








🎼个人主页:【Y小夜】
😎作者简介:一位双非学校的大二学生,编程爱好者,
专注于基础和实战分享,欢迎私信咨询!
感谢您的点赞、关注、评论、收藏、是对我最大的认可和支持!❤️

目录
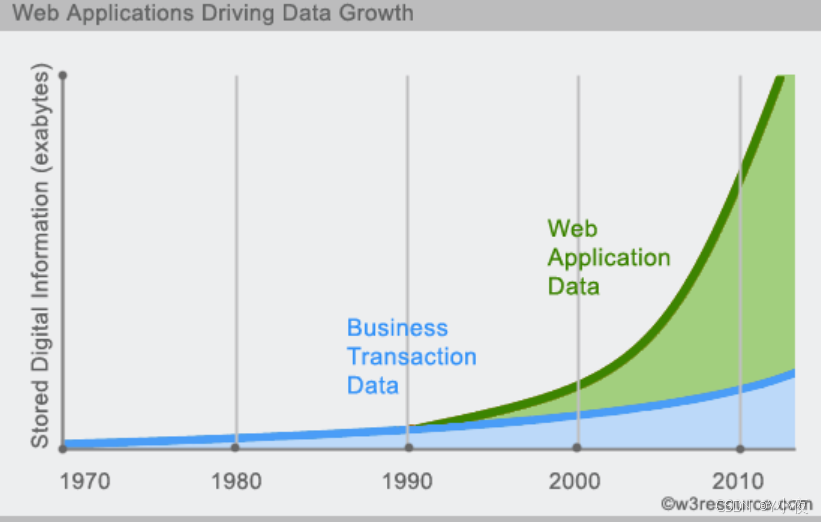
🎯认识NoSQL
😎基础概念
NoSQL 也称为“not only SQL”或“non-SQL”,它是一种数据库设计方法,可以在关系数据库中的传统结构之外存储和查询数据。NoSQL(NoSQL = Not Only SQL ),意即"不仅仅是SQL"。
- NoSQL 是一项全新的数据库革命性运动,早期就有人提出,发展至2009年趋势越发高涨。
- NoSQL的拥护者们提倡运用非关系型的数据存储,相对于铺天盖地的关系型数据库运用,这一概念无疑是一种全新的思维的注入。
NoSQL 数据库并非采用关系数据库的典型表结构,而是将数据存储在一个数据结构中,例如 JSON 文档。由于这种非关系数据库设计不需要使用架构,因此,它提供快速可扩展性以管理通常为非结构化的大型数据集。
NoSQL 也是一种分布式数据库类型,这意味着将信息复制并存储在不同的服务器上,这些服务器可能是远程服务器或本地服务器。这确保了数据的可用性和可靠性。如果一些数据脱机,数据库的其他部分可以继续运行。
😎NoSQL与SQL的不同
数据库管理系统 (DBMS) 使用户能够组织大量的数据。然而,这些系统非常复杂,通常是特定应用程序专有的,并且挖掘数据中的信息的方法也受到限制。程序员需要使用比 SQL 数据库(即关系数据库)更灵活的数据库。NoSQL 成为了这种替代方案。
相比之下,NoSQL 数据库是非关系型的,从而不再需要连接表。借助内置的分片和高可用性功能,这种数据库可以轻松进行水平扩展。如果单个数据库服务器不足以存储所有数据或处理所有查询,则可以将工作负载拆分到两个或多个服务器上,从而允许公司水平扩展数据。
今天我们可以通过第三方平台(如:Google,Facebook等)可以很容易的访问和抓取数据。用户的个人信息,社交网络,地理位置,用户生成的数据和用户操作日志已经成倍的增加。我们如果要对这些用户数据进行挖掘,那SQL数据库已经不适合这些应用了, NoSQL 数据库的发展却能很好的处理这些大的数据。
😎NoSQL的优点/缺点
优点:
- - 高可扩展性
- - 分布式计算
- - 低成本
- - 架构的灵活性,半结构化数据
- - 没有复杂的关系
缺点:
- - 没有标准化
- - 有限的查询功能(到目前为止)
- - 最终一致是不直观的程序
😎NoSQL 数据库类型
✨键值存储
这通常被认为是最简单形式的 NoSQL 数据库。这种无架构数据模型被组织成一个键值对字典,其中的每一项具有键和值。键可能与 SQL 数据库中的键类似(例如,购物车 ID),而值是一个数据数组(例如,该用户的购物车中的每件物品)。该模型通常用于缓存和存储用户会话信息,例如购物车。不过,在您需要一次提取多条记录时,该模型不太理想。Redis 和 Memcached 是开源键值数据库示例。
✨文档存储
顾名思义,文档数据库将数据存储为文档。它们可以帮助管理半结构化数据,通常以 JSON、XML 或 BSON 格式存储数据。在应用程序中使用数据时,这会将数据放在一起,从而减少使用数据所需的转换工作量。开发人员还获得了更大的灵活性,因为不需要在文档之间匹配数据架构(例如 name 与 first_name)。然而,对于复杂事务来说,这可能会造成问题,从而导致数据损坏。文档数据库的常见用例包括内容管理系统和用户档案。
😎扩展
- 海量 Volume
- 多样 Variety
- 实时 Velocity
- 高并发
- 高可用
- 高性能
🎯 Redis概念入门
官网:Redis - The Real-time Data Platform
😎基础概念
😎应用场景
Redis被广泛应用于缓存系统、消息队列、会话存储、实时分析等领域。例如,在社交网络中,可以使用Redis来存储用户会话信息,实现快速的登录和注销操作。在大数据场景下,Redis可以作为高速缓存层,存放热点数据,减少对后端数据库的访问压力。
😎特点
Redis的特点包括其单线程模型和基于内存的运行机制。尽管是单线程,但通过高效的事件驱动模型,Redis能处理高并发请求,保持低延迟和高性能。同时,由于数据存储在内存中,Redis的读写速度非常快,通常用于缓存和会话管理等需要快速响应的场景。
🎯Linux上安装Redis
进入官网,点击下载
- 下载获得 redis-5.0.7.tar.gz 后将它放到我们Linux的目录下 /opt
- /opt 目录下,解压命令 : tar -zxvf redis-5.0.7.tar.gz
- 解压完成后出现文件夹:redis-5.0.7
- 进入目录: cd redis-5.0.7
- 在 redis-5.0.7 目录下执行 make 命令
运行make命令时故意出现的错误解析:
1. 安装gcc (gcc是linux下的一个编译程序,是c程序的编译工具)
能上网: yum install gcc-c++
版本测试: gcc-v
2. 二次make
3. Jemalloc/jemalloc.h: 没有那个文件或目录
运行 make distclean 之后再make
4. Redis Test(可以不用执行)
cd /usr/local/bin
ls -l
# 在redis的解压目录下备份redis.conf
mkdir myredis
cp redis.conf myredis # 拷一个备份,养成良好的习惯,我们就修改这个文件
# 修改配置保证可以后台应用
vim redis.conf
- daemonize:yes
- daemonize:no
# 【shell】启动redis服务
[root@192 bin]# cd /usr/local/bin
[root@192 bin]# redis-server /opt/redis-5.0.7/redis.conf
# redis客户端连接===> 观察地址的变化,如果连接ok,是直接连上的,redis默认端口号 6379
[root@192 bin]# redis-cli -p 6379
127.0.0.1:6379> ping
PONG
127.0.0.1:6379> set k1 helloworld
OK
127.0.0.1:6379> get k1
"helloworld"
# 【shell】ps显示系统当前进程信息
[root@192 myredis]# ps -ef|grep redis
root 16005 1 0 04:45 ? 00:00:00 redis-server
# 【redis】关闭连接
127.0.0.1:6379> shutdown
not connected> exit🎯 Redis基础知识
😎压力测试工具
redis压力测试工具-----Redis-benchmark
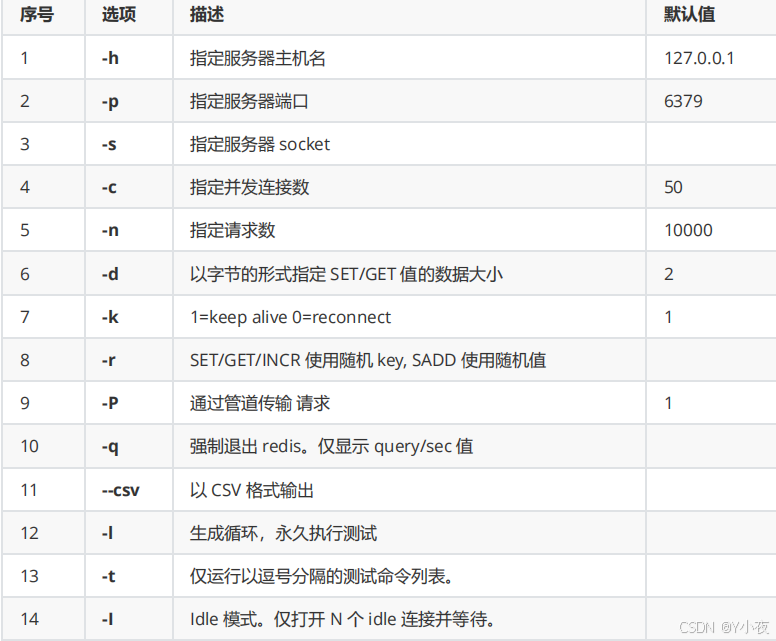
参数如下:
# 测试一:100个并发连接,100000个请求,检测host为localhost 端口为6379的redis服务器性
能
redis-benchmark -h localhost -p 6379 -c 100 -n 100000
# 测试出来的所有命令只举例一个!
====== SET ======
100000 requests completed in 1.88 seconds # 对集合写入测试
100 parallel clients # 每次请求有100个并发客户端
3 bytes payload # 每次写入3个字节的数据,有效载荷
keep alive: 1 # 保持一个连接,一台服务器来处理这些请求
17.05% <= 1 milliseconds
97.35% <= 2 milliseconds
99.97% <= 3 milliseconds
100.00% <= 3 milliseconds # 所有请求在 3 毫秒内完成
53248.14 requests per second # 每秒处理 53248.14 次请求😎数据库的基础
默认16个数据库,类似数组下标从零开始,初始默认使用零号库
查看 redis.conf ,里面有默认的配置
databases 16Select命令切换数据库
127.0.0.1:6379> select 7
OK
127.0.0.1:6379[7]>
# 不同的库可以存不同的数据😎Redis是单线程还是多线程?
✨Redis的线程模型
- 单线程时代:在Redis的早期版本(3.x及之前),其主要执行模式是单线程。这种单线程模型是指Redis的网络I/O(输入/输出)和键值对的读写操作都由一个主线程顺序执行。
- 多线程转变:自4.0版本起,Redis开始引入多线程特性。具体来说,4.x版本主要在数据删除等特定操作上引入了多线程,而6.x版本则全面支持多线程。在Redis 6中,除了主要的内存操作依然由单个线程处理外,IO操作已经由多个子线程完成,从而有效利用多核CPU。
✨为何采用单线程
- 避免复杂性:单线程模型大大简化了Redis的开发和维护工作。由于没有多线程中的竞争条件和死锁问题,代码更加清晰和易于理解。
- 性能考虑:尽管Redis是单线程,但它使用非阻塞I/O和IO多路复用技术,可以高效地处理多个客户端请求。这使得单线程模型依然能够提供高并发性能。
- 瓶颈不在CPU:Redis的操作主要是内存和I/O bound,而非CPU bound。这意味着在许多情况下,系统的瓶颈在于内存和网络带宽,而不是CPU,因此采用单线程是合理的选择。
✨Redis的高速度原因
- 基于内存操作:Redis的所有数据都存储在内存中,内存的读写速度远高于磁盘I/O,这为Redis的高性能提供了基础。
- 高效的数据结构:Redis内部使用了哈希表、跳表、压缩列表等多种高效的数据结构,这些数据结构的设计使得大多数操作的时间复杂度为O(1)。
- 非阻塞I/O和事件驱动:Redis使用了epoll等非阻塞I/O模型和事件驱动机制,使得单个线程可以同时处理多个并发连接,极大地提高了性能。
官方表示,因为Redis 是基于内存的操作,CPU不是Redis的瓶颈,Redis 的瓶颈最有可能是机器内存的大小或者网络带宽。既然单线程容易实现,而且CPU不会成为瓶颈,那就顺理成章地采用单线程的方案了!Redis采用的是基于内存的采用的是单进程单线程模型的 KV 数据库,由C语言编写,官方提供的数据是 可以达到100000+的QPS(每秒内查询次数)。1)以前一直有个误区,以为:高性能服务器 一定是多线程来实现的原因很简单因为误区二导致的:多线程 一定比 单线程 效率高,其实不然! 在说这个事前希望大家都能对 CPU 、 内存 、 硬盘的速度都有了解了!2) redis 核心就是 如果我的数据全都在内存里,我单线程的去操作 就是效率最高的,为什么呢,因为 多线程的本质就是 CPU 模拟出来多个线程的情况,这种模拟出来的情况就有一个代价,就是上下文的切换,对于一个内存的系统来说,它没有上下文的切换就是效率最高的。redis 用 单个 CPU 绑定一块内存的数据,然后针对这块内存的数据进行多次读写的时候,都是在一个CPU 上完成的,所以它是单线程处理这个事。在内存的情况下,这个方案就是最佳方案。
🎯五大基础数据类型
😎String类型(最常用)
Redis中的String类型是一种基础数据类型,支持字符串、整数或浮点数的存储和操作。
✨常用命令
# ===================================================
# set、get、del、append、strlen
# ===================================================
127.0.0.1:6379> set key1 value1 # 设置值
OK
127.0.0.1:6379> get key1 # 获得key
"value1"
127.0.0.1:6379> del key1 # 删除key
(integer) 1
127.0.0.1:6379> keys * # 查看全部的key
(empty list or set)
127.0.0.1:6379> exists key1 # 确保 key1 不存在
(integer) 0
127.0.0.1:6379> append key1 "hello" # 对不存在的 key 进行 APPEND ,等同于 SET
key1 "hello"
(integer) 5 # 字符长度
127.0.0.1:6379> APPEND key1 "-2333" # 对已存在的字符串进行 APPEND
(integer) 10 # 长度从 5 个字符增加到 10 个字符
127.0.0.1:6379> get key1
"hello-2333"
127.0.0.1:6379> STRLEN key1 # # 获取字符串的长度
(integer) 10
# ===================================================
# incr、decr 一定要是数字才能进行加减,+1 和 -1。
# incrby、decrby 命令将 key 中储存的数字加上指定的增量值。
# ===================================================
127.0.0.1:6379> set views 0 # 设置浏览量为0
OK
127.0.0.1:6379> incr views # 浏览 + 1
(integer) 1
127.0.0.1:6379> incr views # 浏览 + 1
(integer) 2
127.0.0.1:6379> decr views # 浏览 - 1
(integer) 1
127.0.0.1:6379> incrby views 10 # +10
(integer) 11
127.0.0.1:6379> decrby views 10 # -10
(integer) 1
# ===================================================
# range [范围]
# getrange 获取指定区间范围内的值,类似between...and的关系,从零到负一表示全部
# ===================================================
127.0.0.1:6379> set key2 abcd123456 # 设置key2的值
OK
127.0.0.1:6379> getrange key2 0 -1 # 获得全部的值
"abcd123456"
127.0.0.1:6379> getrange key2 0 2 # 截取部分字符串
"abc"
# ===================================================
# setrange 设置指定区间范围内的值,格式是setrange key值 具体值
# ===================================================
127.0.0.1:6379> get key2
"abcd123456"
127.0.0.1:6379> SETRANGE key2 1 xx # 替换值
(integer) 10
127.0.0.1:6379> get key2
"axxd123456"
# ===================================================
# setex(set with expire)键秒值
# setnx(set if not exist)
# ===================================================
127.0.0.1:6379> setex key3 60 expire # 设置过期时间
OK
127.0.0.1:6379> ttl key3 # 查看剩余的时间
(integer) 55
127.0.0.1:6379> setnx mykey "redis" # 如果不存在就设置,成功返回1
(integer) 1
127.0.0.1:6379> setnx mykey "mongodb" # 如果存在就设置,失败返回0
(integer) 0
127.0.0.1:6379> get mykey
"redis"
# ===================================================
# mset Mset 命令用于同时设置一个或多个 key-value 对。
# mget Mget 命令返回所有(一个或多个)给定 key 的值。
# 如果给定的 key 里面,有某个 key 不存在,那么这个 key 返回特殊值 nil 。
# msetnx 当所有 key 都成功设置,返回 1 。
# 如果所有给定 key 都设置失败(至少有一个 key 已经存在),那么返回 0 。原子操
作
# ===================================================
127.0.0.1:6379> mset k10 v10 k11 v11 k12 v12
String数据结构是简单的key-value类型,value其实不仅可以是String,也可以是数字。
常规key-value缓存应用:
常规计数:微博数,粉丝数等。
列表List
单值多Value
OK
127.0.0.1:6379> keys *
1) "k12"
2) "k11"
3) "k10"
127.0.0.1:6379> mget k10 k11 k12 k13
1) "v10"
2) "v11"
3) "v12"
4) (nil)
127.0.0.1:6379> msetnx k10 v10 k15 v15 # 原子性操作!
(integer) 0
127.0.0.1:6379> get key15
(nil)
# 传统对象缓存
set user:1 value(json数据)
# 可以用来缓存对象
mset user:1:name zhangsan user:1:age 2
mget user:1:name user:1:age
# ===================================================
# getset(先get再set)
# ===================================================
127.0.0.1:6379> getset db mongodb # 没有旧值,返回 nil
(nil)
127.0.0.1:6379> get db
"mongodb"
127.0.0.1:6379> getset db redis # 返回旧值 mongodb
"mongodb"
127.0.0.1:6379> get db
"redis"✨应用场景
- 缓存:由于Redis的高性能特性,String类型常用于缓存数据库查询结果、网页内容等,提升系统读取速度。
- 计数器:利用INCR和DECR操作,String类型可以作为计数器使用,例如记录网页访问量或下载量。
- 分布式锁:通过“SET key value”(只有在key不存在时才设置value)的命令,可以实现分布式锁,保证系统的并发安全。
- 分布式共享:在多个系统间需要共享的数据(如用户会话信息)可以存储在Redis的String类型中,方便数据共享和同步
😎List 类型
Redis中的列表(List)类型是一个双向链表,用于存储多个有序的字符串。它支持从列表两端插入或移除元素,也支持获取指定范围的元素。
✨基本命令
# ===================================================
# Lpush:将一个或多个值插入到列表头部。(左)
# rpush:将一个或多个值插入到列表尾部。(右)
# lrange:返回列表中指定区间内的元素,区间以偏移量 START 和 END 指定。
# 其中 0 表示列表的第一个元素, 1 表示列表的第二个元素,以此类推。
# 你也可以使用负数下标,以 -1 表示列表的最后一个元素, -2 表示列表的倒数第二个元素,以此
类推。
# ===================================================
127.0.0.1:6379> LPUSH list "one"
(integer) 1
127.0.0.1:6379> LPUSH list "two"
(integer) 2
127.0.0.1:6379> RPUSH list "right"
(integer) 3
127.0.0.1:6379> Lrange list 0 -1
1) "two"
2) "one"
3) "right"
127.0.0.1:6379> Lrange list 0 1
1) "two"
2) "one"
# ===================================================
# lpop 命令用于移除并返回列表的第一个元素。当列表 key 不存在时,返回 nil 。
# rpop 移除列表的最后一个元素,返回值为移除的元素。
# ===================================================
127.0.0.1:6379> Lpop list
"two"
127.0.0.1:6379> Rpop list
"right"
127.0.0.1:6379> Lrange list 0 -1
1) "one"
# ===================================================
# Lindex,按照索引下标获得元素(-1代表最后一个,0代表是第一个)
# ===================================================
127.0.0.1:6379> Lindex list 1
(nil)
127.0.0.1:6379> Lindex list 0
"one"
127.0.0.1:6379> Lindex list -1
"one"
# ===================================================
# llen 用于返回列表的长度。
# ===================================================
127.0.0.1:6379> flushdb
OK
127.0.0.1:6379> Lpush list "one"
(integer) 1
127.0.0.1:6379> Lpush list "two"
(integer) 2
127.0.0.1:6379> Lpush list "three"
(integer) 3
127.0.0.1:6379> Llen list # 返回列表的长度
(integer) 3
# ===================================================
# lrem key 根据参数 COUNT 的值,移除列表中与参数 VALUE 相等的元素。
# ===================================================
127.0.0.1:6379> lrem list 1 "two"
(integer) 1
127.0.0.1:6379> Lrange list 0 -1
1) "three"
2) "one"
# ===================================================
# Ltrim key 对一个列表进行修剪(trim),就是说,让列表只保留指定区间内的元素,不在指定区
间之内的元素都将被删除。
# ===================================================
127.0.0.1:6379> RPUSH mylist "hello"
(integer) 1
127.0.0.1:6379> RPUSH mylist "hello"
(integer) 2
127.0.0.1:6379> RPUSH mylist "hello2"
(integer) 3
127.0.0.1:6379> RPUSH mylist "hello3"
(integer) 4
127.0.0.1:6379> ltrim mylist 1 2
OK
127.0.0.1:6379> lrange mylist 0 -1
1) "hello"
2) "hello2"
# ===================================================
# rpoplpush 移除列表的最后一个元素,并将该元素添加到另一个列表并返回。
# ===================================================
127.0.0.1:6379> rpush mylist "hello"
(integer) 1
127.0.0.1:6379> rpush mylist "foo"
(integer) 2
127.0.0.1:6379> rpush mylist "bar"
(integer) 3
127.0.0.1:6379> rpoplpush mylist myotherlist
"bar"
127.0.0.1:6379> lrange mylist 0 -1
1) "hello"
2) "foo"
127.0.0.1:6379> lrange myotherlist 0 -1
1) "bar"
# ===================================================
# lset key index value 将列表 key 下标为 index 的元素的值设置为 value 。
# ===================================================
127.0.0.1:6379> exists list # 对空列表(key 不存在)进行 LSET
(integer) 0
127.0.0.1:6379> lset list 0 item # 报错
(error) ERR no such key
127.0.0.1:6379> lpush list "value1" # 对非空列表进行 LSET
(integer) 1
127.0.0.1:6379> lrange list 0 0
1) "value1"
127.0.0.1:6379> lset list 0 "new" # 更新值
OK
127.0.0.1:6379> lrange list 0 0
1) "new"
127.0.0.1:6379> lset list 1 "new" # index 超出范围报错
(error) ERR index out of range
# ===================================================
# linsert key before/after pivot value 用于在列表的元素前或者后插入元素。
# 将值 value 插入到列表 key 当中,位于值 pivot 之前或之后。
# ===================================================
redis> RPUSH mylist "Hello"
(integer) 1
redis> RPUSH mylist "World"
(integer) 2
✨应用场景
- 队列和栈:利用
LPUSH和RPOP可以实现队列功能,而LPUSH和LPOP组合可以实现栈功能。这在任务调度和消息队列等场景非常有用。 - 消息队列:List可以用作消息队列,通过列表的头部和尾部操作,可以确保消息的保序和处理。但应注意,因Redis是内存存储,所以在服务器宕机时可能丢失数据,同时高并发情况下可能存在热Key问题。
- 社交网络:在社交网络应用中,如朋友圈点赞或微博关注人列表等,需要有序记录用户操作的场合,List类型是非常适用的选择
😎Set类型
Redis中的Set类型是一种无序且唯一的键值集合,主要用于存储不重复的数据。它通过哈希表实现,添加、删除和查找操作的时间复杂度均为O(1),因此非常适合需要快速操作的场景。
✨基本命令
# ===================================================
# sadd 将一个或多个成员元素加入到集合中,不能重复
# smembers 返回集合中的所有的成员。
# sismember 命令判断成员元素是否是集合的成员。
# ===================================================
127.0.0.1:6379> sadd myset "hello"
(integer) 1
127.0.0.1:6379> sadd myset "kuangshen"
(integer) 1
127.0.0.1:6379> sadd myset "kuangshen"
(integer) 0
127.0.0.1:6379> SMEMBERS myset
1) "kuangshen"
2) "hello"
127.0.0.1:6379> SISMEMBER myset "hello"
(integer) 1
127.0.0.1:6379> SISMEMBER myset "world"
(integer) 0
# ===================================================
# scard,获取集合里面的元素个数
# ===================================================
127.0.0.1:6379> scard myset
(integer) 2
# ===================================================
# srem key value 用于移除集合中的一个或多个成员元素
# ===================================================
127.0.0.1:6379> srem myset "kuangshen"
(integer) 1
127.0.0.1:6379> SMEMBERS myset
1) "hello"
# ===================================================
# srandmember key 命令用于返回集合中的一个随机元素。
# ===================================================
127.0.0.1:6379> SMEMBERS myset
1) "kuangshen"
2) "world"
3) "hello"
127.0.0.1:6379> SRANDMEMBER myset
"hello"
127.0.0.1:6379> SRANDMEMBER myset 2
1) "world"
2) "kuangshen"
127.0.0.1:6379> SRANDMEMBER myset 2
1) "kuangshen"
2) "hello"
# ===================================================
# spop key 用于移除集合中的指定 key 的一个或多个随机元素
# ===================================================
127.0.0.1:6379> SMEMBERS myset
1) "kuangshen"
2) "world"
3) "hello"
127.0.0.1:6379> spop myset
"world"
127.0.0.1:6379> spop myset
"kuangshen"
127.0.0.1:6379> spop myset
"hello"
# ===================================================
# smove SOURCE DESTINATION MEMBER
# 将指定成员 member 元素从 source 集合移动到 destination 集合。
# ===================================================
127.0.0.1:6379> sadd myset "hello"
(integer) 1
127.0.0.1:6379> sadd myset "world"
(integer) 1
127.0.0.1:6379> sadd myset "kuangshen"
(integer) 1
127.0.0.1:6379> sadd myset2 "set2"
(integer) 1
127.0.0.1:6379> smove myset myset2 "kuangshen"
(integer) 1
127.0.0.1:6379> SMEMBERS myset
1) "world"
2) "hello"
127.0.0.1:6379> SMEMBERS myset2
1) "kuangshen"
2) "set2"
# ===================================================
- 数字集合类
- 差集: sdiff
- 交集: sinter
- 并集: sunion
# ===================================================
127.0.0.1:6379> sadd key1 "a"
(integer) 1
127.0.0.1:6379> sadd key1 "b"
(integer) 1
127.0.0.1:6379> sadd key1 "c"
(integer) 1
127.0.0.1:6379> sadd key2 "c"
(integer) 1
127.0.0.1:6379> sadd key2 "d"
(integer) 1
127.0.0.1:6379> sadd key2 "e"
(integer) 1
127.0.0.1:6379> SDIFF key1 key2 # 差集
1) "a"
2) "b"
127.0.0.1:6379> SINTER key1 key2 # 交集
1) "c"
127.0.0.1:6379> SUNION key1 key2 # 并集
1) "a"
2) "b"
3) "c"
4) "e"
5) "d"✨应用场景
- 去重与存在性检查:因为Set中的元素都是唯一的,所以非常适合需要去重的场景,如记录唯一访问IP、投票系统等。同时,通过SISMEMBER命令,可以快速检查某个元素是否存在于集合中。
- 交集与差集运算:Set支持交集、差集和并集运算,适用于社交网络中的好友推荐、共同关注等领域。
- 随机选取:使用SPOP或SRANDMEMBER命令,可以从集合中随机选取元素,适用于抽奖、随机展示广告等场景。
😎Hash类型
Redis中的Hash类型是一个键值对的映射表,适合存储对象型数据。每个Hash可以存储多达2^32-1个键值对,即超过40亿个元素
✨基本命令
# ===================================================
# hset、hget 命令用于为哈希表中的字段赋值 。
# hmset、hmget 同时将多个field-value对设置到哈希表中。会覆盖哈希表中已存在的字段。
# hgetall 用于返回哈希表中,所有的字段和值。
# hdel 用于删除哈希表 key 中的一个或多个指定字段
# ===================================================
127.0.0.1:6379> hset myhash field1 "kuangshen"
(integer) 1
127.0.0.1:6379> hget myhash field1
"kuangshen"
127.0.0.1:6379> HMSET myhash field1 "Hello" field2 "World"
OK
127.0.0.1:6379> HGET myhash field1
"Hello"
127.0.0.1:6379> HGET myhash field2
"World"
127.0.0.1:6379> hgetall myhash
1) "field1"
2) "Hello"
3) "field2"
4) "World"
127.0.0.1:6379> HDEL myhash field1
(integer) 1
127.0.0.1:6379> hgetall myhash
1) "field2"
2) "World"
# ===================================================
# hlen 获取哈希表中字段的数量。
# ===================================================
127.0.0.1:6379> hlen myhash
(integer) 1
127.0.0.1:6379> HMSET myhash field1 "Hello" field2 "World"
OK
127.0.0.1:6379> hlen myhash
(integer) 2
# ===================================================
# hexists 查看哈希表的指定字段是否存在。
# ===================================================
127.0.0.1:6379> hexists myhash field1
(integer) 1
127.0.0.1:6379> hexists myhash field3
(integer) 0
# ===================================================
# hkeys 获取哈希表中的所有域(field)。
# hvals 返回哈希表所有域(field)的值。
# ===================================================
127.0.0.1:6379> HKEYS myhash
1) "field2"
2) "field1"
127.0.0.1:6379> HVALS myhash
1) "World"
2) "Hello"
# ===================================================
# hincrby 为哈希表中的字段值加上指定增量值。
# ===================================================
127.0.0.1:6379> hset myhash field 5
(integer) 1
127.0.0.1:6379> HINCRBY myhash field 1
(integer) 6
127.0.0.1:6379> HINCRBY myhash field -1
(integer) 5
127.0.0.1:6379> HINCRBY myhash field -10
(integer) -5
# ===================================================
# hsetnx 为哈希表中不存在的的字段赋值 。
# ===================================================
127.0.0.1:6379> HSETNX myhash field1 "hello"
(integer) 1 # 设置成功,返回 1 。
127.0.0.1:6379> HSETNX myhash field1 "world"
(integer) 0 # 如果给定字段已经存在,返回 0 。
127.0.0.1:6379> HGET myhash field1
"hello"✨应用场景
- 存储对象信息:由于Hash能够存储多个属性及其值,它非常适合存储如用户信息、配置信息等对象类型的数据。例如,可以将一个用户的姓名、年龄、性别等信息存储在一个Hash中,以用户ID作为key。
- 计数器和统计:利用
HINCRBY命令,Hash可以用作各种计数场景,比如网站访问量、商品销售量等。 - 配置文件管理:Hash可用于存储和管理应用配置,通过简单的key-field结构,可以方便地获取和更新配置信息。
- 缓存复合数据:在需要缓存复杂数据结构时,Hash提供了一个简洁的方式,可以将相关数据集合在一起,减少缓存的冗余。
😎Zset类型
Zset(有序集合)是Redis提供的一种非常强大的数据类型,它基于Set(集合)类型,并增加了一个分数(score)参数,使得集合中的元素可以按照分数进行排序。
✨基本命令
# ===================================================
# zadd 将一个或多个成员元素及其分数值加入到有序集当中。
# zrange 返回有序集中,指定区间内的成员
# ===================================================
127.0.0.1:6379> zadd myset 1 "one"
(integer) 1
127.0.0.1:6379> zadd myset 2 "two" 3 "three"
(integer) 2
127.0.0.1:6379> ZRANGE myset 0 -1
1) "one"
2) "two"
3) "three"
# ===================================================
# zrangebyscore 返回有序集合中指定分数区间的成员列表。有序集成员按分数值递增(从小到大)
次序排列。
# ===================================================
127.0.0.1:6379> zadd salary 2500 xiaoming
(integer) 1
127.0.0.1:6379> zadd salary 5000 xiaohong
(integer) 1
127.0.0.1:6379> zadd salary 500 kuangshen
(integer) 1
# Inf无穷大量+∞,同样地,-∞可以表示为-Inf。
127.0.0.1:6379> ZRANGEBYSCORE salary -inf +inf # 显示整个有序集
1) "kuangshen"
2) "xiaoming"
3) "xiaohong"
127.0.0.1:6379> ZRANGEBYSCORE salary -inf +inf withscores # 递增排列
1) "kuangshen"
2) "500"
3) "xiaoming"
4) "2500"
5) "xiaohong"
6) "5000"
127.0.0.1:6379> ZREVRANGE salary 0 -1 WITHSCORES # 递减排列
1) "xiaohong"
2) "5000"
3) "xiaoming"
4) "2500"
5) "kuangshen"
6) "500"
127.0.0.1:6379> ZRANGEBYSCORE salary -inf 2500 WITHSCORES # 显示工资 <=2500
的所有成员
1) "kuangshen"
2) "500"
3) "xiaoming"
4) "2500"
# ===================================================
# zrem 移除有序集中的一个或多个成员
# ===================================================
127.0.0.1:6379> ZRANGE salary 0 -1
1) "kuangshen"
2) "xiaoming"
3) "xiaohong"
127.0.0.1:6379> zrem salary kuangshen
(integer) 1
127.0.0.1:6379> ZRANGE salary 0 -1
1) "xiaoming"
2) "xiaohong"
# ===================================================
# zcard 命令用于计算集合中元素的数量。
# ===================================================
127.0.0.1:6379> zcard salary
(integer) 2
OK
# ===================================================
# zcount 计算有序集合中指定分数区间的成员数量。
# ===================================================
127.0.0.1:6379> zadd myset 1 "hello"
(integer) 1
127.0.0.1:6379> zadd myset 2 "world" 3 "kuangshen"
(integer) 2
127.0.0.1:6379> ZCOUNT myset 1 3
(integer) 3
127.0.0.1:6379> ZCOUNT myset 1 2
(integer) 2
# ===================================================
# zrank 返回有序集中指定成员的排名。其中有序集成员按分数值递增(从小到大)顺序排列。
# ===================================================
127.0.0.1:6379> zadd salary 2500 xiaoming
(integer) 1
127.0.0.1:6379> zadd salary 5000 xiaohong
(integer) 1
127.0.0.1:6379> zadd salary 500 kuangshen
(integer) 1
127.0.0.1:6379> ZRANGE salary 0 -1 WITHSCORES # 显示所有成员及其 score 值
1) "kuangshen"
2) "500"
3) "xiaoming"
4) "2500"
5) "xiaohong"
6) "5000"
127.0.0.1:6379> zrank salary kuangshen # 显示 kuangshen 的薪水排名,最少
(integer) 0
127.0.0.1:6379> zrank salary xiaohong # 显示 xiaohong 的薪水排名,第三
(integer) 2
# ===================================================
# zrevrank 返回有序集中成员的排名。其中有序集成员按分数值递减(从大到小)排序。
# ===================================================
127.0.0.1:6379> ZREVRANK salary kuangshen # ✨应用场景
- 内存与性能平衡:根据
zset-max-ziplist-entries和zset-max-ziplist-value配置参数,Redis动态选择底层结构,以平衡内存使用和性能。 - 跳跃表性能优势:跳跃表的查找、插入、删除操作的平均时间复杂度均为O(log n),适合处理大量数据。
- 压缩列表节省内存:通过紧凑存储方式显著降低内存占用,适用于小规模数据集。
🎯三大特殊类型
😎GEO类型
# 语法
geoadd key longitude latitude member ...
# 将给定的空间元素(纬度、经度、名字)添加到指定的键里面。
# 这些数据会以有序集he的形式被储存在键里面,从而使得georadius和georadiusbymember这样的
命令可以在之后通过位置查询取得这些元素。
# geoadd命令以标准的x,y格式接受参数,所以用户必须先输入经度,然后再输入纬度。
# geoadd能够记录的坐标是有限的:非常接近两极的区域无法被索引。
# 有效的经度介于-180-180度之间,有效的纬度介于-85.05112878 度至 85.05112878 度之间。,
当用户尝试输入一个超出范围的经度或者纬度时,geoadd命令将返回一个错误。
# 语法
geopos key member [member...]
#从key里返回所有给定位置元素的位置(经度和纬度)
# 语法
geodist key member1 member2 [unit]
# 返回两个给定位置之间的距离,如果两个位置之间的其中一个不存在,那么命令返回空值。
# 指定单位的参数unit必须是以下单位的其中一个:
# m表示单位为米
# km表示单位为千米
# mi表示单位为英里
# ft表示单位为英尺
# 如果用户没有显式地指定单位参数,那么geodist默认使用米作为单位。
#geodist命令在计算距离时会假设地球为完美的球形,在极限情况下,这一假设最大会造成0.5%的误
差。
# 语法
georadius key longitude latitude radius m|km|ft|mi [withcoord][withdist]
[withhash][asc|desc][count count]
# 以给定的经纬度为中心, 找出某一半径内的元素
# 语法
georadiusbymember key member radius m|km|ft|mi [withcoord][withdist]
[withhash][asc|desc][count count]
# 找出位于指定范围内的元素,中心点是由给定的位置元素决定
# 语法
geohash key member [member...]
# Redis使用geohash将二维经纬度转换为一维字符串,字符串越长表示位置更精确,两个字符串越相似
表示距离越近。
😎HyperLogLog

127.0.0.1:6379> PFADD mykey a b c d e f g h i j
1
127.0.0.1:6379> PFCOUNT mykey
10
127.0.0.1:6379> PFADD mykey2 i j z x c v b n m
1
127.0.0.1:6379> PFMERGE mykey3 mykey mykey2
OK
127.0.0.1:6379> PFCOUNT mykey3
15😎BitMap
BitMap是一种数据结构,通过最小单位bit(位)来进行数据存储和操作,主要用于统计二值状态或大规模数据中的数据存在性问题。
# 使用 bitmap 来记录上述事例中一周的打卡记录如下所示:
# 周一:1,周二:0,周三:0,周四:1,周五:1,周六:0,周天:0 (1 为打卡,0 为不打卡)
127.0.0.1:6379> setbit sign 0 1
0
127.0.0.1:6379> setbit sign 1 0
0
127.0.0.1:6379> setbit sign 2 0
0
127.0.0.1:6379> setbit sign 3 1
0
127.0.0.1:6379> setbit sign 4 1
0
127.0.0.1:6379> setbit sign 5 0
0
127.0.0.1:6379> setbit sign 6 0
0
127.0.0.1:6379> getbit sign 3 # 查看周四是否打卡
1
127.0.0.1:6379> getbit sign 6 # 查看周七是否打卡
0
# 统计这周打卡的记录,可以看到只有3天是打卡的状态:
127.0.0.1:6379> bitcount sign
3🎯Jedis
Jedis 是 Redis 官方推荐的面向 Java 操作 Redis 的客户端开发包。它集成了 Redis 的命令操作,提供了连接池管理功能,通过 Jedis 可以方便地连接 Redis 以及操作数据。
测试
导入redis的依赖!
<!-- https://mvnrepository.com/artifact/redis.clients/jedis -->
<dependency>
<groupId>redis.clients</groupId>
<artifactId>jedis</artifactId>
<version>3.2.0</version>
</dependency>
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>fastjson</artifactId>
<version>1.2.58</version>
</dependency>编写测试代码
package com.kuang.ping;
import redis.clients.jedis.Jedis;
public class Ping {
public static void main(String[] args) {
Jedis jedis = new Jedis("127.0.0.1",6379);
System.out.println("连接成功");
//查看服务是否运行
System.out.println("服务正在运行: "+jedis.ping());
}
}连接成功
服务正在运行: PONG😎本地连接
直接点开Redist-Service,然后直接连
😎远端连接
✨在Linux中开放6379端口
1、运行命令:firewall-cmd --get-active-zones
2、执行如下命令命令:firewall-cmd --zone=public --add-port=6379/tcp --permanent
3、重启防火墙,运行命令:firewall-cmd --reload
4、查看端口号是否开启,运行命令:firewall-cmd --query-port=6379/tcp
做完以上操作 就会把CentOS的防火墙打开6379的端口

✨修改Redis-Server配置
打开redis的配置文件redis.conf,将bind 127.0.0.1注释掉。
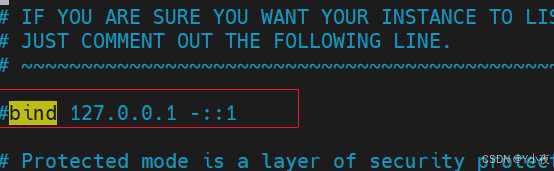
找到配置文件中protected-mode,默认protected mode yes,需要将其改为protected mode no

启动Redis-server,用Idea连接测试

连接成功
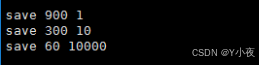
🎯Redis持久化
😎Rdb模式
😎Aof模式
Aof模式通过日志的形式记录写操作,并以文本格式追加到文件的末尾。这种模式解决了RDB在数据恢复一致性上的问题,提高了数据的安全性和可靠性。与RDB相比,Aof的写入机制更频繁,能够更及时地将数据保存到磁盘中。Aof文件的载入是通过重新执行Aof文件中的命令来恢复数据状态。这个过程可能在数据量大时会比较慢,但能够确保数据的完整性。
在Redis-conf中,找到
appendonly no # 是否以append only模式作为持久化方式,默认使用的是rdb方式持久化,这
种方式在许多应用中已经足够用了
appendfilename "appendonly.aof" # appendfilename AOF 文件名称
appendfsync everysec # appendfsync aof持久化策略的配置
# no表示不执行fsync,由操作系统保证数据同步到磁盘,速度最快。
# always表示每次写入都执行fsync,以保证数据同步到磁盘。
# everysec表示每秒执行一次fsync,可能会导致丢失这1s数据。
No-appendfsync-on-rewrite #重写时是否可以运用Appendfsync,用默认no即可,保证数据安
全性
Auto-aof-rewrite-min-size # 设置重写的基准值
Auto-aof-rewrite-percentage #设置重写的基准值- 正常恢复:
- 启动:设置Yes,修改默认的appendonly no,改为yes
- 将有数据的aof文件复制一份保存到对应目录(config get dir)
- 恢复:重启redis然后重新加载
- 异常恢复:
- 启动:设置Yes
- 故意破坏 appendonly.aof 文件!
- 修复: redis-check-aof --fix appendonly.aof 进行修复
- 恢复:重启 redis 然后重新加载
😎二者进行对比
只做缓存,如果你只希望你的数据在服务器运行的时候存在,你也可以不使用任何持久化
同时开启两种方式(性能要求比较高)
- 在这种情况下,当redis重启的时候会优先载入AOF文件来恢复原始的数据,因为在通常情况下AOF 文件保存的数据集要比RDB文件保存的数据集要完整。
- RDB 的数据不实时,同时使用两者时服务器重启也只会找AOF文件,那要不要只使用AOF呢?作者建议不要,因为RDB更适合用于备份数据库(AOF在不断变化不好备份),快速重启,而且不会有AOF可能潜在的Bug,留着作为一个万一的手段。
总的来说,RDB模式和AOF模式各有优劣,选择哪一种取决于具体的应用场景和需求。如果希望快速恢复且可以接受一定量的数据丢失,可以选择RDB模式;如果希望最大限度地保证数据的完整性,可以选择AOF模式。同时使用两者可以综合各自的优势,达到既能快速恢复又能尽量保证数据完整性的效果
🎯事务操作
步骤:
- 开始事务
- 命令入队
- 执行事务
watch key1 key2 ... #监视一或多个key,如果在事务执行之前,被监视的key被其他命令改动,则
事务被打断 ( 类似乐观锁 )
multi # 标记一个事务块的开始( queued )
exec # 执行所有事务块的命令 ( 一旦执行exec后,之前加的监控锁都会被取消掉 )
discard # 取消事务,放弃事务块中的所有命令
unwatch # 取消watch对所有key的监控😎悲观锁
悲观锁基于一种悲观的假设,即认为两个或更多的并发事务在操作同一资源时很可能会相互影响。因此,悲观锁会在事务开始时就锁定资源,防止其他事务同时修改数据。
😎乐观锁
乐观锁基于一种乐观的假设,它假设多个事务在操作同一资源时不会相互影响。乐观锁并不在事务开始时锁定资源,而是在提交之前检查资源是否有冲突,如果有则事务回滚。
127.0.0.1:6379> set balance 100
OK
127.0.0.1:6379> set debt 0
OK
127.0.0.1:6379> watch balance
OK
127.0.0.1:6379> MULTI
OK
127.0.0.1:6379> decrby balance 20
QUEUED
127.0.0.1:6379> incrby debt 20
QUEUED
127.0.0.1:6379> exec
1) (integer) 80
2) (integer) 20
# 窗口一
127.0.0.1:6379> watch balance
OK
127.0.0.1:6379> MULTI # 执行完毕后,执行窗口二代码测试
OK
127.0.0.1:6379> decrby balance 20
QUEUED
127.0.0.1:6379> incrby debt 20
QUEUED
127.0.0.1:6379> exec # 修改失败!
(nil)
# 窗口二
127.0.0.1:6379> get balance
"80"
127.0.0.1:6379> set balance 200
OK
# 窗口一:出现问题后放弃监视,然后重来!
127.0.0.1:6379> UNWATCH # 放弃监视
OK
127.0.0.1:6379> watch balance
OK
127.0.0.1:6379> MULTI
OK
127.0.0.1:6379> decrby balance 20
QUEUED
127.0.0.1:6379> incrby debt 20
QUEUED
127.0.0.1:6379> exec # 成功!
1) (integer) 180
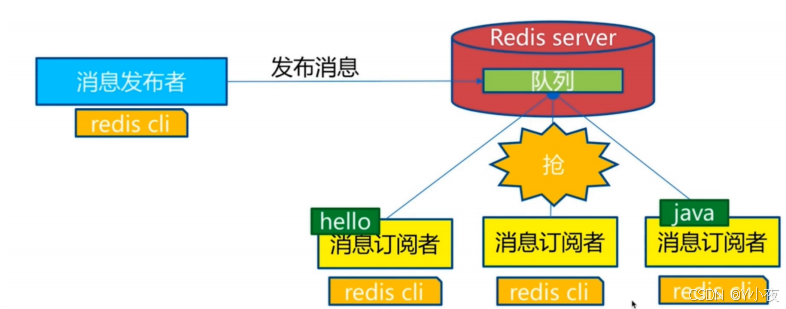
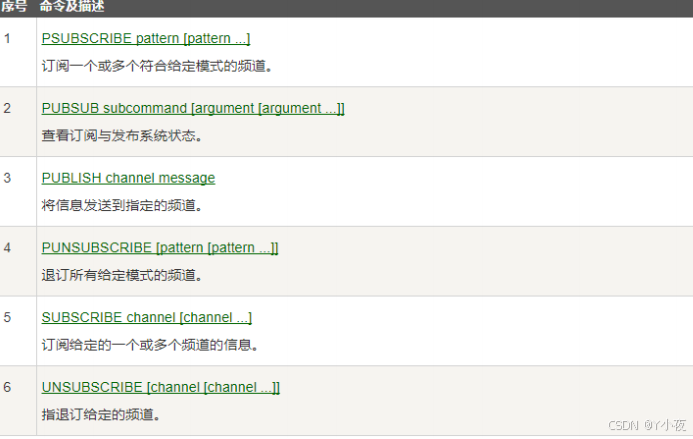
2) (integer) 40🎯消息订阅
redis 127.0.0.1:6379> SUBSCRIBE redisChat
Reading messages... (press Ctrl-C to quit)
1) "subscribe"
2) "redisChat"
3) (integer) 1redis 127.0.0.1:6379> PUBLISH redisChat "Hello,Redis"
(integer) 1
redis 127.0.0.1:6379> PUBLISH redisChat "Hello,Kuangshen"
(integer) 1
# 订阅者的客户端会显示如下消息
1) "message"
2) "redisChat"
3) "Hello,Redis"
1) "message"
2) "redisChat"
3) "Hello,Kuangshen"- Pub/Sub构建实时消息系统
- Redis的Pub/Sub系统可以构建实时的消息系统
- 比如很多用Pub/Sub构建的实时聊天系统的例子。
🎯Redis主从复制
slaveof 主库ip 主库端口 # 配置主从
Info replication # 查看信息
🎯哨兵模式
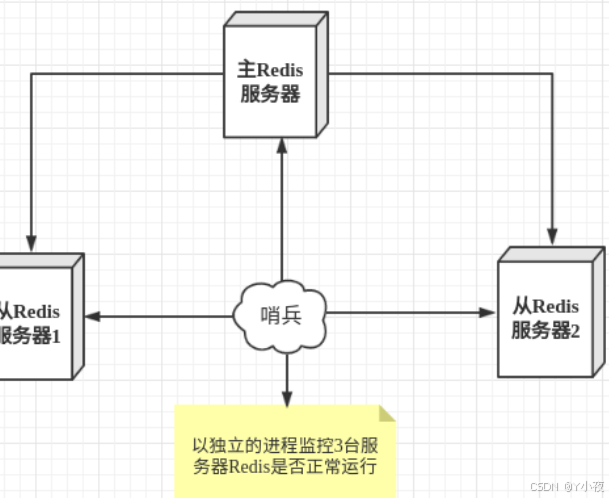
- 通过发送命令,让Redis服务器返回监控其运行状态,包括主服务器和从服务器。
- 当哨兵监测到master宕机,会自动将slave切换成master,然后通过发布订阅模式通知其他的从服务器,修改配置文件,让它们切换主机。
sentinel monitor 被监控主机名字 ip 6379 1优点:
- 1. 哨兵集群模式是基于主从模式的,所有主从的优点,哨兵模式同样具有。
- 2. 主从可以切换,故障可以转移,系统可用性更好。
- 3. 哨兵模式是主从模式的升级,系统更健壮,可用性更高。
🎯缓存穿透与雪崩
😎缓存穿透
✨布隆过滤器
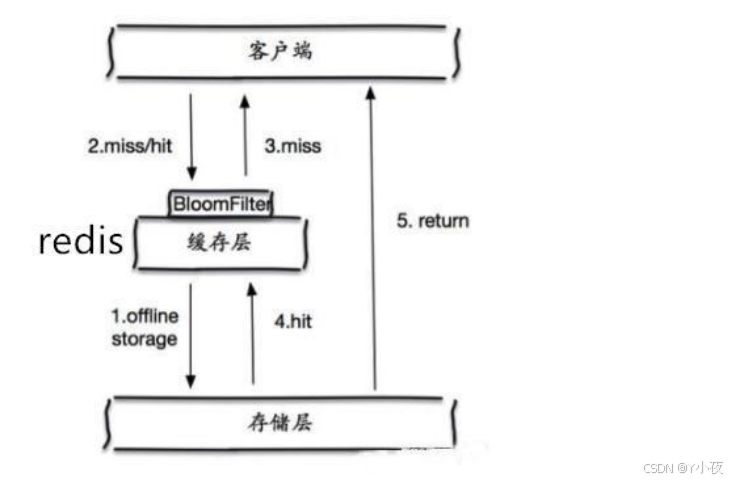
✨缓存空对象
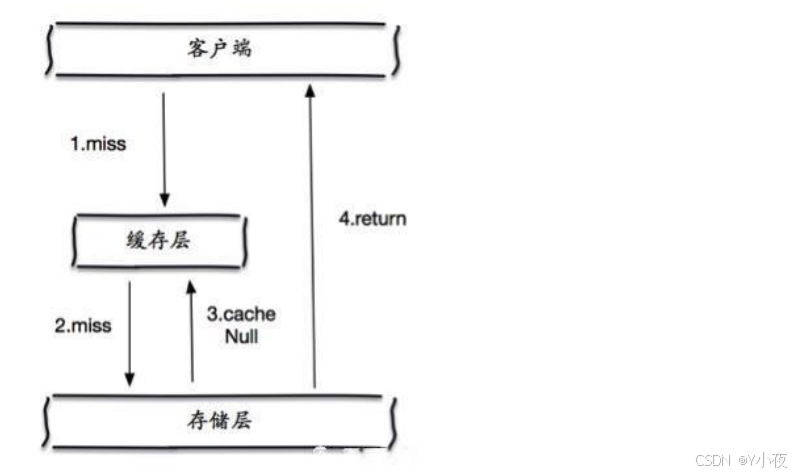
😎缓存击穿
✨设置热点数据永不过期
✨加互斥锁
😎缓存雪崩





















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











