







文章目录
YOLO系列在目标检测领域一直处于领先地位,尤其是YOLOv8版本,通过其创新的结构和优化提升了检测精度和速度。然而,如何进一步提高精度,特别是在不增加计算负担的情况下,仍然是一个亟待解决的问题。为此,本文将探讨一种新的轻量级下采样方法——ContextGuided,通过该方法可以大幅提升YOLOv8的检测性能,同时保持模型的高效性。
1. 背景
YOLOv8在保持实时性和高精度的基础上,加入了多项优化,尤其是在特征提取、特征融合以及检测头的设计上。然而,YOLOv8仍然面临着在处理高分辨率图像时计算资源消耗较大的问题。为了解决这一问题,本文提出了一种新的下采样方法——ContextGuided,通过精确的上下文信息引导下采样过程,能够有效地提升特征提取的精度,并减少不必要的计算开销。
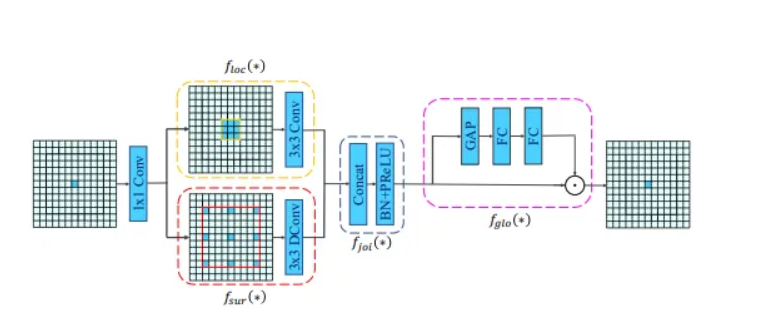
2. 方法原理
2.1 下采样的挑战
下采样操作是卷积神经网络(CNN)中常见的操作,它通过降低特征图的分辨率来减少计算量&#

 订阅专栏 解锁全文
订阅专栏 解锁全文

















 3058
3058

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









