




java Springboot 爬虫实现 淘宝网站 爬取
我们使用 Selenium 进行浏览器源代码爬取。
让我们简单粗暴的开始吧!
首先我们pom.xml 导入如下配置
<!-- 爬虫框架 -->
<dependency>
<groupId>org.jsoup</groupId>
<artifactId>jsoup</artifactId>
<version>1.13.1</version>
</dependency>
<!-- Selenium WebDriver -->
<dependency>
<groupId>org.seleniumhq.selenium</groupId>
<artifactId>selenium-java</artifactId>
<version>4.0.0</version>
</dependency>
<!-- 浏览器驱动,以Chrome为例 -->
<dependency>
<groupId>org.seleniumhq.selenium</groupId>
<artifactId>selenium-chrome-driver</artifactId>
<version>4.0.0</version>
</dependency>
<!--htmlunit-->
<dependency>
<groupId>net.sourceforge.htmlunit</groupId>
<artifactId>htmlunit</artifactId>
<version>2.33</version>
</dependency>
<!--导入 easyExcel依赖 -->
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>easyexcel</artifactId>
<version>3.3.2</version>
</dependency>
我是用的谷歌浏览器爬的,当然也可以选择其他浏览器~~
需要下载 chromedriver 驱动,我用的是谷歌 最新版本的,下载地址:https://googlechromelabs.github.io/chrome-for-testing/
下载完后,解压放到D盘下 D:\chromedriver-win64\chromedriver-win64
核心代码还有下载excel表格 代码 如下: 复制粘贴即可运行
// 然后 新建一个 pojo 类,创建excel 商品对象
import com.alibaba.excel.annotation.ExcelProperty;
import com.alibaba.excel.annotation.write.style.ColumnWidth;
import com.alibaba.excel.annotation.write.style.ContentRowHeight;
import io.swagger.annotations.ApiModel;
import io.swagger.annotations.ApiModelProperty;
import lombok.Data;
import java.io.Serializable;
/**
* 返回的商品对象
*
* @version 1.0
* @Author : zr
* @date 2025/1/16 14:10
*/
@Data
@ContentRowHeight(100)
@ColumnWidth(100 / 4)
@ApiModel("商品的Excel对象")
public class ExcelRes implements Serializable {
@ExcelProperty(value = "商品名称")
@ApiModelProperty(value = "商品名称", dataType = "String", required = true)
private String name;
@ExcelProperty(value = "商品价格")
@ApiModelProperty(value = "商品价格", dataType = "String", required = true)
private String price;
@ExcelProperty(value = "商品图片")
@ApiModelProperty(value = "商品图片", dataType = "String", required = true)
private String imgUrl;
@ExcelProperty(value = "商品详情跳转链接")
@ApiModelProperty(value = "商品详情跳转链接", dataType = "String", required = true)
private String itemUrl;
}
public static void main(String[] args) throws Exception {
//下载的chromedriver驱动的路径,我的路径放在了D盘下
System.setProperty("webdriver.chrome.driver", "D:\\chromedriver-win64\\chromedriver-win64\\chromedriver.exe");
WebDriver driver = null;
try {
ChromeOptions options = new ChromeOptions();
// options.addArguments("--headless"); // 无头模式,不打开浏览器窗口
// 禁用信息栏
options.addArguments("--disable-infobars");
options.setExperimentalOption("excludeSwitches", new String[]{"enable-automation"});
// options.addArguments("--remote-debugging-port=9222");
driver = new ChromeDriver(options);
driver.get("https://www.taobao.com"); // 打开淘宝或京东页面
WebDriverWait wait = new WebDriverWait(driver, 30);
wait.until(ExpectedConditions.presenceOfElementLocated((By.cssSelector("#q")))).sendKeys("手机"); //需要搜索的商品名称
// 提交搜索
wait.until(ExpectedConditions.elementToBeClickable(By.cssSelector("#J_TSearchForm > div.search-button > button"))).click();
// 这里假设人工会在浏览器打开的页面上进行扫码操作
// 等待人工扫码,打开手机淘宝app进行扫码登录,可以通过线程睡眠或其他方式等待
Thread.sleep(60000); // 假设人工操作需要60秒,根据实际情况调整
String content = driver.getPageSource(); // 获取页面源码
//打印爬取的代码。这里可以进行后续的代码逻辑处理,提取有用的代码,这里要根据我们的需求处理
System.out.println(content);
//下载excel表格
onLoadExcl(content);
} catch (Exception e) {
e.printStackTrace();
return null;
} finally {
if (driver != null) {
driver.quit();
}
}
}
/**
* 下载excl
* @throws Exception
*/
private void onLoadExcl(String content) throws Exception {
List<ExcelRes> res = getHtmlList(content);
// 导出Excel
// 获取桌面路径
String desktopPath = System.getProperty("user.home") + "/Desktop/";
// 指定导出的文件路径和文件名
String fileName = desktopPath + "商品信息.xlsx";
EasyExcel.write(fileName, ExcelRes.class).sheet("商品信息").doWrite(res);
}
private List<ExcelRes> getHtmlList(String content){
Document doc = Jsoup.parse(content);
Elements items = doc.select("#content_items_wrapper > div");
List<ExcelRes> excelResList = new ArrayList<>();
items.forEach(item -> {
ExcelRes excelRes = new ExcelRes();
String name = item.select("div.title--qJ7Xg_90 > span").text();
String price = item.select("span.unit--D3KGoZe2").text()
+ item.select("span.priceInt--yqqZMJ5a").text()
+ item.select("span.priceFloat--XpixvyQ1").text();
String imgUrl = item.select(".mainPic--Ds3X7I8z").attr("src");
String url = "https:" + item.select("a").attr("href");
excelRes.setName(name);
excelRes.setPrice(price);
excelRes.setImgUrl(imgUrl);
excelRes.setItemUrl(url);
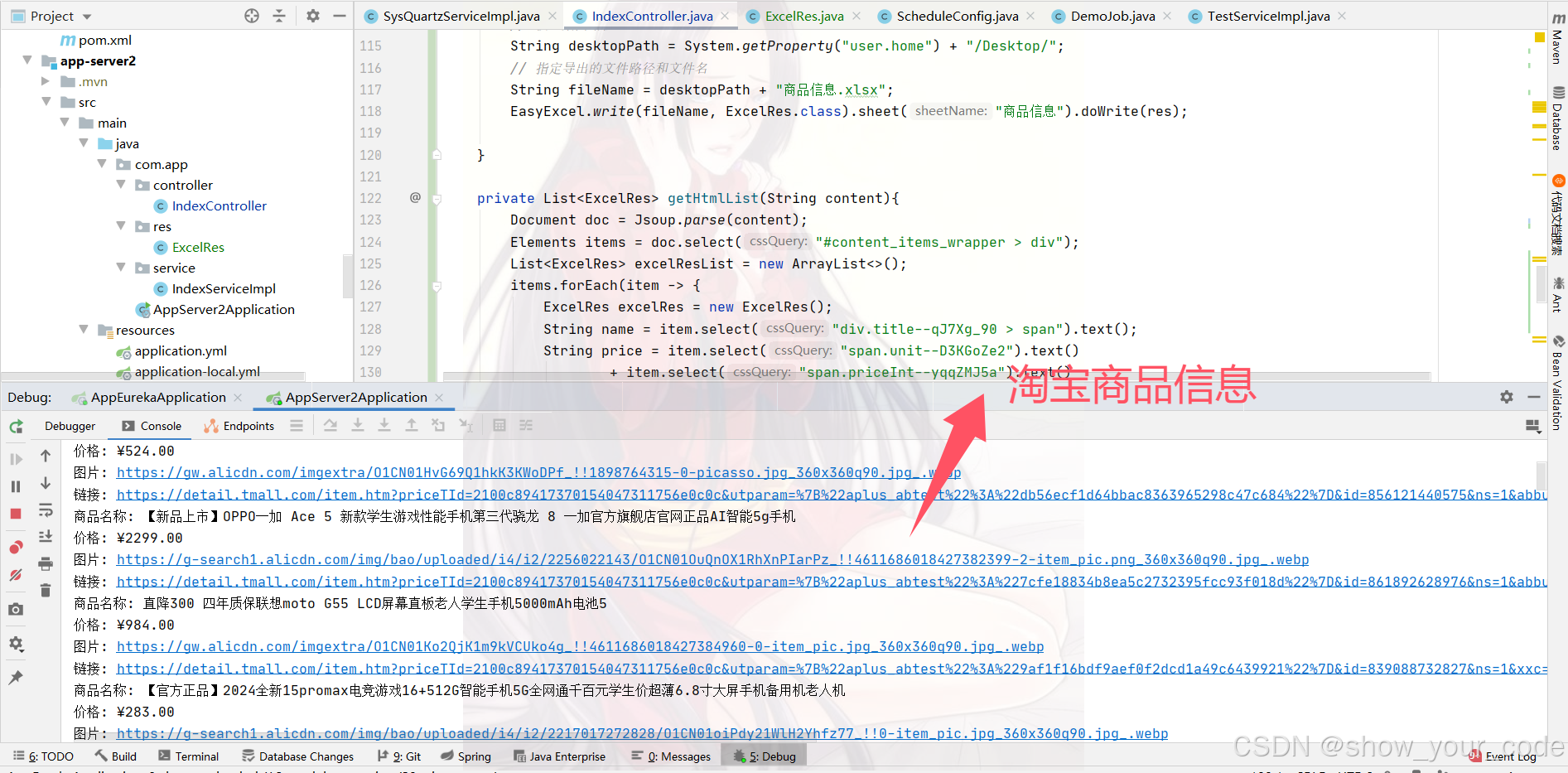
System.out.println("商品名称: " + name);
System.out.println("价格: " + price);
System.out.println("图片: " + imgUrl);
System.out.println("链接: " + url);
excelResList.add(excelRes);
});
return excelResList;
}
这里我是写了个 接口 用 postman 调用的。
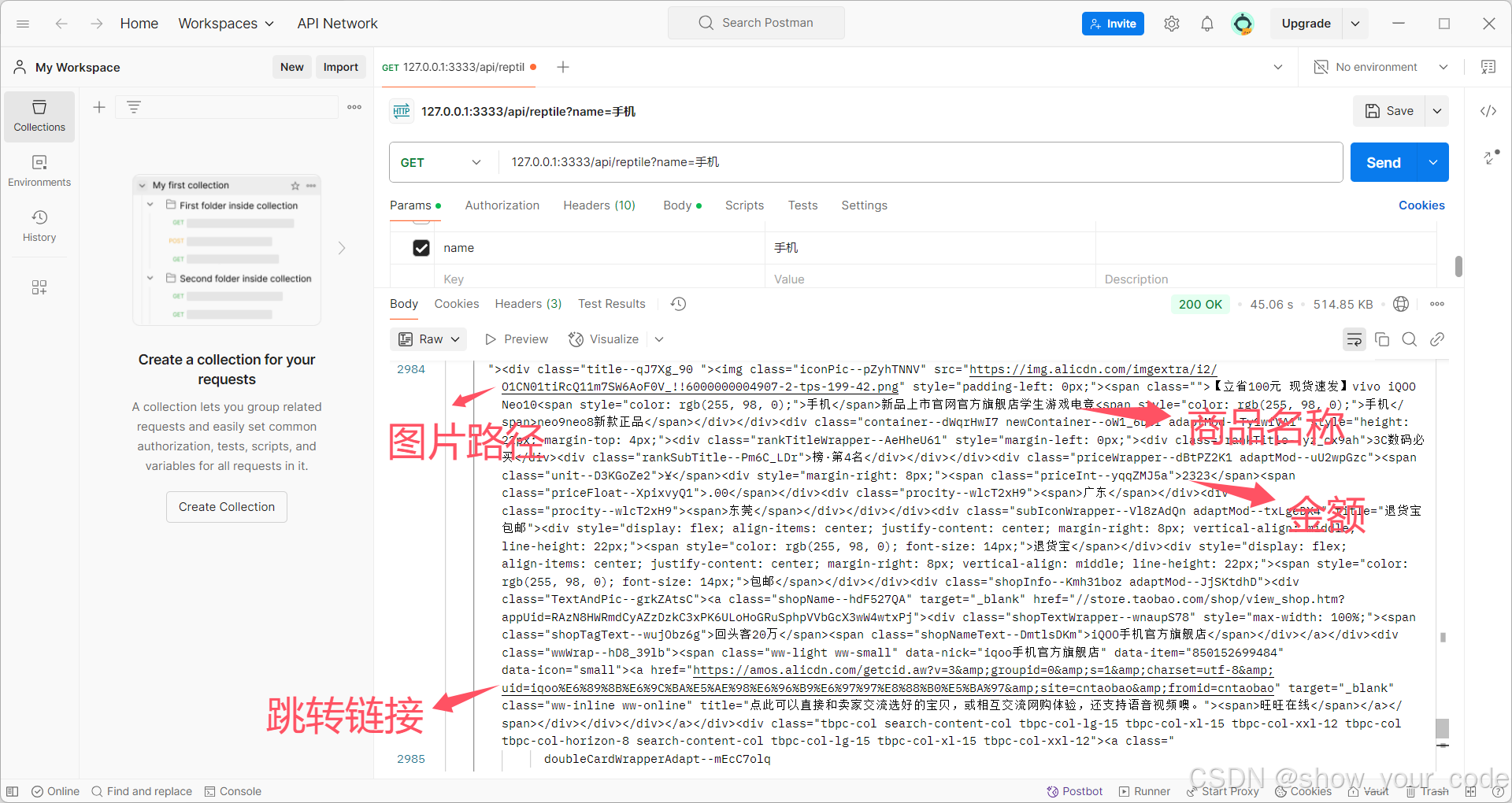
最后我们的电脑桌面 会 生成一张 excel 表格,就是我们导出来的淘宝商品 信息。。
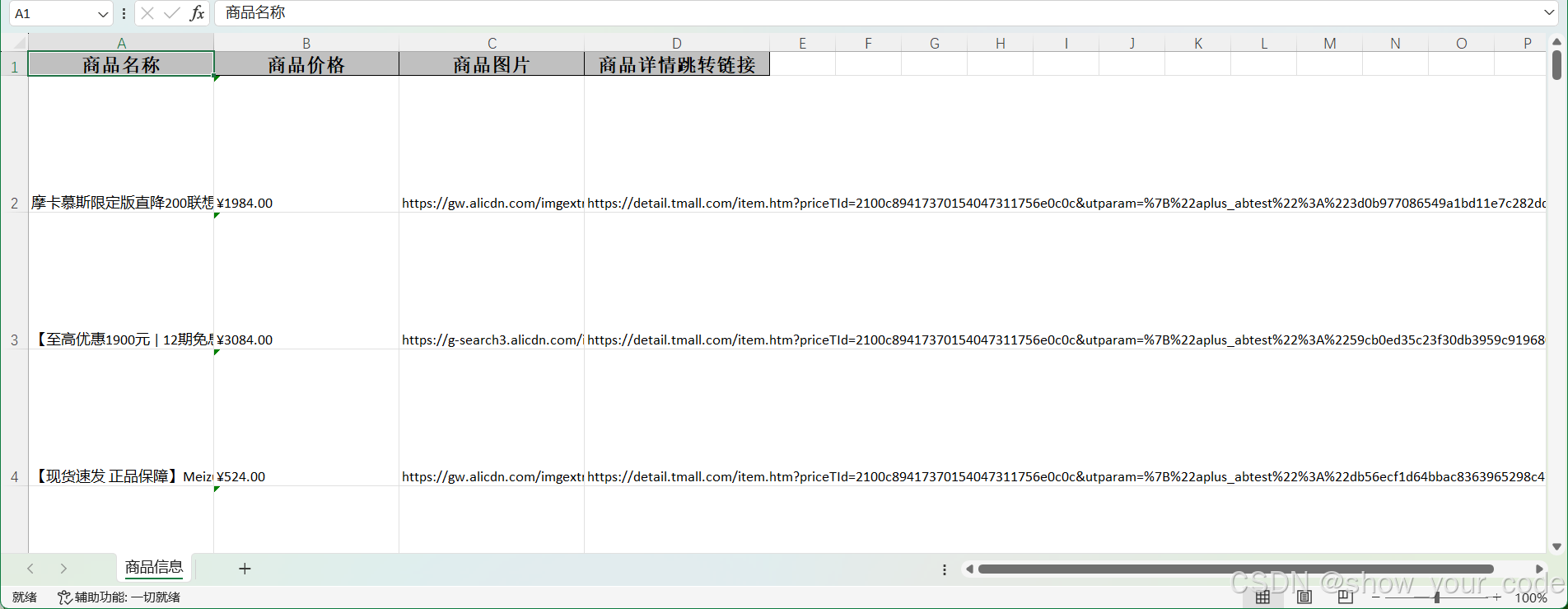
这样我们就完成了 selenium 对淘宝网站的 抓取了。 如果对各位有帮助的话记得点点赞,收藏收藏~~~~


















 1022
1022

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









