







 本文介绍了SQL Server中的GROUP BY语句,用于根据指定字段对数据进行分组,并结合COUNT等聚合函数进行统计。通过示例代码解释了如何统计表中字段重复次数,以及WHERE和HAVING子句的区别。HAVING子句用于在聚合后过滤数据,满足特定条件。注意GROUP BY需与SELECT中的所有字段对应。
本文介绍了SQL Server中的GROUP BY语句,用于根据指定字段对数据进行分组,并结合COUNT等聚合函数进行统计。通过示例代码解释了如何统计表中字段重复次数,以及WHERE和HAVING子句的区别。HAVING子句用于在聚合后过滤数据,满足特定条件。注意GROUP BY需与SELECT中的所有字段对应。
Group by语句,是SQL Server的一个分组语句。什么意思呢?分组的意思就是将一个数据集根
据指定的字段来进行区域的划分,然后划分后可以进行数据的处理。
文字说多也不好理解,直接上代码,一看就懂。
如下:我有一张表sc,里面有一个字段sno,该字段有多行重复的值。
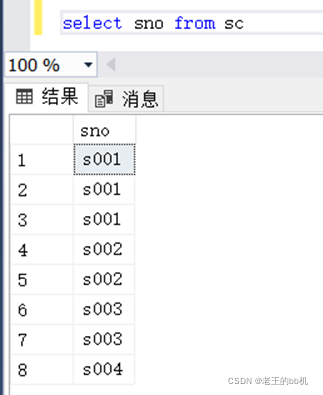
需求:我要统计sno字段中每个值重复的个数;
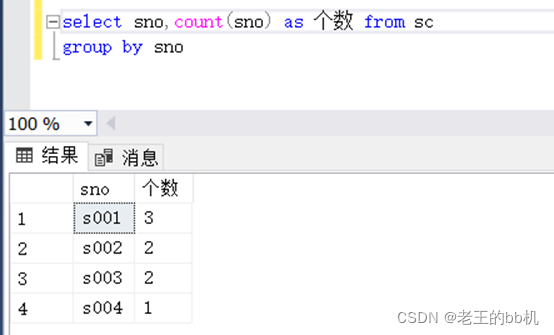
理解操作:我在查询的时候使用了group by语句。而且group by语句根据sno字段来进行分组,而后搭配聚合函数count()(统计函数)来进行个数的统计。
从上面的语句中我们不难得出group by语句的作用,group by语句就是根据select语句的字段进行划分。例如:sno字段有值‘s001’三个,那么group by语句就把这三个值为一样的划为一组。
需要注意的是,group by语句分组条件是select语句的所有字段。什么意思呢?文字看起来没有代码看起来更直观一点。废话不多说,上代码。
select sno,cno,score from sc
group by sno,cn,score
代码如上,select有三个字段,group by 同样要有三个字段。否则就会报以下错误。
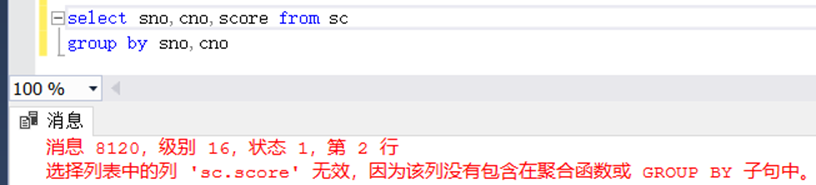
在group by语句中,是不能使用where语句的,where语句的功能全交给了having语句。原因是语句执行先后的问题。
having 语句的使用和where语句区别不大,具体使用看下面演示。
需求:求score字段的平均值大于60的
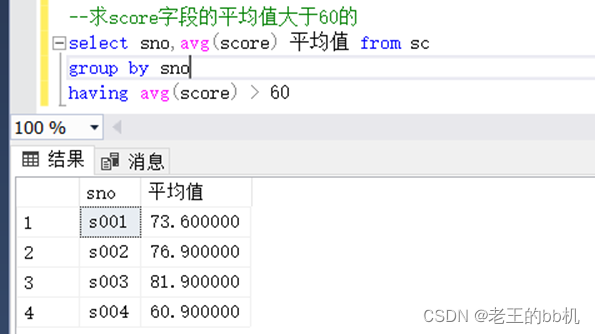
group by语句一般都是搭配聚合函数一起使用。Select语句中有聚合计算的不用在group by语句中进行分组。

















 1712
1712

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









