




1.简介
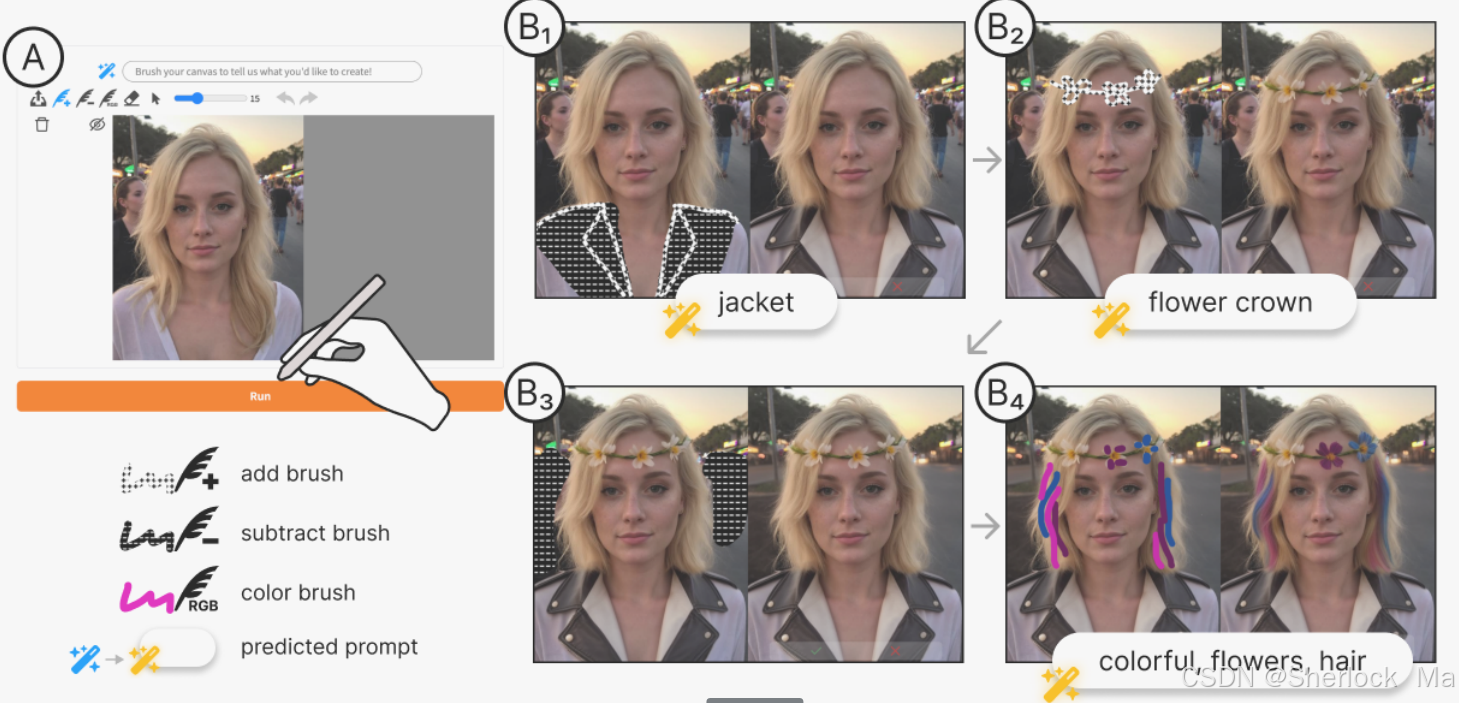
MagicQuill是一个创新的智能互动图像编辑系统,它通过结合扩散模型和多模态大型语言模型(MLLM),使用户能够以直观的笔触编辑图像,如添加、减去元素或改变颜色。
这个系统通过实时监测用户的笔触并预测其意图,省去了传统编辑中输入复杂指令的步骤,使得编辑过程更加流畅和高效。
它由三个核心模块组成:编辑处理器、绘画助手和想法收集器。编辑处理器负责精确控制图像的编辑,确保用户意图在颜色和边缘调整中得到准确反映;绘画助手通过解读笔触和自动预测提示来减少用户的工作量;而想法收集器则提供了一个用户友好的界面,使用户可以轻松地绘制和操作笔触。MagicQuill的设计旨在简化图像编辑流程,提高编辑的精确度和效率,同时降低专业图像编辑的门槛,让创意表达变得更加容易和高效。
项目主页:MagicQuill
论文地址:https://arxiv.org/abs/2411.09703
huggingface demo:Gradio
视频介绍:https://www.youtube.com/watch?v=5DiKfONMnE4
2.效果展示
这里是使用MagicQuill生成的图像,使用教程请看第四章。
官方效果图:
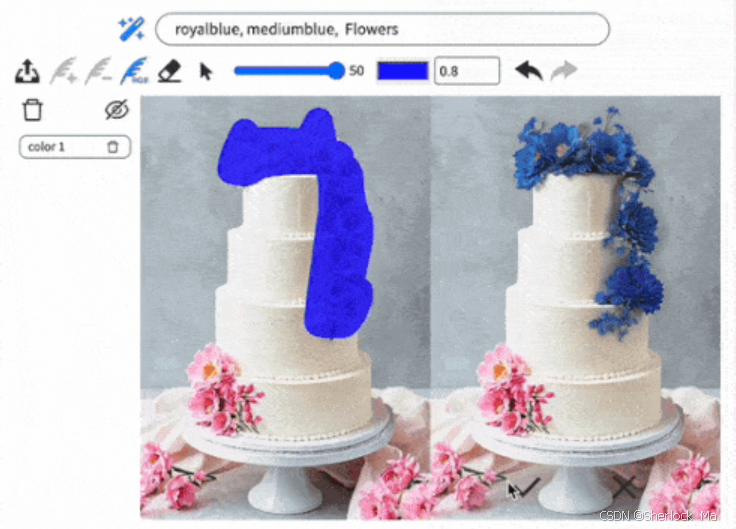
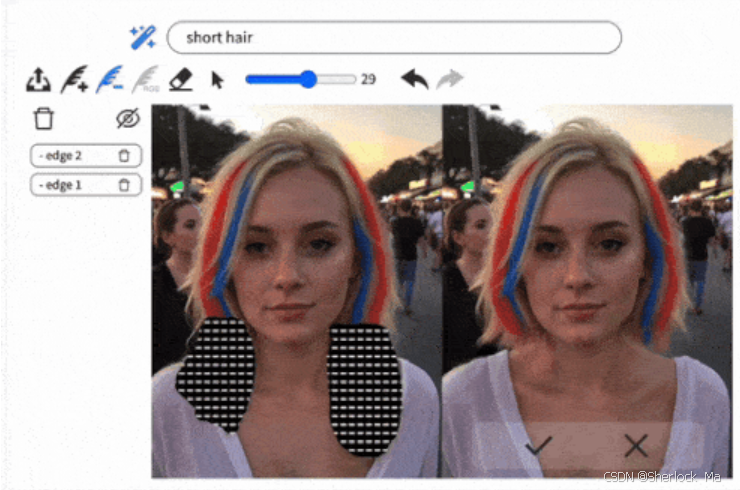
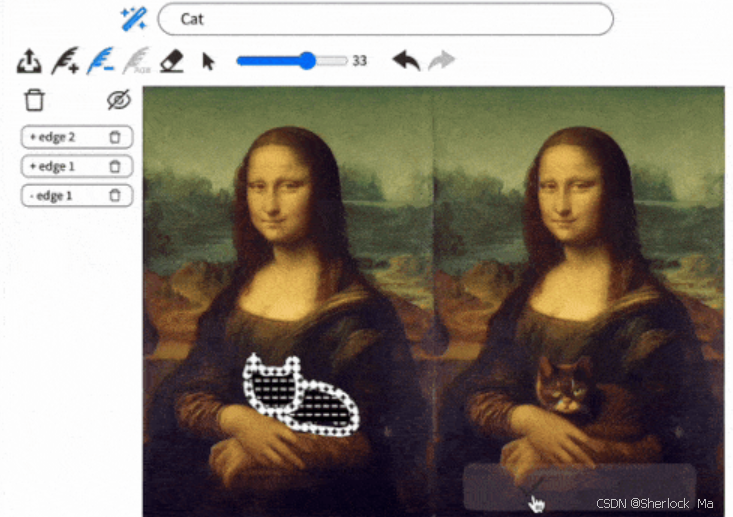
我的绘制效果图:
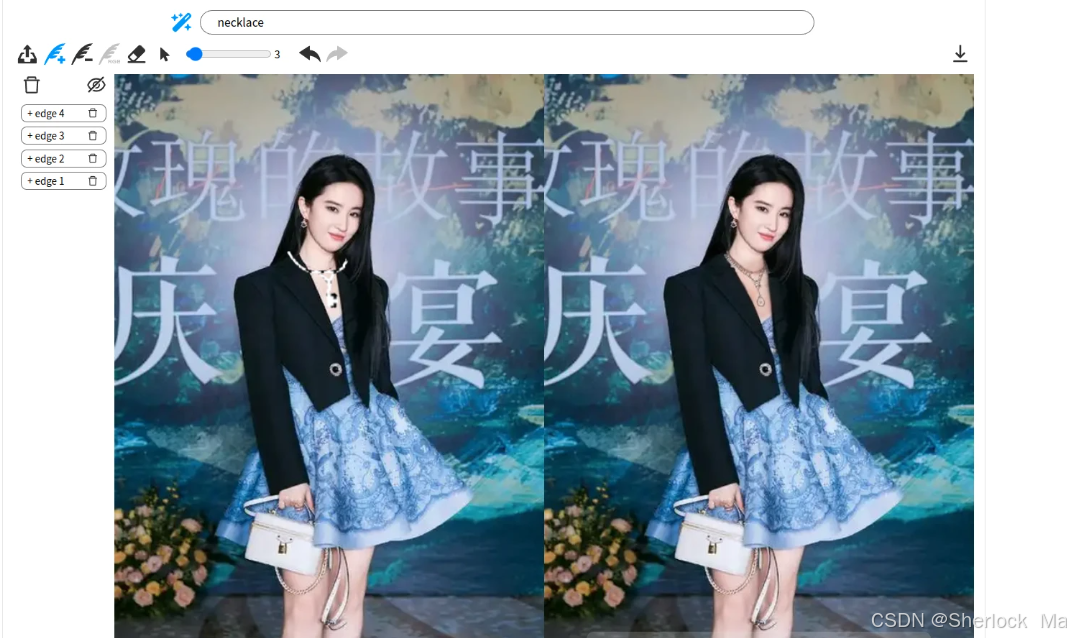
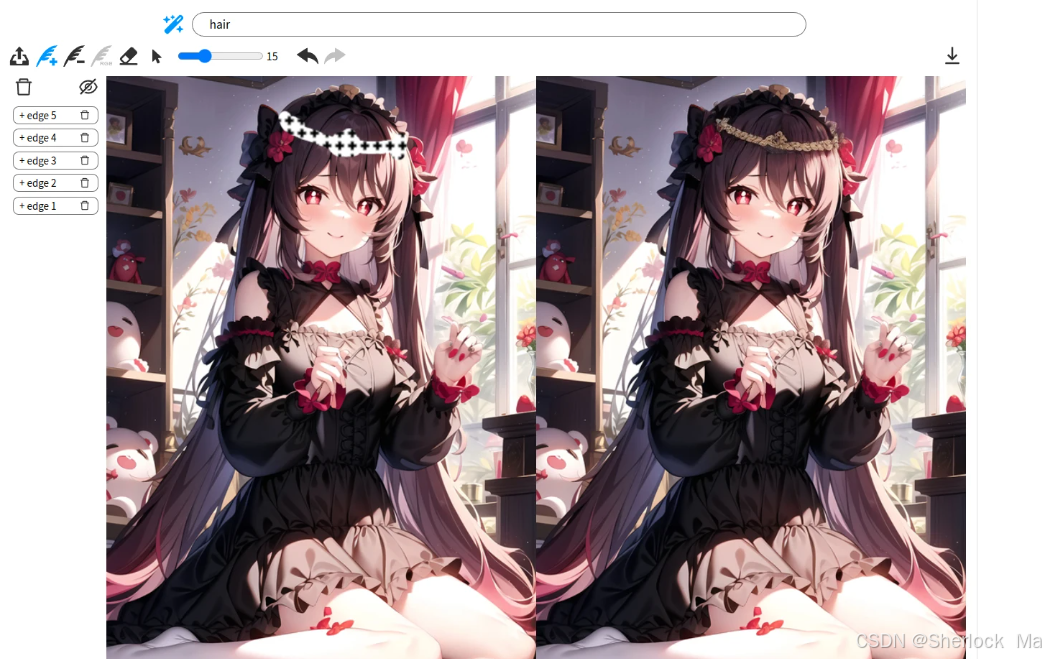
3.论文详解
要想对照片进行细致入微的精准编辑,无疑是一项颇具挑战性的任务。尽管扩散模型技术取得了迅猛进展,且在提升编辑控制力方面也有了新尝试,但要达成如此精细的编辑效果,依然面临着不小的难题。这主要是因为缺少了既直观又能够进行精细操控的界面和模型。
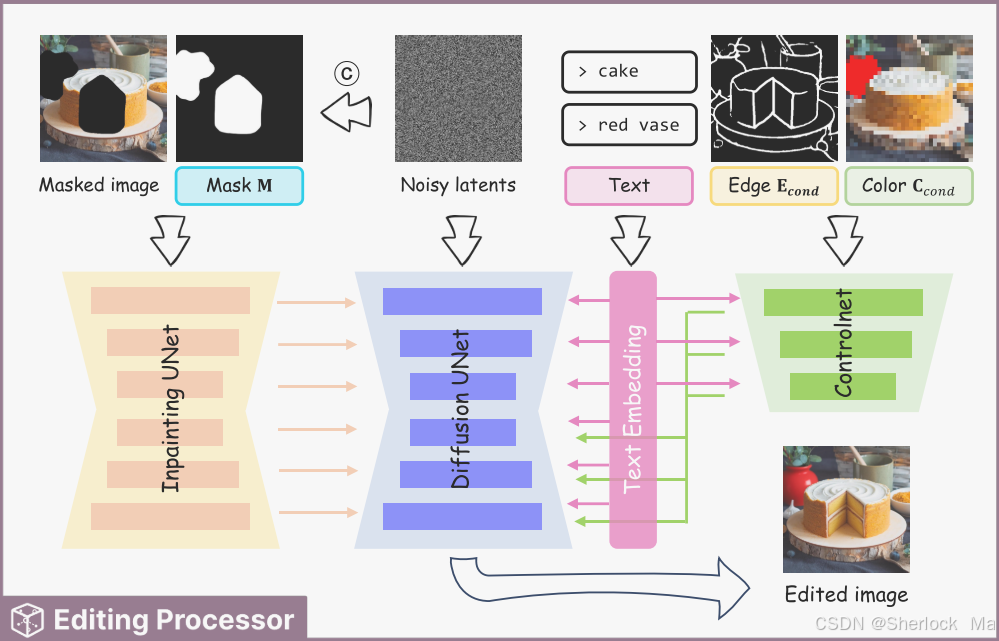
作者的目标是开发一个强大的、开源的、交互式的精确图像编辑系统,使图像编辑变得简单高效。作者的系统无缝集成了三个核心模块:编辑处理器(Editing Processor,代码中使用了diffusion+controlnet+brushnet), 绘画助手(Painting Assistor,代码中使用LLaVA), 创意收集器(Idea Collector,也就是可视化界面)。编辑处理器确保高质量、可控的编辑生成,准确反映用户在颜色和边缘调整方面的编辑意图。绘画助手增强了系统预测和解释用户编辑意图的能力。Idea Collector作为一个直观的界面,允许用户快速轻松地输入他们的想法,大大提高了编辑效率。
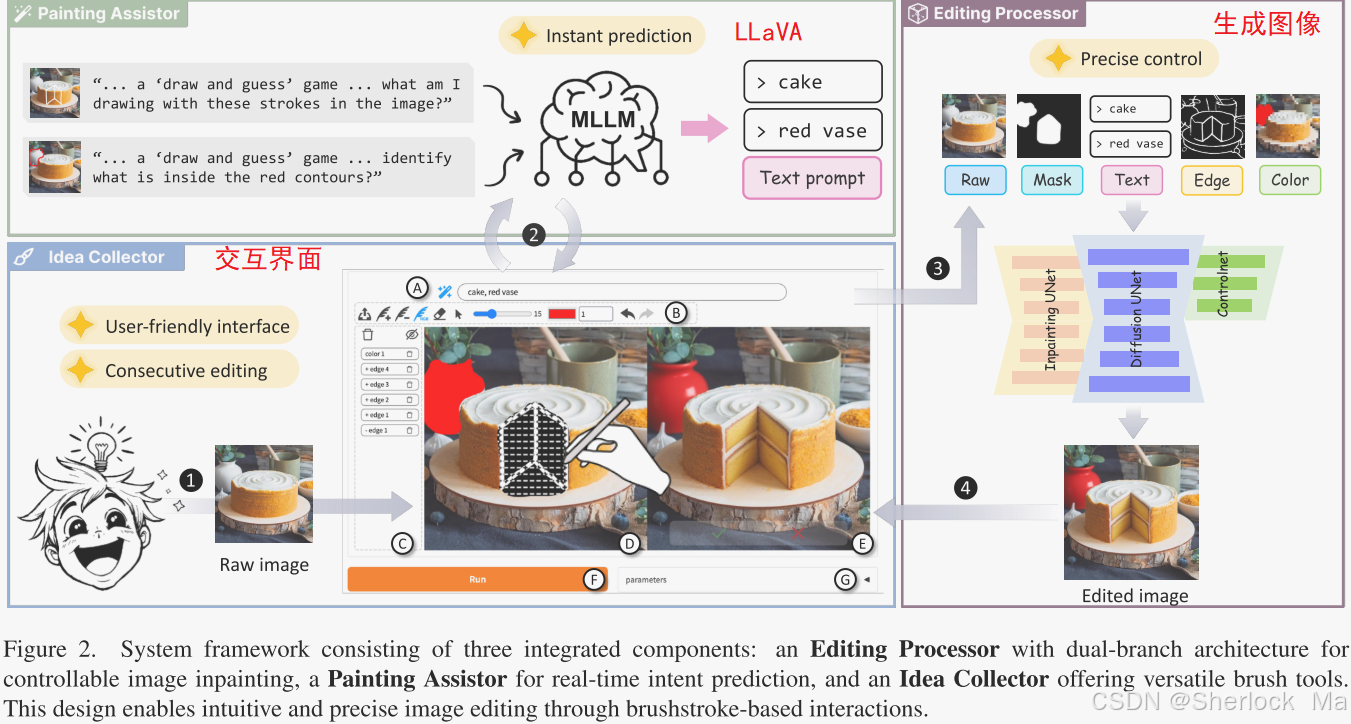
Painting Assistor
提示词工程
具体来说,作者使用LLaVA模型预测画笔区域的内容,方式是微调LLaVA,输入一个猜测的提示词,让模型猜测画笔区域可能的内容,模型只输出类别,然后交由Editing Processor进行编辑。
对于添加画笔,作者使用如下结构的提示词:“这是一个'绘制和猜测'游戏。我会上传一个包含一些笔画的图像。为了帮助您定位笔画,我将为您提供笔画的规范化边界框坐标,其中它们的原始坐标除以填充的图像宽度和高度。边界框的左上角位于(x1,y1),右下角位于(x2,y2)。现在用一个词一个短语告诉我,我想用图像中的这些笔画画什么?“其输出直接用作预测提示。
对于减画笔,作者绕过了问答过程,因为结果表明,无提示生成可获得令人满意的结果。
对于彩色画笔,问答设置类似:“用户将上传一张包含一些红色轮廓的图像。为了帮助您定位轮廓,...您需要使用单个单词或短语来识别轮廓内的内容。",(the重复部分被省略)。系统从彩色画笔描边边界中提取轮廓信息。通过将笔画的颜色信息与模型输出相结合来生成最终的预测提示。
数据集构建
作者使用Densely Captioned Images (DCI),DCI数据集中的每个图像都有详细的多粒度掩码,并附有开放式词汇标签和丰富的描述。这种丰富的注释结构使得模型能够捕获不同的视觉特征和语义上下文。
步骤1:为问答生成答案。初始阶段包括使用PiDiNet从DCI数据集中的图像生成边缘图。作者计算掩蔽区域内的边缘密度,并选择具有最高边缘密度的前5个掩模,与这些所选面具相对应的标签将作为问答的基本事实。为了确保模型专注于猜测用户意图,而不是解析不相关的细节,作者清理了标签,只保留名词组件,简化以强调基本元素。
第2步:使用边缘覆盖模拟画笔笔划。在数据集构建的第二部分中,作者重点关注第一步中确定的五个掩码。每个掩模经历随机形状扩展以引入可变性。作者使用基于SDXL的BrushNet模型对这些具有空提示的增强掩码执行修复。随后,将先前生成的边缘图叠加到修复区域上。这些覆盖图像模拟了用户手绘笔划可能如何改变图像的实际示例。
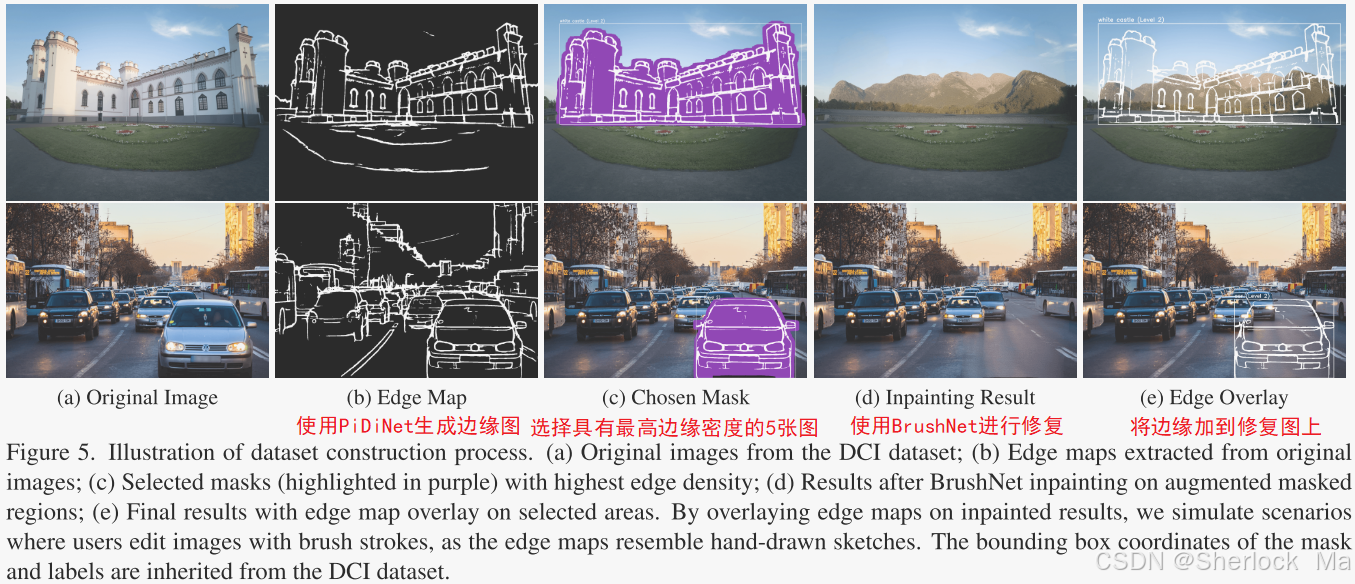
数据集其中包含总共24315张图像,分类在4412个不同的标签下。作者利用低秩自适应(LoRA)技术微调了LLaVA模型,使得LLaVA能够识别掩码区域的内容,并返回精简的结果。
Editing Processor
过程如下:
- 用户绘制:用户绘制结果通过转换,最终创建出用于指导编辑过程的边缘条件(Econd)和颜色条件(Ccond)以及掩码条件(MCond)。
- LLaVA预测:绘制结果通过LLaVA预测,输入到Text Embedding,然后将向量嵌入Diffusion和ControlNet.
-
双分支架构:Editing Processor采用了一个双分支架构,包括一个用于内容感知像素级指导的修复分支(Inpainting Branch)和一个提供结构指导的控制分支(Control Branch)。具体来说,边缘条件(Econd)和颜色条件(Ccond)通过ControlNet嵌入Diffusion中,而掩码条件(MCond)通过Inpainting Unet(BrushNet)嵌入diffusion。
4.代码解析
环境安装
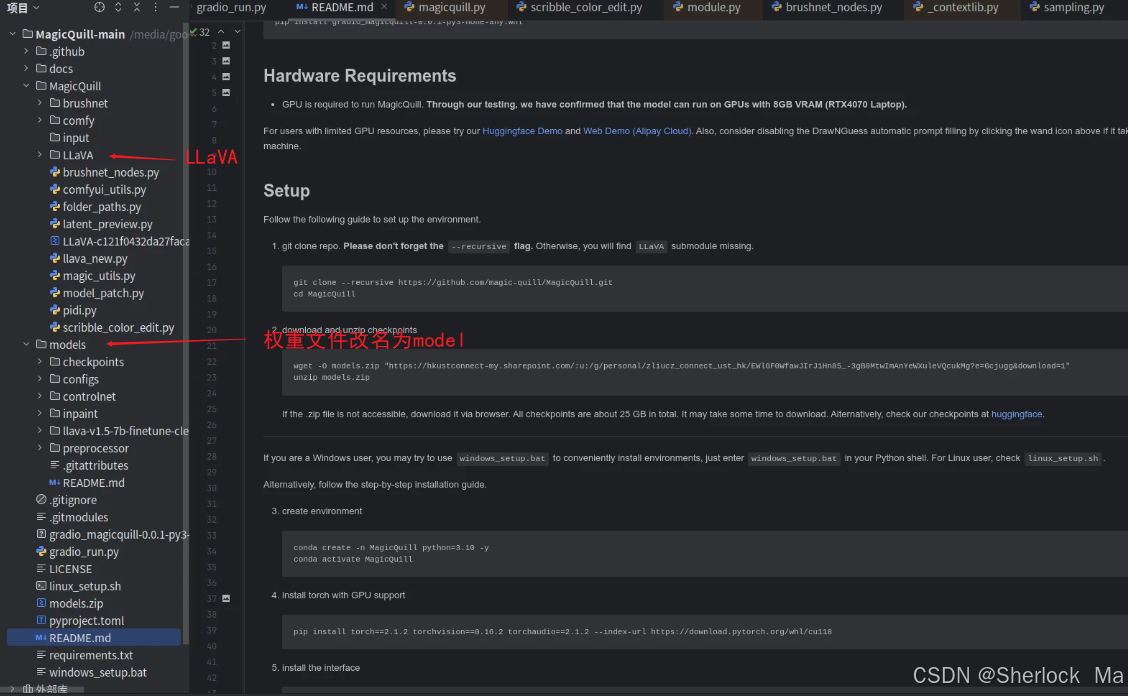
首先下载github代码,如果使用git,一定要加--recursive
git clone --recursive https://github.com/magic-quill/MagicQuill.git然后下载权重,建议直接使用huggingface,使用wget经常中途断掉:https://huggingface.co/LiuZichen/MagicQuill-models/tree/main
然后将权重文件夹改名为model,位置和MagicQuill平级
接着创建一个虚拟环境,建议Python3.10,安装pytorch
pip install torch==2.1.2 torchvision==0.16.2 torchaudio==2.1.2 --index-url https://download.pytorch.org/whl/cu118安装官方提供的包:
pip install gradio_magicquill-0.0.1-py3-none-any.whl安装LLaVA环境(注意Linux和Windows的区别)
(For Linux)
cp -f pyproject.toml MagicQuill/LLaVA/
pip install -e MagicQuill/LLaVA/
(For Windows)
copy /Y pyproject.toml MagicQuill\LLaVA\
pip install -e MagicQuill\LLaVA\
如果使用Windows Powershell,第一行改成:
Copy-Item -Path pyproject.toml -Destination "MagicQuill\LLaVA" -Force安装其他包:
pip install -r requirements.txt接着运行:
python gradio_run.py如何使用
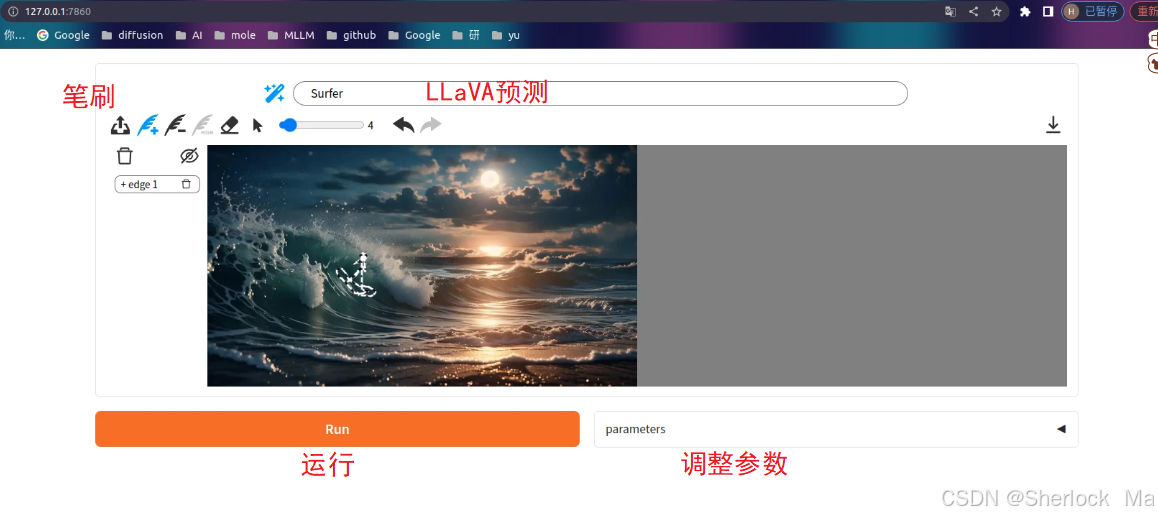
使用步骤:
- 上传图片
- 使用笔刷进行编辑。需要注意的是:颜色笔刷和添加/减笔试不能同时使用,如果需要同时用,应先保留预览图的效果
- 添加笔刷:使用添加笔刷,根据提示添加细节和元素--用自己生动的笔触表达自己的想法!
- 减笔刷:减法笔刷可以根据提示去除多余的细节或重绘区域。如果有不满意的地方,只需将其减去即可!
- 颜色笔刷:彩色画笔可以精确地为图像上色,与您画笔的颜色相匹配
- 更改LLaVA预测结果,调参+运行
- 满意就保留(预览框里面的绿色√),不满意重新画(预览框里面的红色的×)
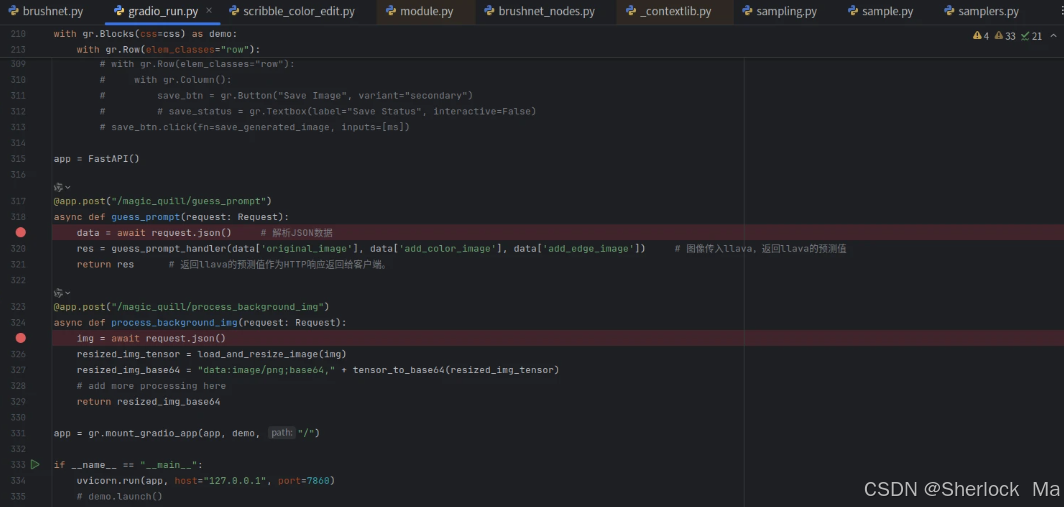
如何debug
在async def guess_prompt(request: Request)处打断点,可以对LLaVA预测进行debug(注意要先用画笔绘图)
在generate_image_handler()处打断点可以对生成部分进行debug(注意要点run才能debug)
llava预测
在gradio_run.py下面的guess_prompt()定义了一个异步的HTTP POST请求处理器,具体来说:
- 接收请求:通过 @app.post("/magic_quill/guess_prompt") 装饰器定义了一个POST请求的路由。
- 解析请求数据:使用 await request.json() 解析客户端发送的JSON数据。
- 处理数据:调用 guess_prompt_handler 函数,传入解析后的图像数据,其中是llava模型,用于预测人想要画的物体。
- 返回结果:将 guess_prompt_handler 的返回值作为HTTP响应返回给客户端,显示在最上面。
@app.post("/magic_quill/guess_prompt")
async def guess_prompt(request: Request):
data = await request.json() # 解析JSON数据
res = guess_prompt_handler(data['original_image'], data['add_color_image'], data['add_edge_image']) # 图像传入llava,返回llava的预测值
return res # 返回llava的预测值作为HTTP响应返回给客户端。其中,guess_prompt_handler()如下,其功能为加载和预处理原始图像、颜色图像和边缘图像,并通过guess()交由llava进行预测。
def guess_prompt_handler(original_image, add_color_image, add_edge_image):
original_image_tensor = load_and_preprocess_image(original_image) # 处理原图
if add_color_image:
add_color_image_tensor = load_and_preprocess_image(add_color_image) # 处理颜色笔刷
else:
add_color_image_tensor = original_image_tensor
width, height = original_image_tensor.shape[1], original_image_tensor.shape[2]
add_edge_mask = create_alpha_mask(add_edge_image) if add_edge_image else torch.zeros((1, height, width), dtype=torch.float32, device="cpu") # 处理边缘笔刷
res = guess(original_image_tensor, add_color_image_tensor, add_edge_mask) # llava预测
return res通过guess调用自定义的llavaModel进行处理
def guess(original_image_tensor, add_color_image_tensor, add_edge_mask):
description, ans1, ans2 = llavaModel.process(original_image_tensor, add_color_image_tensor, add_edge_mask)
ans_list = []
if ans1 and ans1 != "":
ans_list.append(ans1)
if ans2 and ans2 != "":
ans_list.append(ans2)
return ", ".join(ans_list)其中调用llavaModel.process分别对颜色和边缘图像进行处理
- 处理边缘图像:
- 检查 add_mask 中是否有绘制区域(即 torch.sum(add_mask).item() > 0)。
- 如果有绘制区域,计算该区域的边界框坐标,并生成描述问题。
-
通过add_mask给原图加上掩码(也就是笔触区域) 根据图像的亮度调整笔触效果:如果平均亮度大于 0.8,则将笔触区域设为黑色;否则设为白色。
- llava预测
- 处理带有颜色差异的图像:
- 检查 colored_image 和 image 是否不相等。
- 如果不相等,检测颜色差异,生成带有颜色轮廓的图像,并计算颜色差异区域的边界框坐标。
- 检查 colored_image 和 image 是否不相等。
class LLaVAModel:
...
def process(self, image, colored_image, add_mask):
description = ""
answer1 = ""
answer2 = ""
image_with_sketch = image.clone()
if torch.sum(add_mask).item() > 0: # 如果 add_mask 中有绘制区域,则计算该区域的边界框坐标。
x_min, y_min, x_max, y_max = get_bounding_box_from_mask(add_mask)
# print(x_min, y_min, x_max, y_max)
question = f"This is an 'I draw, you guess' game. I will upload an image containing some sketches. To help you locate the sketch, I will give you the normalized bounding box coordinates of the sketch where their original coordinates are divided by the image width and height. The top-left corner of the bounding box is at ({x_min}, {y_min}), and the bottom-right corner is at ({x_max}, {y_max}). Now tell me, what am I trying to draw with these sketches in the image?"
# image_with_sketch[add_mask > 0.5] = 1.0
bool_add_mask = add_mask > 0.5
mean_brightness = image_with_sketch[bool_add_mask].mean()
if mean_brightness > 0.8: # 这样做的目的是为了在图像中创建更清晰的笔触效果,通过将笔触区域的亮度设置为极端值(黑色或白色),可以使得笔触更加突出,从而在图像编辑中实现更精确的控制。
image_with_sketch[bool_add_mask] = 0.0
else:
image_with_sketch[bool_add_mask] = 1.0
answer1 = self.generate_description([image_with_sketch.squeeze() * 255], question)
print(answer1)
if not torch.equal(image, colored_image): # 如果 colored_image 和 image 不相等,则检测颜色差异。
color = find_different_colors(image.squeeze() * 255, colored_image.squeeze() * 255)
image_with_bbox, colored_mask = get_colored_contour(colored_image.squeeze() * 255, image.squeeze() * 255)
x_min, y_min, x_max, y_max = get_bounding_box_from_mask(colored_mask) # # 计算颜色差异区域的边界框坐标。
question = f"The user will upload an image containing some contours  最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 467
467

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









