







一、什么是LOGMNR
LOGMNR包是达梦数据库的日志分析工具,达梦提供了JNI接口和C接口,挖掘获取数据库系统的历史执行语句,供应用程序直接调用。
用户可以使用DBMS_LOGMNR包对归档日志进行挖掘,重构出DDL和DML等操作,并通过获取的信息进行更深入的分析。物理逻辑日志,是按照特定的格式存储的服务器的逻辑操作,专门用于DBMS_LOGMNR包挖掘获取数据库系统的历史执行语句。当开启记录物理逻辑日志的功能时,这部分日志内容会被存储在重做日志文件中。要开启物理逻辑日志的功能,需要满足下面两个条件:首先,要设置RLOG_APPEND_LOGIC为1、2、3或者4;其次,通过设置参数RLOG_IGNORE_TABLE_SET=1或者建表(或修改表)时指定ADD
LOGIC LOG开启。如果需要记录所有表的物理逻辑日志,设置INI参数RLOG_IGNORE_TABLE_SET为1即可;如果只需要记录某些表的物理逻辑日志,设置INI参数RLOG_IGNORE_TABLE_SET为0,并在建表或者修改表的语法中使用ADD LOGIC LOG。
目前DBMS_LOGMNR只支持对归档日志进行分析,DM MPP环境下不支持DBMS_LOGMNR包。DMDPC使用DBMS_LOGMNR时,DBMS_LOGMNR.ADD_LOGFILE只能添加同一个节点的多个日志同时进行分析,不支持同时分析不同节点的日志。
在达梦早期版本中没有LOGMNR功能或只能在主库执行LOGMNR操作,在新的版本中,支持在达梦备库执行LOGMNR,以减少对主库操作的影响。本文以8.1.3.162版本为例,该版本支持在备库执行LOGMNR操作。
logmnr.jar包是达梦数据库的日志分析工具的JNI接口,供应用程序直接调用。
一般调用过程如下:(1)初始化LOGMNR环境;(2)创建一个分析日志的连接;(3)添加需要分析的日志文件;(4)启动日志文件分析;(5)获取完成分析的日志数据;(6)终止日志文件分析;(7)关闭当前连接;(8)清理LOGMNR环境。
二、LOGMNR涉及到的参数
| 参数名 | 默认值 | 属性 | 参数说明 |
| RLOG_APPEND_LOGIC | 0 | 动态,系统级 | 是否启用在日志中记录逻辑操作的功能,取值范围0、1、2、3、4 0:不启用;1、2、3、4启用。 1:如果有主键列,记录UPDATE和DELETE操作时只包含主键列信息,若没有主键列则包含所有列信息; 2:不论是否有主键列,记录UPDATE和DELETE操作时都包含所有列的信息; 3:记录UPDATE时包含更新列的信息以及ROWID,记录DELETE时只有ROWID; 4:只生成事务以及DDL相关的逻辑日志 |
| RLOG_IGNORE_TABLE_SET | 1 | 动态,系统级 | 是否开启记录物理逻辑日志功能。1是,0否 |
| LOGMNR_PARSE_LOB | 0 | 动态,系统级 | LOGMNR包是否支持挖掘行外大字段逻辑日志。0:不支持;1:支持 |
-
三、LOGMNR涉及到的视图
V$LOGMNR_LOGS:显示当前会话添加的需要分析的归档日志文件。
V$LOGMNR_PARAMETERS:显示当前会话START_LOGMNR启动日志文件分析的参数。
V$LOGMNR_CONTENTS:显示当前会话日志分析的内容。
四、DBMS_LOGMNR包涉及的方法
DBMS_LOGMNR.ADDFILE:在当前LOGMNR中增加日志文件(如果已经START,则不可增加)。DBMS_LOGMNR.REMOVEFILE:从日志列表中移除某个日志文件。
DBMS_LOGMNR.COLUMN_PRESENT:判断某列是否被包含在指定的一行逻辑记录中。DBMS_LOGMNR.END_LOGMNR:结束LOGMNR。
DBMS_LOGMNR.MINE_VALUE:以字符串的格式来获取某一条日志中包含的指定列的值。DBMS_LOGMNR.START_LOGMNR:根据指定的模式和条件来开始某个会话上的LOGMNR,一个会话上仅能START一个LOGMNR。
以上包的详细使用方法可以参考DM8系统管理员手册。
-
五、DBMS_LOGMNR使用示例
5.1创建系统包
使用包内的过程和函数之前,如果还未创建过系统包。请先调用系统过程创建系统包。
SP_CREATE_SYSTEM_PACKAGES (1,'DBMS_LOGMNR'); --主库执行
[dmdba@chctdb1 ~/dmdbms/bin]$ ./disql SYSDBA/SYSDBA
服务器[LOCALHOST:5236]:处于主库打开状态
登录使用时间 : 5.263(ms)
disql V8
SQL> SP_CREATE_SYSTEM_PACKAGES(1,'DBMS_LOGMNR');
DMSQL 过程已成功完成
已用时间: 49.912(毫秒). 执行号:1401.
SQL> exit
[dmdba@chctdb1 ~/dmdbms/bin]$ ./disql SYSDBA/SYSDBA
服务器[LOCALHOST:5236]:处于主库打开状态
登录使用时间 : 2.444(ms)
disql V8
SQL> set linesize 200;
SQL> set pagesize 200;
SQL> SELECT INSTANCE_NAME,STATUS$,MODE$ FROM SYS.V$INSTANCE;
行号 INSTANCE_NAME STATUS$ MODE$
---------- ------------- ------- -------
1 HISOFT OPEN PRIMARY
已用时间: 1.415(毫秒). 执行号:1501.
SQL> SP_CREATE_SYSTEM_PACKAGES(1,'DBMS_LOGMNR');
DMSQL 过程已成功完成
已用时间: 46.990(毫秒). 执行号:1502.
SQL>
5.2修改dm.ini中的参数
ARCH_INI = 1
RLOG_APPEND_LOGIC = 4
RLOG_IGNORE_TABLE_SET=1
SP_SET_PARA_VALUE(1,'RLOG_APPEND_LOGIC',4);
SP_SET_PARA_VALUE(1,'RLOG_IGNORE_TABLE_SET',1);
more dm.ini | grep -E "ARCH_INI|RLOG_APPEND_LOGIC|RLOG_IGNORE_TABLE_SET"
5.3写入数据测试
在主库执行
(1)创建表BOOKS
CREATE TABLE BOOKS(BOOK_ID VARCHAR2(4),BOOK_NAME VARCHAR2(50),PRICE VARCHAR2(5),QTY VARCHAR2(4),PUB VARCHAR2(50));
INSERT INTO BOOKS VALUES('0001','中国文学','39','12','人民文学');
INSERT INTO BOOKS VALUES('0002','外国文学','27','10','人民文学');
COMMIT;
删除表
SELECT COUNT(1) FROM "SYSDBA"."BOOKS";
TRUNCATE TABLE "SYSDBA"."BOOKS";
DELETE FROM "SYSDBA"."BOOKS";
COMMIT;
(2)创建COURSE表
CREATE TABLE COURSE
(CNO VARCHAR(6) NOT NULL,
CNAME VARCHAR(30) NOT NULL,
PRIMARY KEY(CNO)
);
COMMENT ON TABLE COURSE IS '课程表';
COMMENT ON COLUMN "COURSE"."CNO" IS '课程号';
COMMENT ON COLUMN "COURSE"."CNAME" IS '课程名';
插入数据
INSERT INTO COURSE VALUES('100201','语文');
INSERT INTO COURSE VALUES('100202','数学');
INSERT INTO COURSE VALUES('100203','英语');
INSERT INTO COURSE VALUES('100204','政治');
INSERT INTO COURSE VALUES('100205','科学');
COMMIT;
更新数据
UPDATE COURSE SET CNAME='艺术' WHERE CNO='100205';
COMMIT;
SELECT * FROM "SYSDBA"."COURSE";
SELECT COUNT(1) FROM "SYSDBA"."COURSE";
5.4查询有哪些归档日志
在备库执行
SELECT NAME,FIRST_TIME,NEXT_TIME,FIRST_CHANGE#,NEXT_CHANGE# FROM V$ARCHIVED_LOG;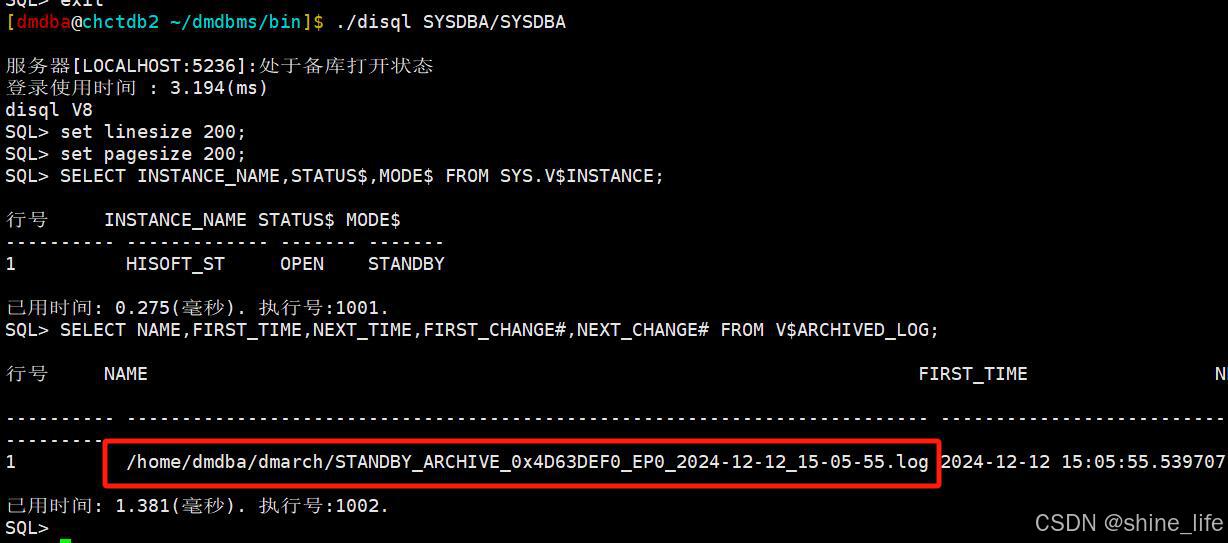
5.5添加一个或多个需要分析的归档文件
在备库执行
DBMS_LOGMNR.ADD_LOGFILE('/home/dmdba/dmarch/STANDBY_ARCHIVE_0x4D63DEF0_EP0_2024-12-12_15-05-55.log');
DMSQL 过程已成功完成
已用时间: 4.694(毫秒). 执行号:1003.
SQL>
5.6查询等待分析的归档日志文件
在备库执行。如果要查看通过ADD_LOGFILE添加的归档日志文件,可以通过动态视图V$LOGMNR_LOGS进行查询,如下:SELECT LOW_SCN,NEXT_SCN,LOW_TIME, HIGH_TIME,LOG_ID,FILENAME FROM V$LOGMNR_LOGS; 
5.7启动归档日志文件分析
在备库执行。
DBMS_LOGMNR.START_LOGMNR(OPTIONS=>2130,STARTTIME=>TO_DATE('2024-12-31 00:00:00','YYYY-MM-DD HH24:MI:SS'), ENDTIME =>TO_DATE('2024-12-31 23:59:59','YYYY-MM-DD HH24:MI:SS'));
可以通过STARTTIME和ENDTIME,分析某个具体时间的归档日志文件。
OPTIONS详细说明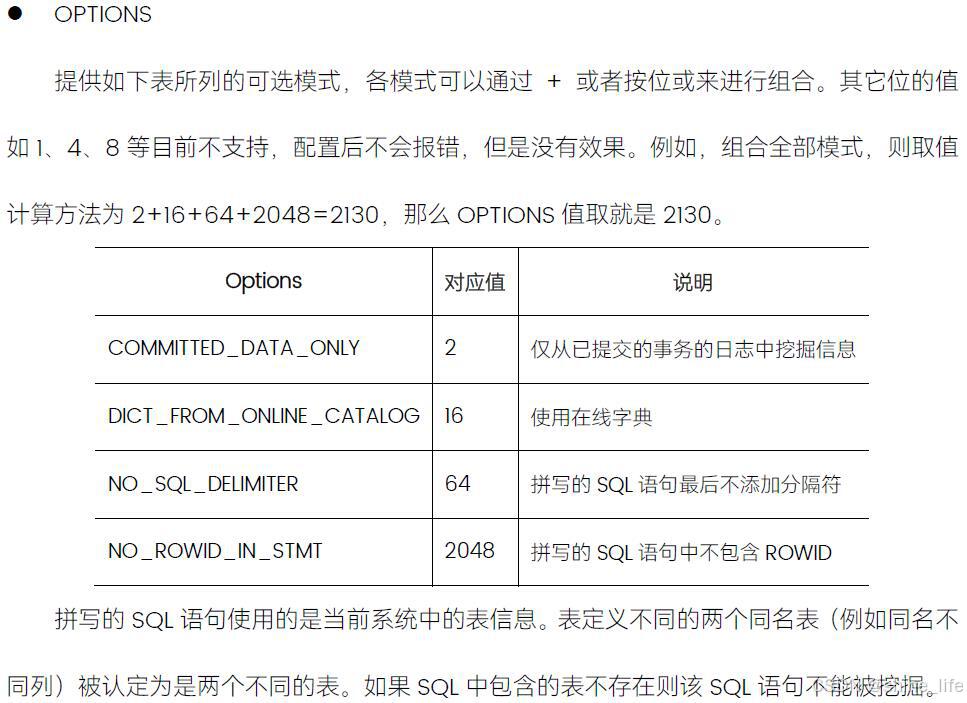
或者DBMS_LOGMNR.START_LOGMNR(OPTIONS=>2130);
5.8查看归档分析结果
在备库执行。如要查看归档日志文件的分析结果,可以通过动态视图 V$LOGMNR_CONTENTS进行查询,如下:
SELECT OPERATION_CODE,
SCN,
SQL_REDO,
TIMESTAMP,
SEG_OWNER,
TABLE_NAME
FROM V$LOGMNR_CONTENTS
WHERE SEG_OWNER = 'SYSDBA'
AND OPERATION_CODE IN (1,2,3,4,5,6,7)
ORDER BY OPERATION_CODE;
创建和删除SQL语句。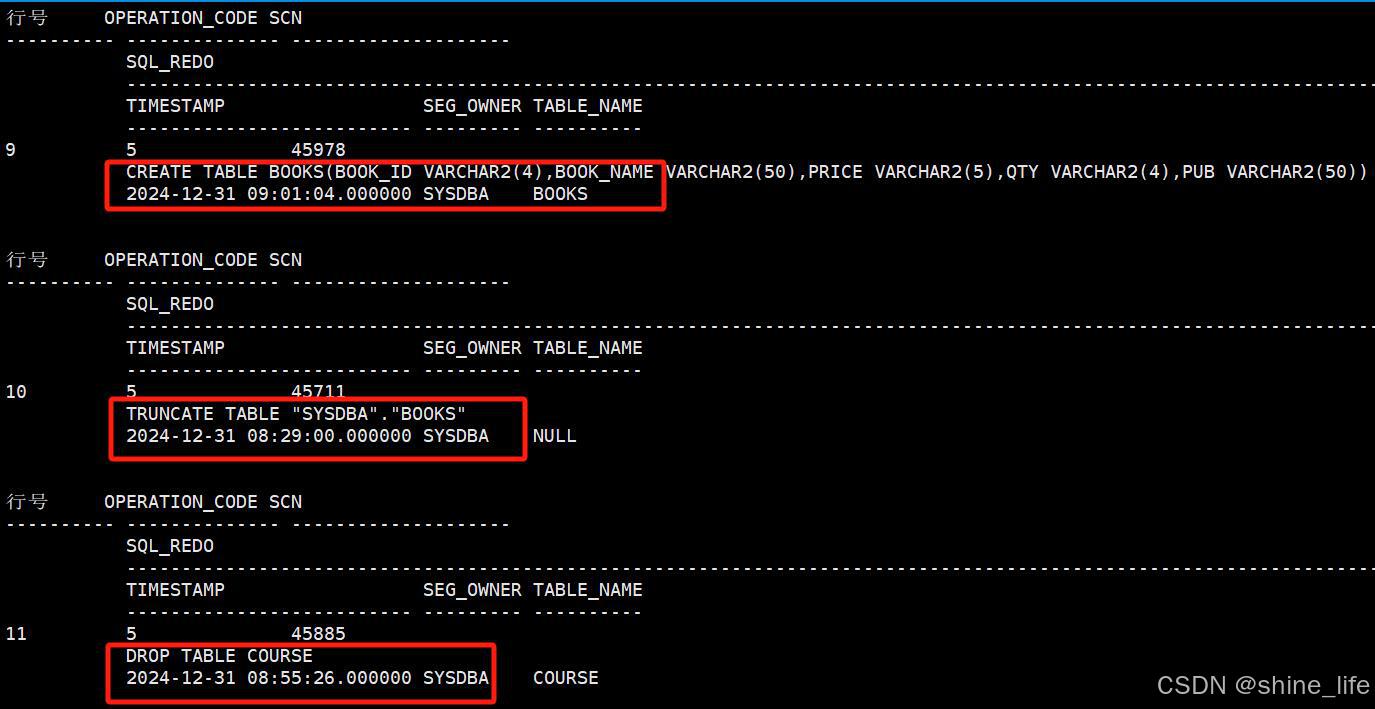
插入和更新SQL语句。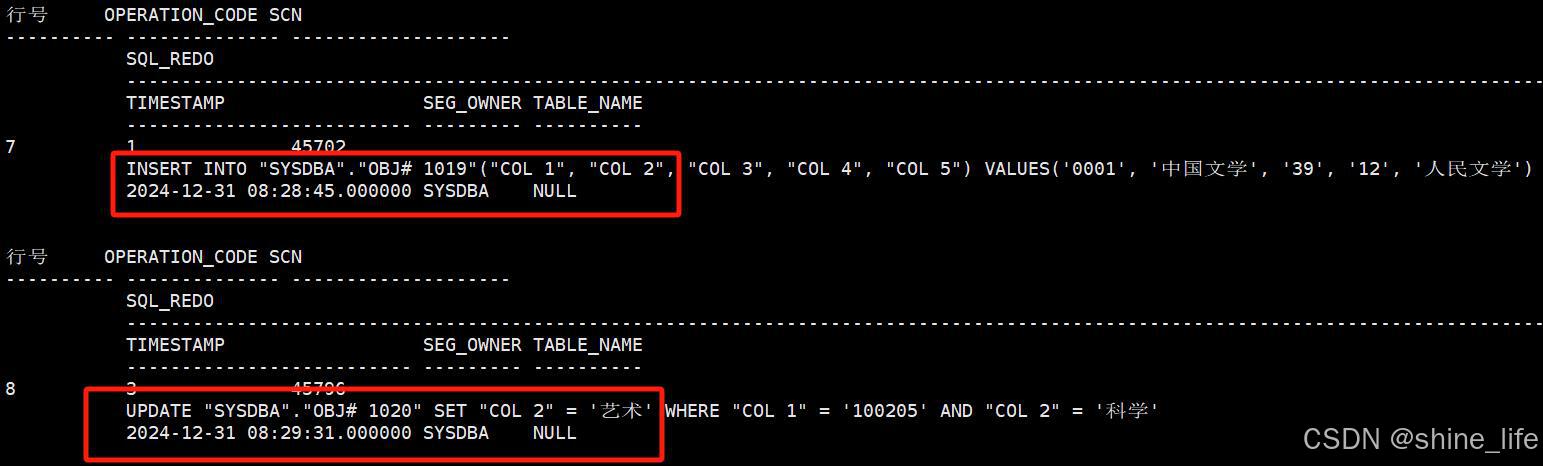
5.9终止LOGMNR日志文件分析
在备库执行,DBMS_LOGMNR.END_LOGMNR();
SQL> DBMS_LOGMNR.END_LOGMNR();
DMSQL 过程已成功完成
已用时间: 0.555(毫秒). 执行号:1411.
SQL>

















 995
995

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









