







 本文探讨深度学习网络从浅层到千层的过程中遇到的挑战,如梯度消失问题,以及解决方案,如ReLU和Batch Normalization。重点在于残差结构(Residual Networks),其通过直通路径解决了深度网络的退化问题,成功训练出152层的高效网络。进一步,文章还介绍了1001层的Identity Mapping结构,确保深层网络的信息传递。
本文探讨深度学习网络从浅层到千层的过程中遇到的挑战,如梯度消失问题,以及解决方案,如ReLU和Batch Normalization。重点在于残差结构(Residual Networks),其通过直通路径解决了深度网络的退化问题,成功训练出152层的高效网络。进一步,文章还介绍了1001层的Identity Mapping结构,确保深层网络的信息传递。
本文介绍网络从几层加深到一千层的各种关键技术,尤其聚焦残差结构(Residual)在其中发挥的作用。
问题
网络的层数越深,可覆盖的解空间越广,理论上应该有越高精度。
但简单地累加层数,并不能直接带来更好的收敛性和精度。
网络的宽度也是决定性能的关键因素,“深vs宽”未有定论,不在本文讨论之列。
几层到几十层
问题:梯度消失
对于较深的网络时,在反向传播时,很容易由于响应过大/过小,进入梯度为0的区域。导致浅层无法训练。
解决
ReLU
2012年5层的AlexNet1使用了ReLU结构,斩获当年ILSVRC图像分类竞赛第一名。
ReLU响应函数(蓝色)的值域是 [ 0 , ∞ ] [0,\infty] [0,∞],只要响应为正,梯度不会消失。
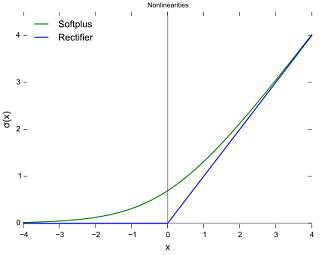
ReLU的另一个优点是:计算很快。
Batch Normalization
2015年初的Batch Normalization2虽然没有打榜ImageNet,不过在2015年ILSVRC的参赛算法中已经是标准配置。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









