




 本文探讨了机器学习中训练数据的重要性和治理原则,包括数据量越大越好、准备过程耗时、以及单纯增加人力并不一定能提高数据质量。强调了数据质量和准确性对模型效果的关键作用,并介绍了世平信息在数据安全、治理和共享方面的解决方案。
本文探讨了机器学习中训练数据的重要性和治理原则,包括数据量越大越好、准备过程耗时、以及单纯增加人力并不一定能提高数据质量。强调了数据质量和准确性对模型效果的关键作用,并介绍了世平信息在数据安全、治理和共享方面的解决方案。

什么是数据治理
机器学习是一类算法的总称,这些算法企图从大量历史数据中挖掘出其中隐含的规律,并用于预测或者分类。
机器学习的核心是“使用算法解析数据,从中学习,然后对世界上的某件事情做出决定或预测”。
机器学习的目标是使学到的函数很好地适用于“新样本”,而不仅仅是在训练样本上表现很好。
所谓的训练数据,就是经过预处理(一般是人工标注)后,有相对稳妥、精确的特征描述的数据集,以“样本”形式参与模型开发工作。
训练数据选择一般有以下要求:数据样本尽可能大、数据多样化,数据样本质量较高。
在
在准备训练数据时,
需要把握这样几个原则。
01
训练数据越多越好
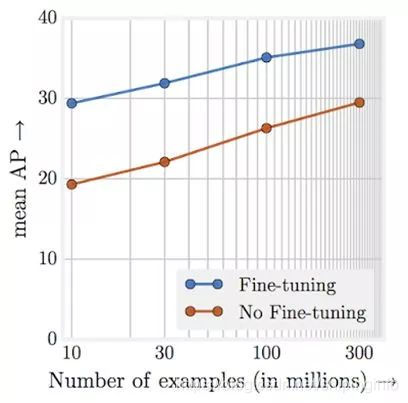
这张图片来自“重新审视那些有效到不合常理的训练数据”,并且展示了即使数据集已经增长到了数亿,图像分类模型的精度依然不断增加。
Facebook最近更加深入的使用大数据量,例如,在ImageNet分类中使用了数十亿个带有标签的Instagram
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 4万+
4万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









