







背景
我们需要周期性地统计近万台设备的实时状态,包括设备 ID、压力、温度、湿度,以及对应的时间戳:
DeviceID, Pressure, Temperature, Humidity, TimeStamp
这些与发生时间相关的一组数据,就是时间序列数据。这些数据的特点是没有严格的关系模型,记录的信息可以表示成键和值的关系(例如,一个设备 ID 对应一条记录),所以,并不需要专门用关系型数据库(例如 MySQL)来保存。而 Redis 的键值数据模型,正好可以满足这里的数据存取需求。Redis 基于自身数据结构以及扩展模块,提供了两种解决方案。
时间序列数据的读写特点
在实际应用中,时间序列数据通常是持续高并发写入的,例如,需要连续记录数万个设备的实时状态值。同时,时间序列数据的写入主要就是插入新数据,而不是更新一个已存在的数据,也就是说,一个时间序列数据被记录后通常就不会变了,因为它就代表了一个设备在某个时刻的状态值(例如,一个设备在某个时刻的温度测量值,一旦记录下来,这个值本身就不会再变了)。
所以,这种数据的写入特点很简单,就是插入数据快,这就要求我们选择的数据类型,在进行数据插入时,复杂度要低,尽量不要阻塞。看到这儿,你可能第一时间会想到用 Redis 的 String、Hash 类型来保存,因为它们的插入复杂度都是 O(1),是个不错的选择。但是,我们知道,String 类型在记录小数据时(例如刚才例子中的设备温度值),元数据的内存开销比较大,不太适合保存大量数据。
我们在查询时间序列数据时,既有对单条记录的查询(例如查询某个设备在某一个时刻的运行状态信息,对应的就是这个设备的一条记录),也有对某个时间范围内的数据的查询(例如每天早上 8 点到 10 点的所有设备的状态信息)。
除此之外,还有一些更复杂的查询,比如对某个时间范围内的数据做聚合计算。这里的聚合计算,就是对符合查询条件的所有数据做计算,包括计算均值、最大 / 最小值、求和等。例如,我们要计算某个时间段内的设备压力的最大值,来判断是否有故障发生。
弄清楚了时间序列数据的读写特点,接下来我们就看看如何在 Redis 中保存这些数据。我们来分析下:针对时间序列数据的“写要快”,Redis 的高性能写特性直接就可以满足了;而针对“查询模式多”,也就是要支持单点查询、范围查询和聚合计算,Redis 提供了保存时间序列数据的两种方案,分别可以基于 Hash 和 Sorted Set 实现,以及基于 RedisTimeSeries 模块实现。
基于 Hash 和 Sorted Set 保存时间序列数据
Hash 和 Sorted Set 组合的方式有一个明显的好处:它们是 Redis 内在的数据类型,代码成熟和性能稳定。所以,基于这两个数据类型保存时间序列数据,系统稳定性是可以预期的。
不过,在前面学习的场景中,我们都是使用一个数据类型来存取数据,那么,为什么保存时间序列数据,要同时使用这两种类型?这是我们要回答的第一个问题。
关于 Hash 类型,我们都知道,它有一个特点是,可以实现对单键的快速查询。这就满足了时间序列数据的单键查询需求。我们可以把时间戳作为 Hash 集合的 key,把记录的设备状态值作为 Hash 集合的 value。
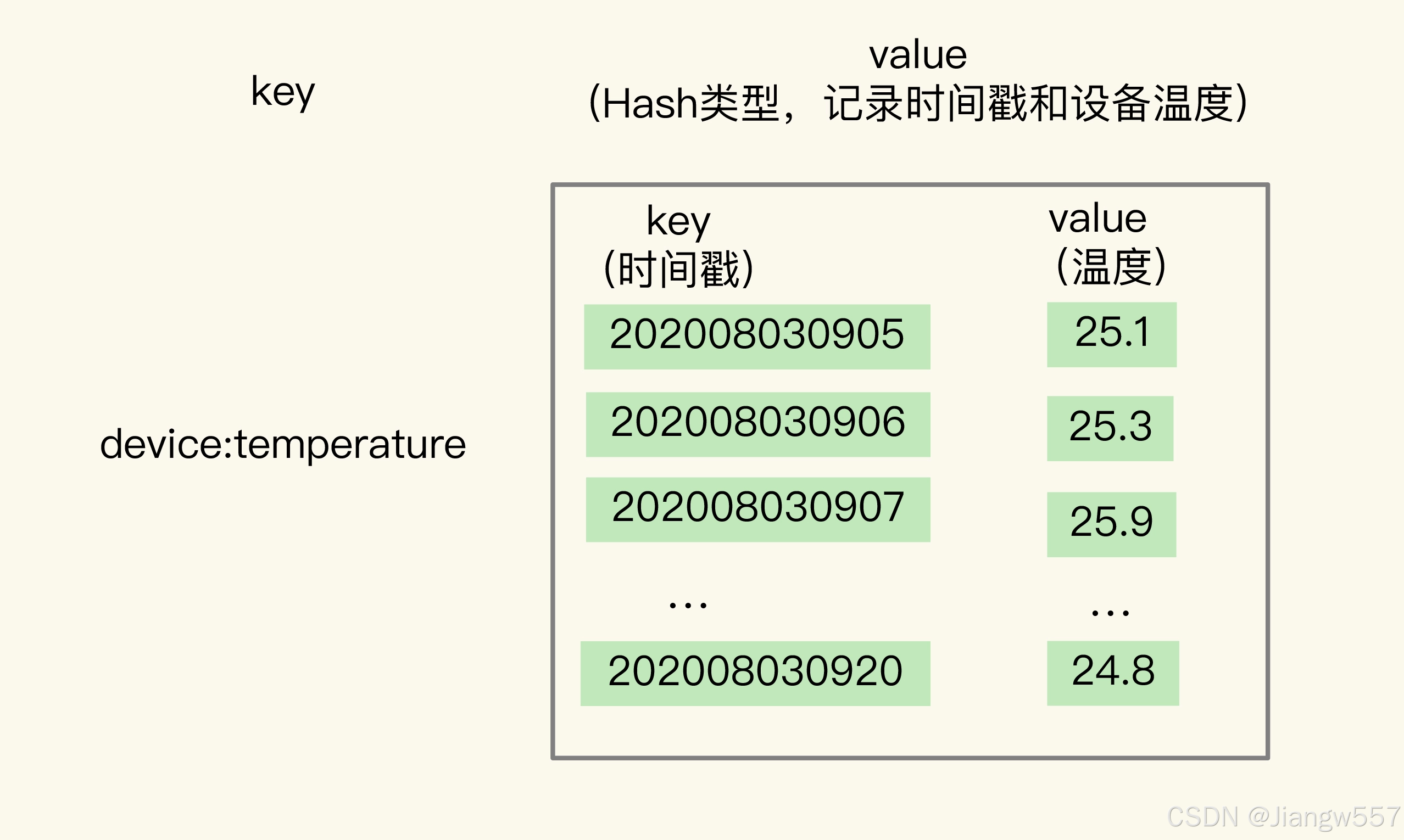
当我们想要查询某个时间点或者是多个时间点上的温度数据时,直接使用 HGET 命令或者 HMGET 命令,就可以分别获得 Hash 集合中的一个 key 和多个 key 的 value 值了。
用 Hash 类型来实现单键的查询很简单。<
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











