




 本文详细解析了Golang中Map的内部结构,包括hmap和bmap的使用,以及初始化、数据写入/读取、扩容和迁移的过程,重点讲解了不同情况下扩容策略的调整。
本文详细解析了Golang中Map的内部结构,包括hmap和bmap的使用,以及初始化、数据写入/读取、扩容和迁移的过程,重点讲解了不同情况下扩容策略的调整。
概要
Golang中的Map有一套自己的实现原理,其核心是由 hmap 和 bmap 两个结构体实现
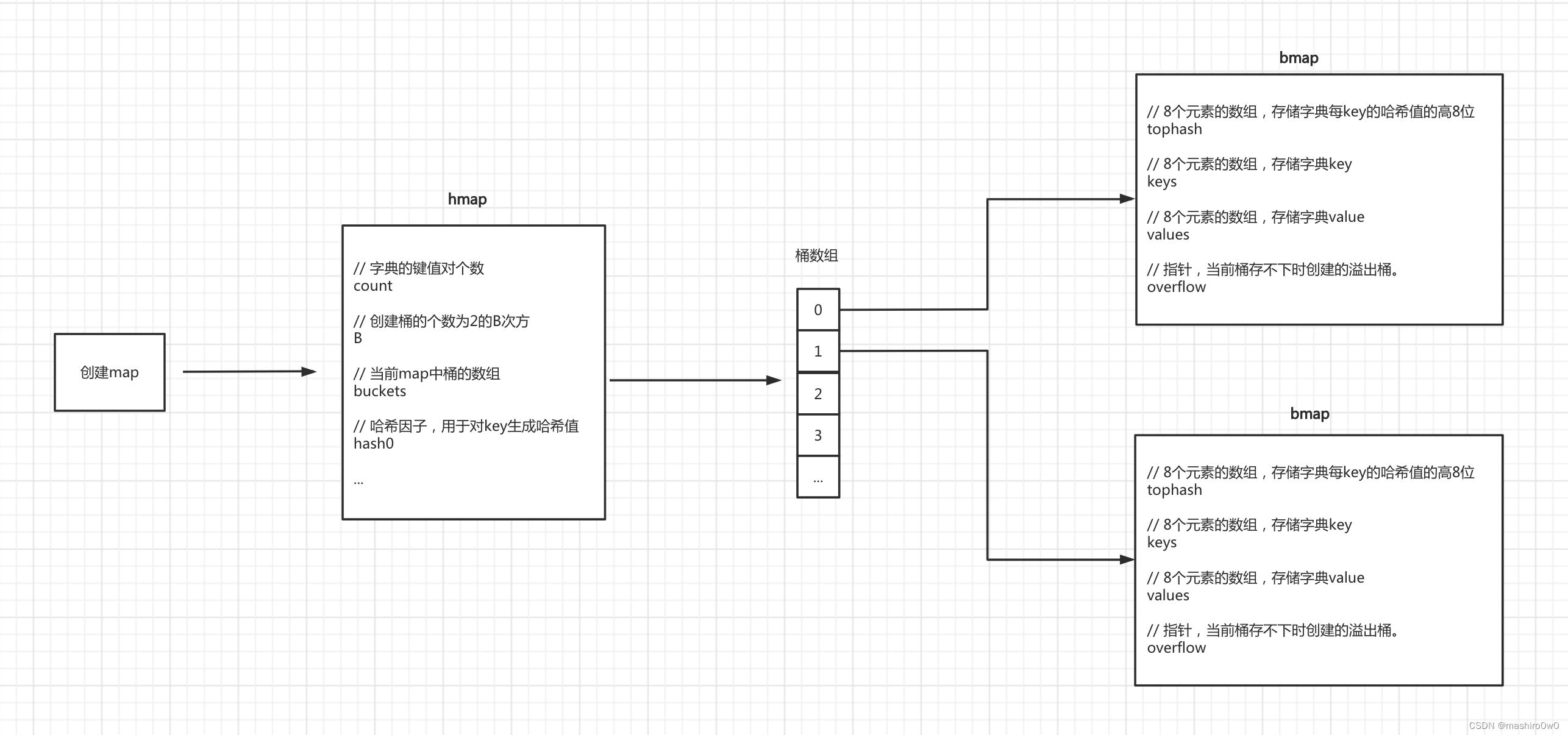
初始化
//初始化一个可容纳10个元素的map
info = make(map[string]string,10)
- 第一步:创建一个hmap结构体对象
- 第二步:生成一个哈希因子hash0并复制到hmap对象中(用于后续为key创建哈希值)
- 第三步:根据hint=10,并根据算法规划来创建B,当前B应该为1
hint B
0~8 0
9~13 1
14~26 2
...
- 第四步:根据B去创建桶(bmap对象)并存放在buckets数组中,当前bmap的数量应为2
当B<4时,根据B创建桶的个数的规则为:
2
B
2^B
2B(标准桶)
-当B>=4时,根据B创建桶的个数的规则为:
2
B
2^B
2B +
2
B
−
4
2^{B-4}
2B−4(标准桶+溢出桶)
注意:每个bmap中可以存储8个键值对,当不够存储时需要使用溢出桶,并将当前bmap中的overflow字段指向溢出桶的位置
写入数据
info["name"]= "mashiro"
在map中写入数据时,内部的执行流程是:
- 第一步:结合哈希因子和键name生成哈希值0110111000111111110101010
- 第二步:获取哈希值的后八位,并根据后B位的值来确定将此键值对存放在那个桶中(bmap)
将哈希值和桶掩码(B个为1的二进制)进行 & 运算,最终得到哈希值的后B位的值。假设当B为1时,其结果为 0 :
哈希值:011011100011111110111011010
桶掩码:000000000000000000000000001
结果: 000000000000000000000000000 = 0
通过示例你会发现,找桶的原则实际上是根据后B为的位运算计算出 索引位置,然后再去buckets数组中根据索引找到目标桶(bmap)。
- 第三步:在上一步确定桶以后,接下来就在桶中写入数据
获取哈希值的tophash(即:哈希值的`高8位`),将tophash、key、value分别写入到桶中的三个数组中。
如果桶已满,则通过overflow找到溢出桶,并在溢出桶中继续写入。
注意:以后在桶中查找数据时,会基于tophash来找(tophash相同则再去比较key)。
- 第四步:hmap的个数count++(map中的元素个数+1)
读取数据
value := info["name"]
在map中读取数据时,内部的执行流程是:
- 第一步:结合哈希引子和键name生成哈希值
- 第二步:获取哈希值的后B位,并根据后B位的值来决定将此键值对存放到那个桶(bmap)
- 第三步:确定桶之后,再根据key的哈希值计算出tophash(高8位),根据tophash和key去桶中查找数据.
当前桶如果没找到,则根据overflow再去溢出桶中找,均为找到则表示key不存在
扩容
在向map中添加数据时,当达到某个条件,则会引发字典扩容
扩容条件:
- map中数据总个数/桶个数 > 6.5,引发翻倍扩容。
- 使用了太多的溢出桶时(溢出桶使用的太多会导致map处理速度降低)
- B <=15,已使用的溢出桶个数 >= 2 B 2^B 2B 时,引发等量扩容。
- B > 15,已使用的溢出桶个数 >= 2 15 2^{15} 215 时,引发等量扩容。
func hashGrow(t *maptype, h *hmap) {
// If we've hit the load factor, get bigger.
// Otherwise, there are too many overflow buckets,
// so keep the same number of buckets and "grow" laterally.
bigger := uint8(1)
if !overLoadFactor(h.count+1, h.B) {
bigger = 0
h.flags |= sameSizeGrow
}
oldbuckets := h.buckets
newbuckets, nextOverflow := makeBucketArray(t, h.B+bigger, nil)
...
}
- 第一步:B会根据扩容后新桶的个数进行增加(翻倍扩容新B=旧B+1,等量扩容 新B=旧B)。
- 第二步:oldbuckets指向原来的桶(旧桶)。
- 第三步:buckets指向新创建的桶(新桶中暂时还没有数据)。
- 第四步:nevacuate设置为0,表示如果数据迁移的话,应该从原桶(旧桶)中的第0个位置开始迁移。
- 第五步:noverflow设置为0,扩容后新桶中已使用的溢出桶为0。
- 第六步:extra.oldoverflow设置为原桶(旧桶)已使用的所有溢出桶。即:
h.extra.oldoverflow = h.extra.overflow - 第七步:extra.overflow设置为nil,因为新桶中还未使用溢出桶。
- 第八步:extra.nextOverflow设置为新创建的桶中的第一个溢出桶的位置。
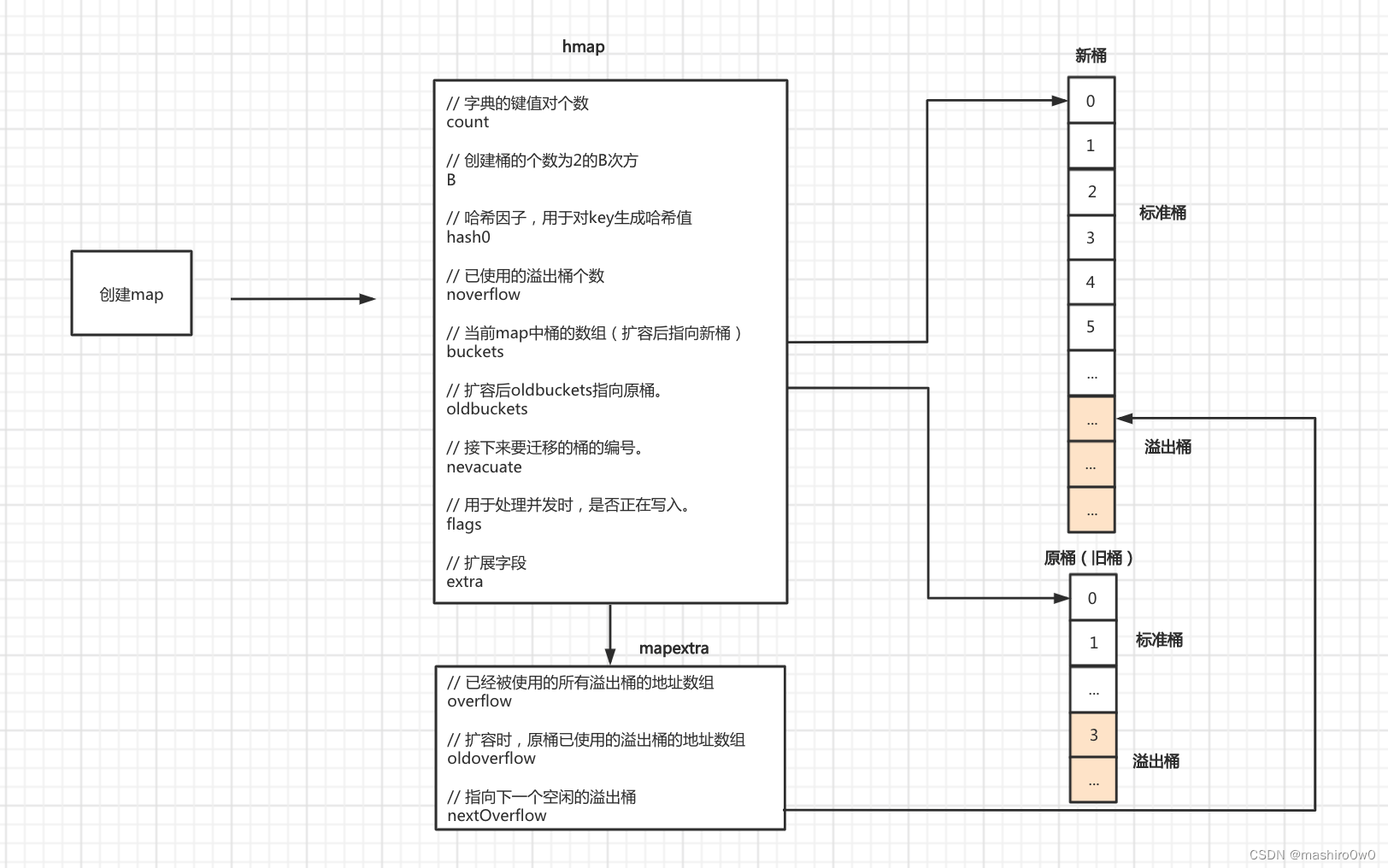
迁移
扩容之后,必然要伴随着数据的迁移,即:将旧桶中的数据要迁移到新桶中
翻倍扩容
如果是翻倍扩容,那么迁移规就是将旧桶中的数据分流至新的两个桶中(比例不定),并且桶编号的位置为:同编号位置 和 翻倍后对应编号位置。
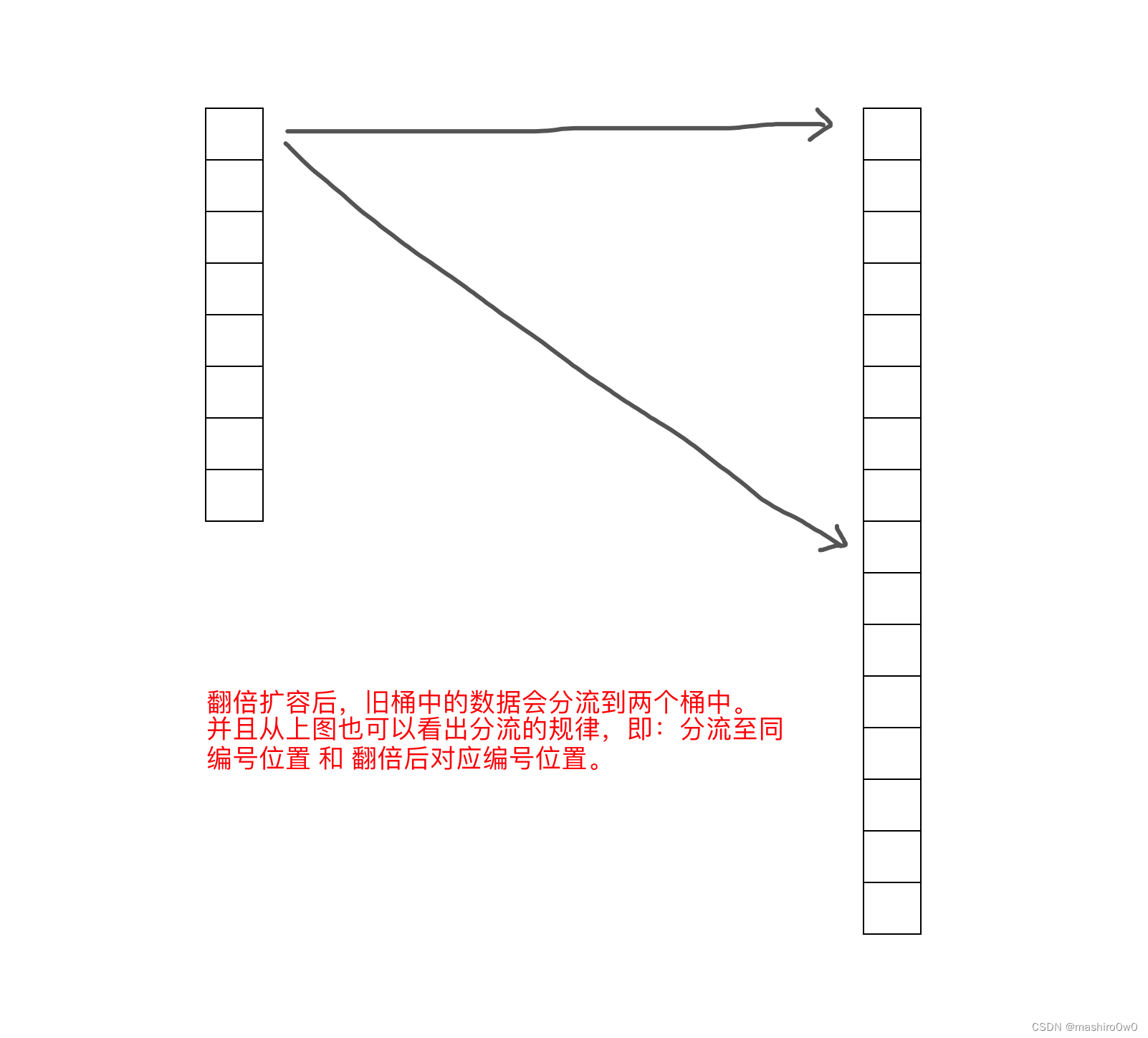
那么问题来了,如何实现的这种迁移呢?
首先,我们要知道如果翻倍扩容(数据总个数 / 桶个数 > 6.5),则新桶个数是旧桶的2倍,即:map中的B的值要+1(因为桶的个数等于
2
B
2^B
2B,而翻倍之后新桶的个数就是
2
B
2^B
2B * 2 ,也就是
2
B
+
1
2^{B+1}
2B+1,所以 新桶的B的值=原桶B + 1 )。
迁移时会遍历某个旧桶中所有的key(包括溢出桶),并根据key重新生成哈希值,根据哈希值的 底B位 来决定将此键值对分流道那个新桶中。
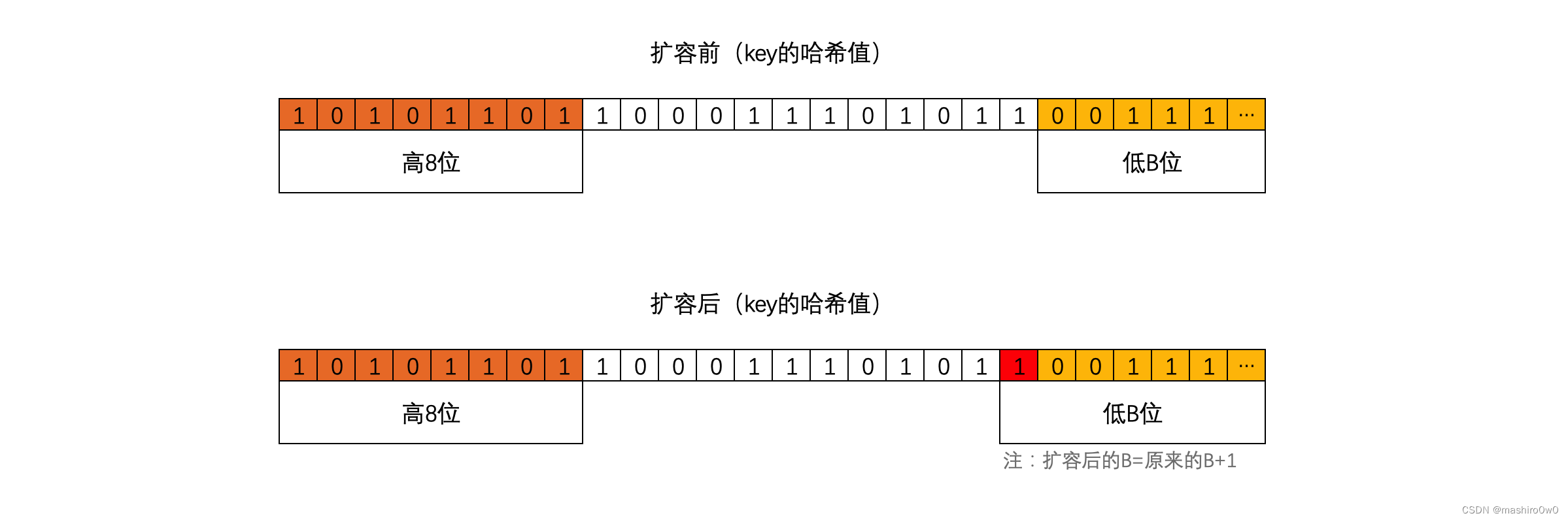
扩容后,B的值在原来的基础上已加1,也就意味着通过多1位来计算此键值对要分流到新桶位置,如上图:
- 当新增的位(红色)的值为 0,则数据会迁移到与旧桶编号一致的位置。
- 当新增的位(红色)的值为 1,则数据会迁移到翻倍后对应编号位置。
例如:
旧桶个数为32个,翻倍后新桶的个数为64。
在重新计算旧桶中的所有key哈希值时,红色位只能是0或1,所以桶中的所有数据的后B位只能是以下两种情况:
- 000111【7】,意味着要迁移到与旧桶编号一致的位置。
- 100111【39】,意味着会迁移到翻倍后对应编号位置。
特别提醒:同一个桶中key的哈希值的低B位一定是相同的,不然不会放在同一个桶中,所以同一个桶中黄色标记的位都是相同的。
等量扩容
如果是等量扩容(溢出桶太多引发的扩容),那么数据迁移机制就会比较简单,就是将旧桶(含溢出桶)中的值迁移到新桶中。
这种扩容和迁移的意义在于:当溢出桶比较多而每个桶中的数据又不多时,可以通过等量扩容和迁移让数据更紧凑,从而减少溢出桶

















 597
597

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









