







 本文是关于Python ORM框架SQLAlchemy的全面指南,涵盖了从安装、连接引擎、声明映射到创建表、会话管理、数据操作、查询技巧、一对多和多对多关系等核心概念和实践操作。
本文是关于Python ORM框架SQLAlchemy的全面指南,涵盖了从安装、连接引擎、声明映射到创建表、会话管理、数据操作、查询技巧、一对多和多对多关系等核心概念和实践操作。
一、SQLAlchemy简介
官方文档地址:
The Database Toolkit for Python
SQLAlchemy 是python中,通过ORM操作数据库的框架。简单点来说,就是帮助我们从烦冗的sql语句中解脱出来,从而不需要再去写原生的sql语句,只需要用python的语法来操作对象,就能被自动映射为sql语句。
它有几个不同的组件,可以单独使用或组合在一起。其主要组件依赖关系组织如下图所示:
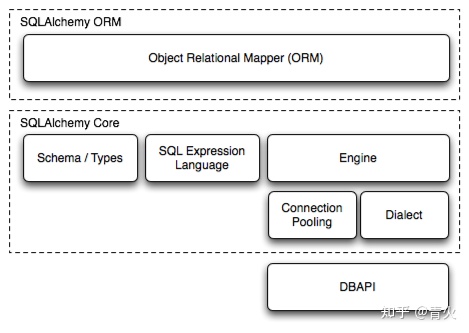
Schema / Types 类到表之间的映射规则SQL Expression Language SQL 语句Engine 引擎Connection Pooling 连接池Dialect 方言,调用不同的数据库 API(Oracle, postgresql, Mysql) 并执行对应的 SQL语句
二、安装
通过PIP安装
pip install SQLAlchemy使用setup.py安装
python setup.py install三、连接引擎
任何SQLAlchemy应用程序的开始都是一个Engine对象,此对象充当连接到特定数据库的中心源,提供被称为connection pool的对于这些数据库连接。
Engine对象通常是一个只为特定数据库服务器创建一次的全局对象,并使用一个URL字符串进行配置,该字符串将描述如何连接到数据库主机或后端。
>>> from sqlalchemy import create_engine
>>> engine = create_engine('sqlite:///:memory:', echo=True)create_engine的参数有很多,我列一些比较常用的:
- echo=False -- 如果为真,引擎将记录所有语句以及
repr()其参数列表的默认日志处理程序。 - enable_from_linting -- 默认为True。如果发现给定的SELECT语句与将导致笛卡尔积的元素取消链接,则将发出警告。
- encoding -- 默认为
utf-8 - future -- 使用2.0样式
- hide_parameters -- 布尔值,当设置为True时,SQL语句参数将不会显示在信息日志中,也不会格式化为 StatementError 对象。
- listeners -- 一个或多个列表
PoolListener将接收连接池事件的对象。 - logging_name -- 字符串标识符,默认为对象id的十六进制字符串。
- max_identifier_length -- 整数;重写方言确定的最大标识符长度。
- max_overflow=10 -- 允许在连接池中“溢出”的连接数,即可以在池大小设置(默认为5)之上或之外打开的连接数。
- pool_size=5 -- 在连接池中保持打开的连接数
- plugins -- 要加载的插件名称的字符串列表。
四、声明映射
也就是我们在Python中创建的一个类,对应着数据库中的一张表,类的每个属性,就是这个表的字段名。
这种的类对应于数据库中表的类,就称为映射类,我们要创建一个映射类,是基于基类定义的,每个映射类都要继承这个基类 declarative_base()。
>>> from sqlalchemy.orm import declarati 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









