 理解Recurrent视觉注意力模型:源码解析
理解Recurrent视觉注意力模型:源码解析





 本文深入解析Mnih等人的Recurrent模型在视觉注意力中的应用,通过Torch实现MNIST手写数字分类任务。文章涵盖参数设置、网络构造(包括Glimpse、Recurrent、Locator和Attention网络)和训练设置,帮助读者理解增强学习中的hard attention机制,复习Torch和dp扩展包的语法。
本文深入解析Mnih等人的Recurrent模型在视觉注意力中的应用,通过Torch实现MNIST手写数字分类任务。文章涵盖参数设置、网络构造(包括Glimpse、Recurrent、Locator和Attention网络)和训练设置,帮助读者理解增强学习中的hard attention机制,复习Torch和dp扩展包的语法。
Mnih, Volodymyr, Nicolas Heess, and Alex Graves. “Recurrent models of visual attention.” Advances in Neural Information Processing Systems. 2014.
这篇文章处理的任务非常简单:MNIST手写数字分类。但使用了聚焦机制(Visual Attention),不是一次看一张大图进行估计,而是分多次观察小部分图像,根据每次查看结果移动观察位置,最后估计结果。
Yoshua Bengio的高徒,先后供职于LISA和Element Research的Nicolas Leonard用Torch实现了这篇文章的算法。Torch官方cheetsheet的demo中,就包含这篇源码,作者自己的讲解也刊登在Torch的博客中,足见其重要性。
通过这篇源码,我们可以
- 理解聚焦机制中较简单的hard attention
- 了解增强学习的基本流程
- 复习Torch和扩展包dp的相关语法
本文解读训练源码,分三大部分:参数设置,网络构造,训练设置。以下逐次介绍其中重要的语句。
参数设置
除了Torch之外,还需要包含Nicholas Leonard自己编写的两个包。dp:能够简化DL流程,训练过程更“面向对象”;rnn:实现Recurrent网络。
require 'dp'
require 'rnn'
首先使用Torch的CmdLine类设定一系列参数,存储在opt中。这是Torch的标准写法。
cmd = torch.CmdLine()
cmd:option('--learningRate', 0.01, 'learning rate at t=0') -- 参数名,参数值,说明
local opt = cmd:parse(arg or {
}) --把cmd中的参数传入opt
把数据载入到数据集ds中,数据是dp包中已经下载好的:
ds = dp[opt.dataset]()
网络构造
这篇源码中模型的写法遵循:由底到顶,先细节后整体。和CNN不同,Recurrent网络带有反馈,呈现较为复杂的多级嵌套结构。请着重关注每个模块的输入、输出和作用部分。
Glimpse网络
输入:图像 I I I和观察位置 l l l
输出:观察结果 x x x
蓝色输入,橙色输出,菱形表示串接:
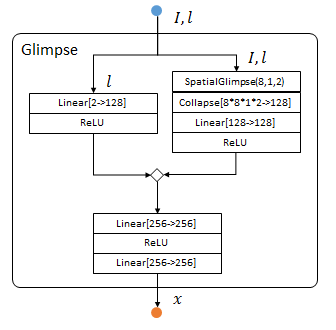
首先用locationSensor(左半)提取位置信息 l l l中的特征:
locationSensor:add(nn.SelectTable(2)) --选择两个输入中的第二个,位置l
locationSensor:add(nn.Linear(2, opt.locatorHiddenSize)) --Torch中的Linear指全连层
locationSensor:add(nn[opt.transfer]()) --opt.transfer定义一种非线性运算,本文中是ReLU
之后用glimpseSensor(右半)提取图像 I I I位置 l l l的特征。
其中SpacialGlimpse是dp中定义的层,提取尺寸为PatchSize的Depth层图像,相邻层比例为Scale。
glimpseSensor:add(nn.SpatialGlimpse(opt.glimpsePatchSize, opt.glimpseDepth, opt.glimpseScale):float()) --SpatialGlimpse提取小块金字塔
glimpseSensor:add(nn.Collapse(3)) --压缩第三维
glimpseSensor:add(nn.Linear(ds:imageSize('c')*(opt.glimpsePatchSize^2)*opt.glimpseDepth, opt.glimpseHiddenSize 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 629
629

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









