




为什么做监控
核心目标:保障站点可靠,从而保障业务稳定及保障业务迭代效率
什么决定了站点“可靠”:系统可用度
系统可用度取决于什么:多长时间坏一次;一旦坏了之后,多长时间可以恢复
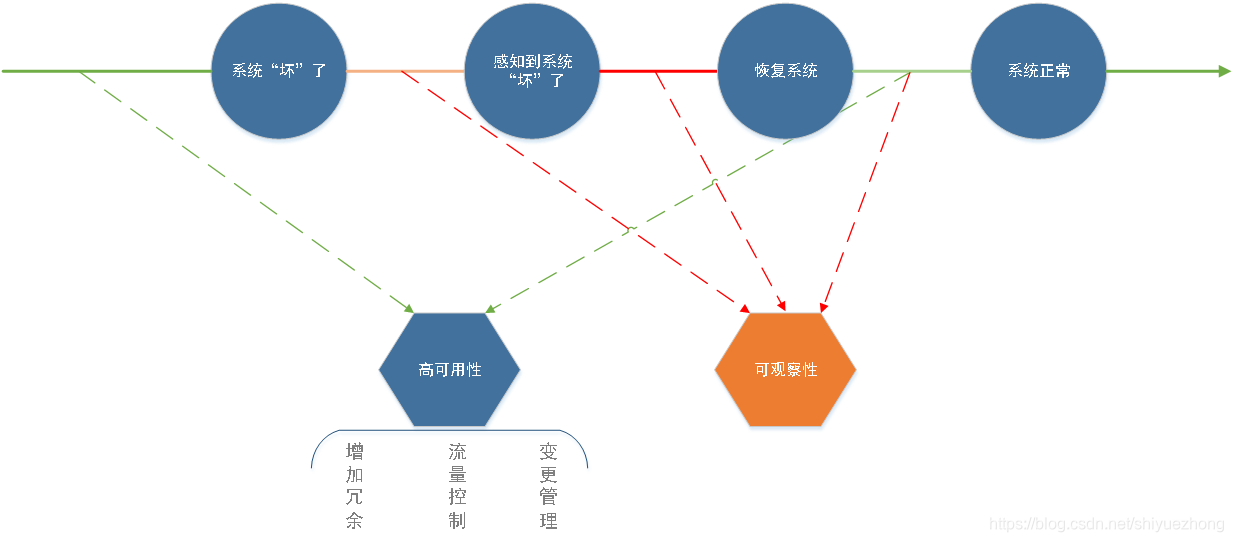
监控,即是服务于“可观察性”
覆盖面:硬件/系统级监控、应用服务指标监控、程序运行日志监控、业务监控、链路监控
关于日志监控
核心目标:程序运行日志监控,关注程序运行状态
如何做:日志的采集 -> 转换 -> 存储 ->可视化
ELK Stack:
ELK系统通常包含较多需求场景:“日志”(程序的运行信息)的监控、接口调用的指标统计分析、离线数据保存、业务数据分析等
当数据量级上来,在每个需求场景下都很难达到满意
ELK系统的需求做分化,让各自的技术方案适配各自的场景需求
ES存储日志数据成本高:尽量避免使用昂贵的全文索引或列式存储引擎来存储大量低价值的日志信息通常情况下查看频率较低
ES集群部署、扩缩容的运维成本较高
日志告警功能不完善
Loki是什么
Loki一个可水平伸缩、高可用、支持多租户的日志聚合系统。
Loki的灵感来源于Prometheus,它的设计极具成本效益并且易于操作,可以认为是日志版的Prometheus。
Loki的特殊之处
Loki不会对日志数据建立全文索引,也不支持Multiline:
取而代之的是:对非结构化的日志数据进行压缩存储并且只对日志数据的metadata(包括:时间戳、 labels等)建立索引。
存储、查询成本较低
Loki可以跟Prometheus中的监控指标进行关联:Loki可以使用与Prometheus相同的label定义和设计。
Loki的查询语法LogQL简单:日志数据查询分析心智负担低,便于在此之上建立告警统计机制
Grafana原生支持Loki:Grafana中原生支持Loki作为数据源进行查询
Loki的功能组件
Promtail、Distributor、Ingester、Querier、Query Frontend、Overrides、TableManager、RuntimeConfig
Loki的功能组件的架构
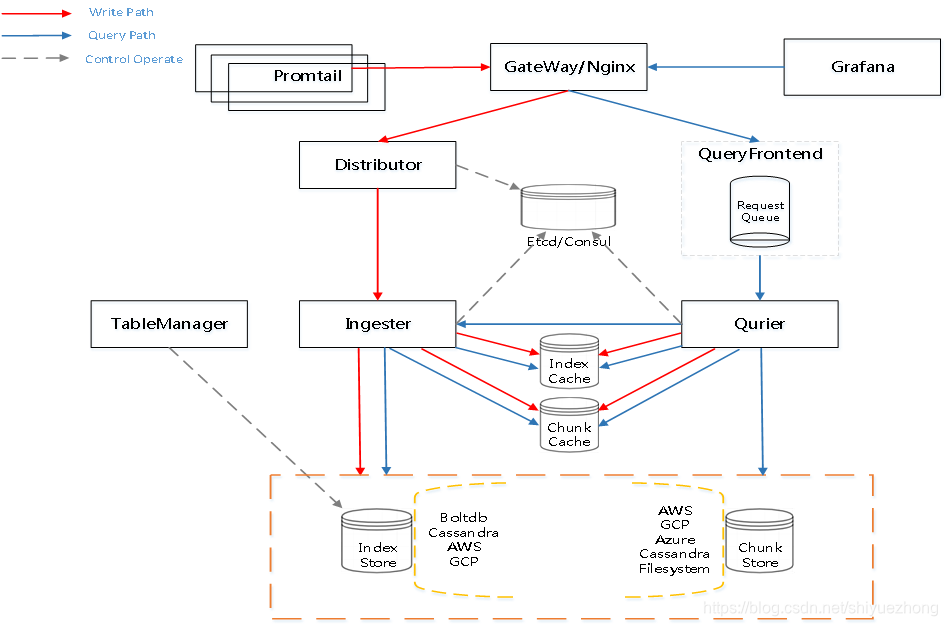
Loki的功能组件-Promtail
日志数据:采集、提取、匹配、过滤、打Labels、批量Push To Loki
支持的采集方式:File Traget、Journal Traget、Syslog Traget、Stdin Traget
Loki的功能组件-Promtail-处理流程
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1371
1371

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









