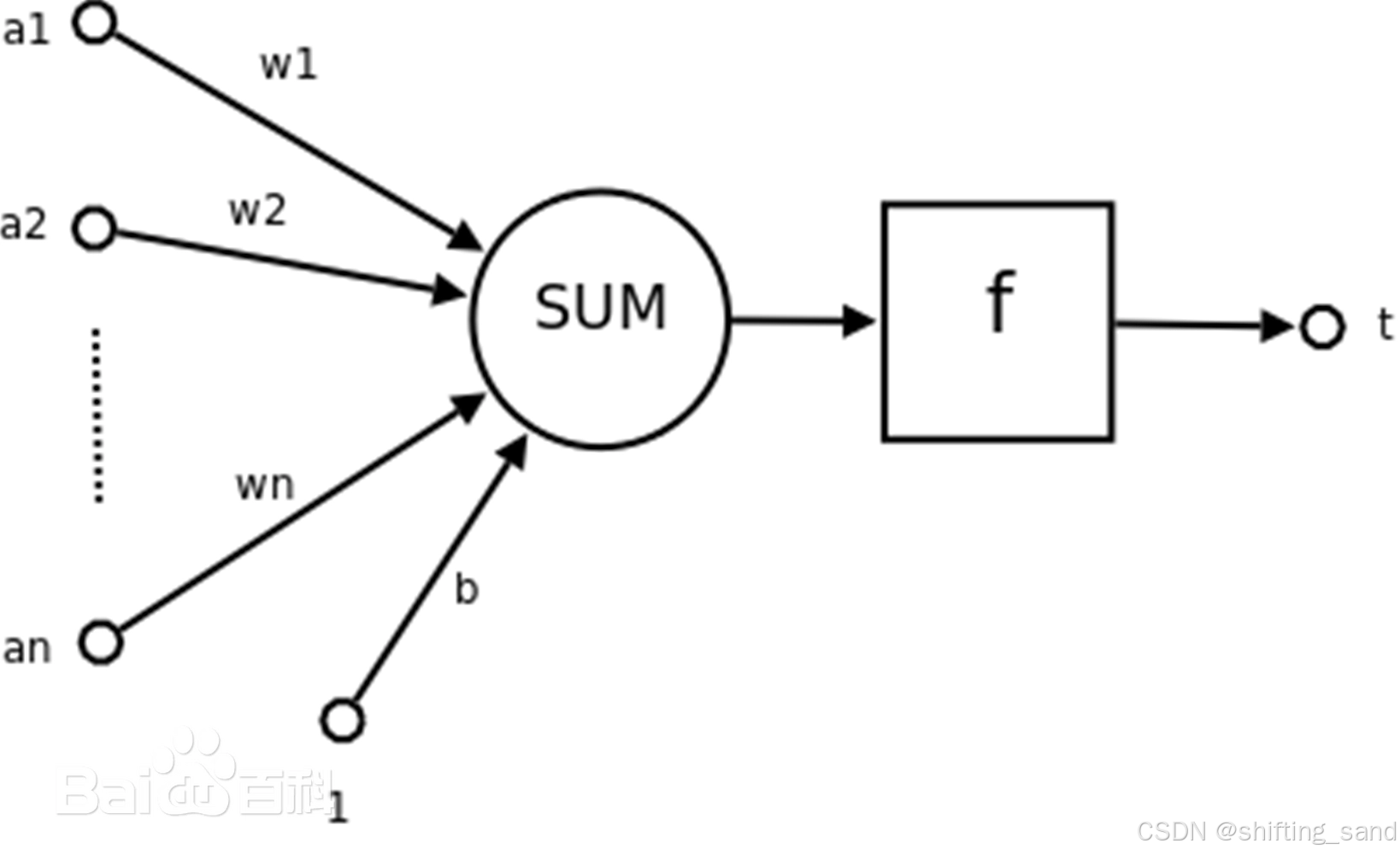
每个神经元接收上一层神经元的输入,计算加权和,通过激活函数产生输出。z= ∑ i = 1 n w i x i + b \sum_{i=1}^{n}w_ix_i+b ∑i=1nwixi+b,其中 w i w_i wi是权重, x i x_i xi是输入,b是偏置。a=f(z),f是激活函数
- 激活函数
作用:
- 引入非线性:神经网络基本组成是线性变化(矩阵),通过激活函数可以引入非线性,使神经网络能学习复杂的非线性模式。
- 增强模型表达能力:使得神经网络夹逼任意复杂函数。
- 缓解梯度消失问题:梯段消失导致网络难以训练。
- 增加模型稀疏性:将负值置为零,将某些神经元变为非激活,减少计算量。
- 适应不同任务需求
常见激活函数
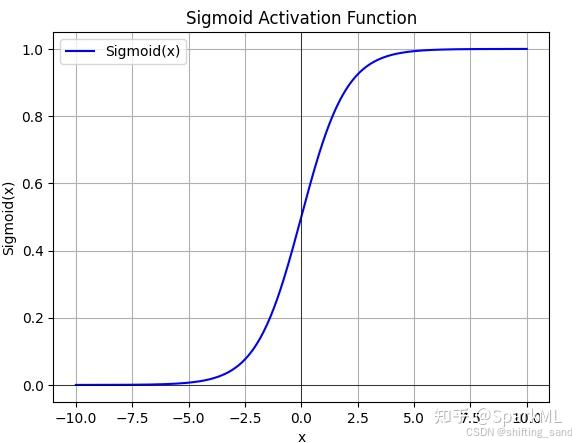
- Sigmoid:f(x) = 1 1 + e − x \frac{1}{1+e^{-x}} 1+e−x1,输入映射到输出范围(0,1)。适合二分类问题输出层或将输出归一化到(0,1)场景,表示概率。存在梯度消失问题,输入值较大或较小时,梯度接近于0,计算复杂度高设计指数运算。不适用于隐藏层,梯度消失会阻碍深层网路的训练。想[0,4]: ( 2 s i g m o i d ) 2 (2sigmoid)^2 (2sigmoid)2
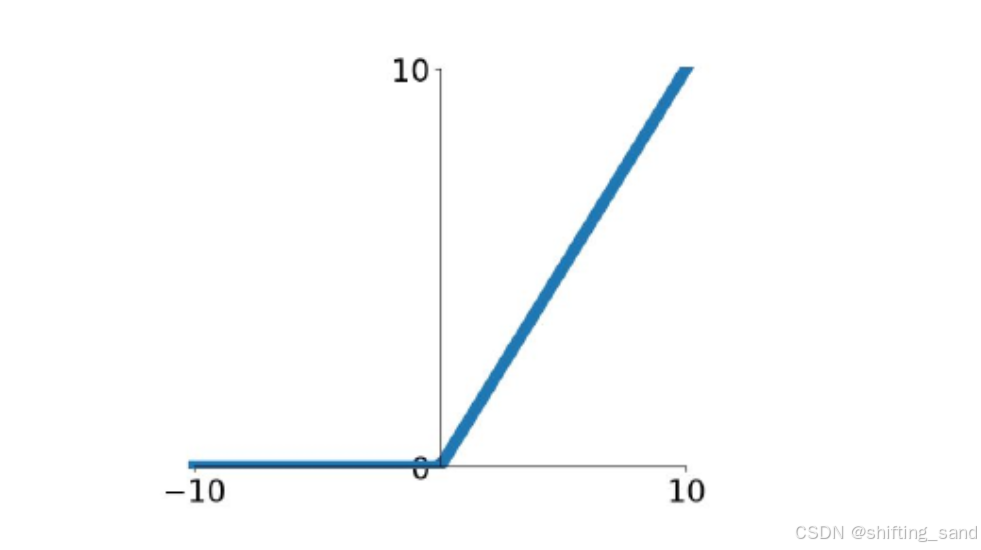
- ReLU:f(x)=max(0,x),输出:[0, +∞]。简单高效,只保留整数部分,负数部分置为0,缓解梯度消失问题,但是存在神经元永远输出0,无法更新。最常用的激活函数。
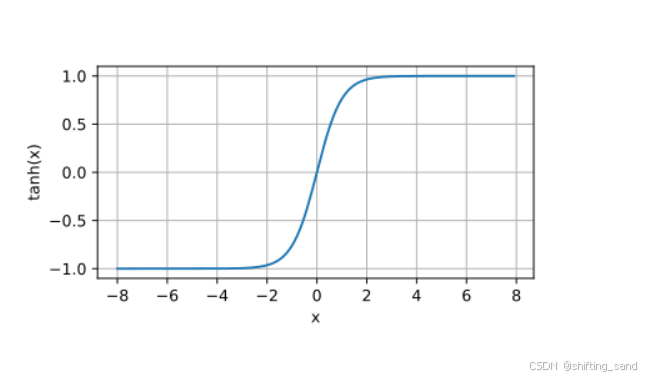
- Tanh:f(x) = e x − e − x e x + e − x \frac{e^x-e^{-x}}{e^x+e^{-x}} ex+e−xex−e−x 输出:(-1, 1),比sigmoid更接近于零均值,有助于缓解梯度消失问题,仍然存在梯度消失,比sigmoid好,计算复杂度高。
- Softmax(用于多分类任务的输出层):Softmax( z i z_i zi)= e z i ∑ j − 1 n e z j \frac{e^{z_i}}{\sum_{j-1}^{n}e^{z_j}} ∑j−1nezjezi 输出(0,1)且输出之和为1,通常用于多分类输出层,将输出转换为概率,计算复杂度高。
隐藏层选择:ReLU或其变体,计算高效且能缓解梯度消失问题
输出层选择:二分类-sigmoid、多分类-softmax、回归问题-不适用激活函数
工作原理
通过前向传播和反向传播来学习和预测
- 前向传播:输入层—>隐藏层—>输出层。每层神经元对输入数据加权求和并通过激活函数处理,结果传给下一层,直到最终预测值。
- 损失函数:输出层结果与真实标签之间差异通过损失函数(如均方误差、交叉熵等)进行量化,损失函数值越小,表示模型预测越接近真实值。
- 反向传播:通过链式法则计算损失函数对每个权重和偏置的梯度,梯度用于更新权重和偏置,使损失函数值逐渐减小。
在神经网络中,损失函数的计算和权重更新是在前向传播完全结束后进行的
- 优化算法:随机梯度下降(SGD)、Adam、RMSProp等,用于调整模型参数。
- 梯度,用于衡量损失函数相对于模型参数的变化率。梯度是一个向量,表示多元函数在某一点处各个方向上的变化率。梯度向量的方向是函数值增加最快的方向,大小是函数值增加的速率。
- 梯度下降算法的核心思想:沿着梯度的反方向更新参数,因为梯度的反方向是损失函数值减小最快的方向。
- 损失函数是个复杂的非线性函数,设计多个参数,为了计算梯度,用反向传播算法,通过链式法则从输出层逐层先前计算每个参数对损失函数的贡献。
神经网络的类型
- 前馈神经网络FNN:数据从输入流向输出,没有反馈连接,最简单的神经网络
- 卷积神经网络CNN:处理图像数据,利用卷积层提取局部特征,用于图像分类、目标检测等任务。
- 循环神经网络RNN:处理序列数据(时间序列、文本),具有记忆能力,常见变体:LSTM(长短期记忆网络)和GRU(门控循环单元)
- 生成对抗网络GAN:生成器和判别器组成,用于生成逼真数据。
- Transformer:基于自注意力机制
神经网络的类型
- 前馈神经网络FNN:数据从输入流向输出,没有反馈连接,最简单的神经网络
- 卷积神经网络CNN:处理图像数据,利用卷积层提取局部特征,用于图像分类、目标检测等任务。
- 循环神经网络RNN:处理序列数据(时间序列、文本),具有记忆能力,常见变体:LSTM(长短期记忆网络)和GRU(门控循环单元)
- 生成对抗网络GAN:生成器和判别器组成,用于生成逼真数据。
- Transformer:基于自注意力机制
其它概念
- encoder(编码器)、decoder(解码器):用于序列模型、自编码模型、transformer,用于将输入数据压缩为低维数据,处理完后重建为原始数据。
- 从头训练模型,随机权重w,不如使用预训练模型效率更高。
- batch批处理:训练模型时,将整个数据集分成若干小份(即批次),每次只使用其中一份数据进行参数更新。分批处理数据,可以更高效地利用计算资源,同时帮助模型更快地收敛。 大厂的百万级别 ,1750亿权重参数:2020年
- 训练神经网络模型时需要多批次epoch迭代训练模型,每次迭代数据分成若干batch。
- 加载数据:将整个数据集分为若干batch
- 前向传播:对当前batch数据进行前向计算得到预测值
- 计算损失:根据预测值和真实值计算损失函数
- 反向传播:通过梯度下降法更新模型参数
- BGD(Batch Gradient Descent)批量梯度下降:每次使用整个数据集(batch=数据集)计算梯度并更新参数。梯度方向准确,收敛路径稳定。但是计算开销大。
- SGD(Stochastic Gradient Descent)随机梯度下降:每次使用一个样本(batch=1)计算梯度并更新参数。计算速度快,随机跳出局部最优解。但是方向波动大,收敛不稳定。
- MGD(Mini-Batch Gradient Descent)小批量梯度下降:使用小批量数据(1<batch<数据集)计算梯度更新参数。计算效率高,梯度方向稳定。但需要选择适合的batch大小。
- 重复:对下一个batch重复上述过程,知道所有数据处理完(一个epoch)
- batch大小常见取值:32、64、128、256等。优点:提高计算效率(GPU并行加速)、减少内存占用、动态调整学习率(batch大小影响梯度方差影响学习率调整策略)、正则化效果(小batch引入随机性,可能起到正则化作用)。batch size会影响梯度方差,大batch size需要大学习率,小batch size需要小学习率。
- b偏置:允许没有输入也能有一定输出,增强模型表达能力和灵活性。激活函数的垂直便宜。增强模型拟合能力。
- 归一化normalize
归一化可以提高模型训练效率、收敛速度、整体性能。作用在输入数据、不同层之间。通常在激活函数之前或之后。
- 概念:将数据按比例缩放到特定范围,如[0,1]、均值为0,方差为1正太分布
- 输入数据归一化:最小最大归一化、标准化
- 批量归一化:随着层数增加,每一层输入分布会因为前面层参数变化而变化,称为内部协变量偏移。通过批量归一化可以使模型更加稳定,以便使用更大学习率加快训练速度。对小批次效果差
- 层归一化:主要用于循环神经网络和序列模型及卷积网络。适用于小批量,RNN、Transformer
- 实例归一化:适用于图像风格迁移、GNN
- 正则化:防止过拟合,提高泛化能力。
过拟合:模型在训练数据表现良好,未见过的测试数据表现差。捕捉到了噪声和细节。
欠拟合:模型过于简单,无法捕捉数据的基本模型。
在损失函数中加入正则化,限制模型参数大小或结果,防止模型复杂,提高泛化能力。
- L1正则化:在损失函数中添加模型参数绝对值之和作为惩罚项。产生稀疏模型,但复杂收敛慢
- L2正则化:在损失函数中添加模型参数平方和作为惩罚项。收敛快但不会产生稀疏模型。
- 弹性网络正则化:结合L1和L2正则化,平衡两者效果。但增加了复杂性。
- Dropout:训练过程中随机丢弃一部分神经元。简单有效但增加训练时间
- 早停法:在训练过程中监控模型在验证集上的表现,验证误差不再下降或上升停止训练。简单易行但需要额外验证集监控。
- 数据增强:对训练数据进行变换增加数据多样性。有效防过拟合但增加数据预处理复杂性。
- 权重衰减:优化过程中权重施加惩罚。
- 学习率:优化算法关键参数,决定了训练过程中更新参数的步长。
在模型通过反向传播计算损失函数对参数的梯度,然后用梯度下降更新参数,学习率决定参数更新的幅度。
- 学习率大:参数更新步长大,模型可能快速接近最优解但是也容易跳过导致不收敛。
- 学习率小:参数更新步长小,模型可能稳定收敛但训练速度慢。
- 固定学习率、自适应学习率、学习率衰减(训练逐渐减小学习率)


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









