




 本文解析LevelDB的写入流程,包括WriteBatch封装、Writer串行化、空间检查、合并写入、日志记录和Memtable更新,以及如何利用写队列和WAL机制提升性能。
本文解析LevelDB的写入流程,包括WriteBatch封装、Writer串行化、空间检查、合并写入、日志记录和Memtable更新,以及如何利用写队列和WAL机制提升性能。
文章目录
Write写入流程
LevelDB对外提供的写入接口有Put、Delete两种,这两种操作都会向Memtable和Log文件中追加一条新纪录。
同时LevelDB支持调用端使用多线程并发写入数据,并且会使用写队列+合并写 &WAL机制,将批量随机写转化成一次顺序写。
1)封装WriteBatch和Writer对象
DB::Put会把key、value对象封装到WriteBatch之中,之后DBImpl::方法会把WriteBatch对象封装到Writer对象中。
/**
* @brief 存放key、value
*
* @param opt 写选项信息
* @param key key
* @param value value
* @return Status 执行状态信息
*/
Status DB::Put(const WriteOptions& opt, const Slice& key, const Slice& value) {
//创建批处理写 WriteBatch
WriteBatch batch;
batch.Put(key, value);
return Write(opt, &batch);
}
Status DBImpl::Write(const WriteOptions& options, WriteBatch* updates) {
Writer w(&mutex_);
w.batch = updates;
w.sync = options.sync;
w.done = false;
...
}
WriteBatch本质上其实就是一个String对象,假设我们写入的key="leveldb",value="cpp"。其就会往这个string对象中写入如下信息:

/**
* @brief 将key、value写入writebatch
*
* @param key key
* @param value value
*/
void WriteBatch::Put(const Slice& key, const Slice& value) {
//写入数+1
WriteBatchInternal::SetCount(this, WriteBatchInternal::Count(this) + 1);
//写入type信息
rep_.push_back(static_cast<char>(kTypeValue));
//key加入前缀信息key.size()
PutLengthPrefixedSlice(&rep_, key);
PutLengthPrefixedSlice(&rep_, value);
}
之后,这个WriteBatch会被封装成Writer对象,Writer对象还会封装mutex,条件变量等用来实现等待通知。
struct DBImpl::Writer {
explicit Writer(port::Mutex* mu)
: batch(nullptr), sync(false), done(false), cv(mu) {}
Status status;
WriteBatch* batch;
bool sync;
bool done;
port::CondVar cv;
};
2)Writer串行化入队
多个线程并行的写入操作,会通过争用锁来实现串行化,线程将Writer放入写队列之后,会进入等待状态,直到满足如下两个条件:
- 其他线程把Writer写入
- 征用到锁并且是写队列的首节点
Status DBImpl::Write(const WriteOptions& options, WriteBatch* updates) {
Writer w(&mutex_);
w.batch = updates;
w.sync = options.sync;
w.done = false;
MutexLock l(&mutex_); //征用锁
writers_.push_back(&w); //该writer入队
//如果当前的writer还没有做完工作,且不是队首就一直等待
while (!w.done && &w != writers_.front()) {
w.cv.Wait();
}
if (w.done) {
return w.status;
}
...
}
3)确认写入空间足够
处于写队列头部的线程会调用MakeRoomForWrite的方法,这个方法会检查Memtable是否有足够的空间写入,其会将内存占用过高的MemTable转换成Immutable,并构造一个新的Memtable进行写入,刚刚形成的Immutable则交由后台线程dump到level0层。
// REQUIRES: mutex_ is held
// REQUIRES: this thread is currently at the front of the writer queue
Status DBImpl::MakeRoomForWrite(bool force) {
...
// Attempt to switch to a new memtable and trigger compaction of old
assert(versions_->PrevLogNumber() == 0);
//创建新的日志文件
uint64_t new_log_number = versions_->NewFileNumber();
WritableFile* lfile = nullptr;
s = env_->NewWritableFile(LogFileName(dbname_, new_log_number), &lfile);
if (!s.ok()) {
// Avoid chewing through file number space in a tight loop.
versions_->ReuseFileNumber(new_log_number);
break;
}
delete log_;
delete logfile_;
logfile_ = lfile;
logfile_number_ = new_log_number;
log_ = new log::Writer(lfile);
imm_ = mem_;
has_imm_.store(true, std::memory_order_release);
//申请新的memtable
mem_ = new MemTable(internal_comparator_);
mem_->Ref();
force = false; // Do not force another compaction if have room
//触发合并操作
MaybeScheduleCompaction();
}
}
return s;
}
4)批量取任务,进行合并写
处于写队列头部的线程进行MakeRoomForWrite的空间检查之后,就会从writers队列中取出头部任务,同时会遍历队列中后面的Writer合并到自身进行批量写,从而提高写入效率。最终多个Writer任务会被写入Log文件,然后被写入内存的MemTable。
Status DBImpl::Write(const WriteOptions& options, WriteBatch* updates) {
...
if (status.ok() && updates != nullptr) { // nullptr batch is for compactions
//从队列中批量取出任务
WriteBatch* write_batch = BuildBatchGroup(&last_writer);
WriteBatchInternal::SetSequence(write_batch, last_sequence + 1);
last_sequence += WriteBatchInternal::Count(write_batch);
// Add to log and apply to memtable. We can release the lock
// during this phase since &w is currently responsible for logging
// and protects against concurrent loggers and concurrent writes
// into mem_.
{
mutex_.Unlock();
//任务写入Log文件
status = log_->AddRecord(WriteBatchInternal::Contents(write_batch));
bool sync_error = false;
if (status.ok() && options.sync) {
status = logfile_->Sync();
if (!status.ok()) {
sync_error = true;
}
}
if (status.ok()) {
//任务写入MemTable
status = WriteBatchInternal::InsertInto(write_batch, mem_);
}
mutex_.Lock();
if (sync_error) {
// The state of the log file is indeterminate: the log record we
// just added may or may not show up when the DB is re-opened.
// So we force the DB into a mode where all future writes fail.
RecordBackgroundError(status);
}
}
if (write_batch == tmp_batch_) tmp_batch_->Clear();
versions_->SetLastSequence(last_sequence);
}
...
}
批量取任务
这一步会把writers队列中的任务挨个取出来,将其中的数据都添加至第一个Writer的WriteBatch之中。
/**
* @brief 将writers的front后面的所有数据取出来,添加至front的数据里面
*
* @param[out] last_writer 游标,会指向这个队列的上一个被取出数据的last_writer
* @return WriteBatch* 合并数据之后的WriterBatch
*/
WriteBatch* DBImpl::BuildBatchGroup(Writer** last_writer) {
...
Writer* first = writers_.front();
WriteBatch* result = first->batch;
...
*last_writer = first;
std::deque<Writer*>::iterator iter = writers_.begin();
++iter; // Advance past "first"
for (; iter != writers_.end(); ++iter) {
Writer* w = *iter;
...
WriteBatchInternal::Append(result, w->batch);
}
*last_writer = w;
}
return result;
}
写入日志
写入日志的过程中首先会进行一个块检查,如果当前块的容量不够,他就会开启一个新块写入这个数据。
//块容量检查,每个块的前七位都是 0x00
const int leftover = kBlockSize - block_offset_;
assert(leftover >= 0);
if (leftover < kHeaderSize) {
// Switch to a new block
if (leftover > 0) {
// Fill the trailer (literal below relies on kHeaderSize being 7)
static_assert(kHeaderSize == 7, "");
dest_->Append(Slice("\x00\x00\x00\x00\x00\x00", leftover));
}
block_offset_ = 0; //重置当前块偏移
当块检查完毕的时候,就会调用EmitPhysicalRecord函数写日志了:
const size_t avail = kBlockSize - block_offset_ - kHeaderSize; //计算剩余容量
const size_t fragment_length = (left < avail) ? left : avail; //计算要添加的字节数
//写入日志
s = EmitPhysicalRecord(type, ptr, fragment_length);
ptr += fragment_length;
left -= fragment_length;
begin = false;
这个函数会添加CRC等校验信息,之后把数据Append到可写文件之中:
Status Writer::EmitPhysicalRecord(RecordType t, const char* ptr,
size_t length) {
...
// Format the header
char buf[kHeaderSize];
buf[4] = static_cast<char>(length & 0xff);
buf[5] = static_cast<char>(length >> 8);
buf[6] = static_cast<char>(t);
// Compute the crc of the record type and the payload.
uint32_t crc = crc32c::Extend(type_crc_[t], ptr, length);
crc = crc32c::Mask(crc); // Adjust for storage
EncodeFixed32(buf, crc);
// Write the header and the payload
Status s = dest_->Append(Slice(buf, kHeaderSize));
if (s.ok()) {
s = dest_->Append(Slice(ptr, length));
if (s.ok()) {
s = dest_->Flush();
}
}
block_offset_ += kHeaderSize + length;
return s;
}
数据写入Memtable
数据写入则是会构建一个MemTableInserter,这个类会将每个key都调用memtable.Add方法添加至memtable表中。
Status WriteBatchInternal::InsertInto(const WriteBatch* b, MemTable* memtable) {
MemTableInserter inserter;
inserter.sequence_ = WriteBatchInternal::Sequence(b);
inserter.mem_ = memtable;
//这个迭代器会调用inserter的Put方法,把每个key都调用memtable.Add方法添加至表中
return b->Iterate(&inserter);
}
5)唤醒正在等待的线程
线程写入完成后,会对写完的Writer出队,并唤醒正在等待的线程,同时也会唤醒写队列中新的头部Writer对应的线程。
Status DBImpl::Write(const WriteOptions& options, WriteBatch* updates) {
// last_writer在BuildBatchGroup被改变了,会指向队列中最后一个被写入的writer
while (true) {
//弹出队头元素
Writer* ready = writers_.front();
writers_.pop_front();
if (ready != &w) {
ready->status = status;
ready->done = true;`在这里插入代码片`
ready->cv.Signal();
}
if (ready == last_writer) break;
}
// 唤醒队列未写入的第一个Writer
if (!writers_.empty()) {
writers_.front()->cv.Signal();
}
}
总结
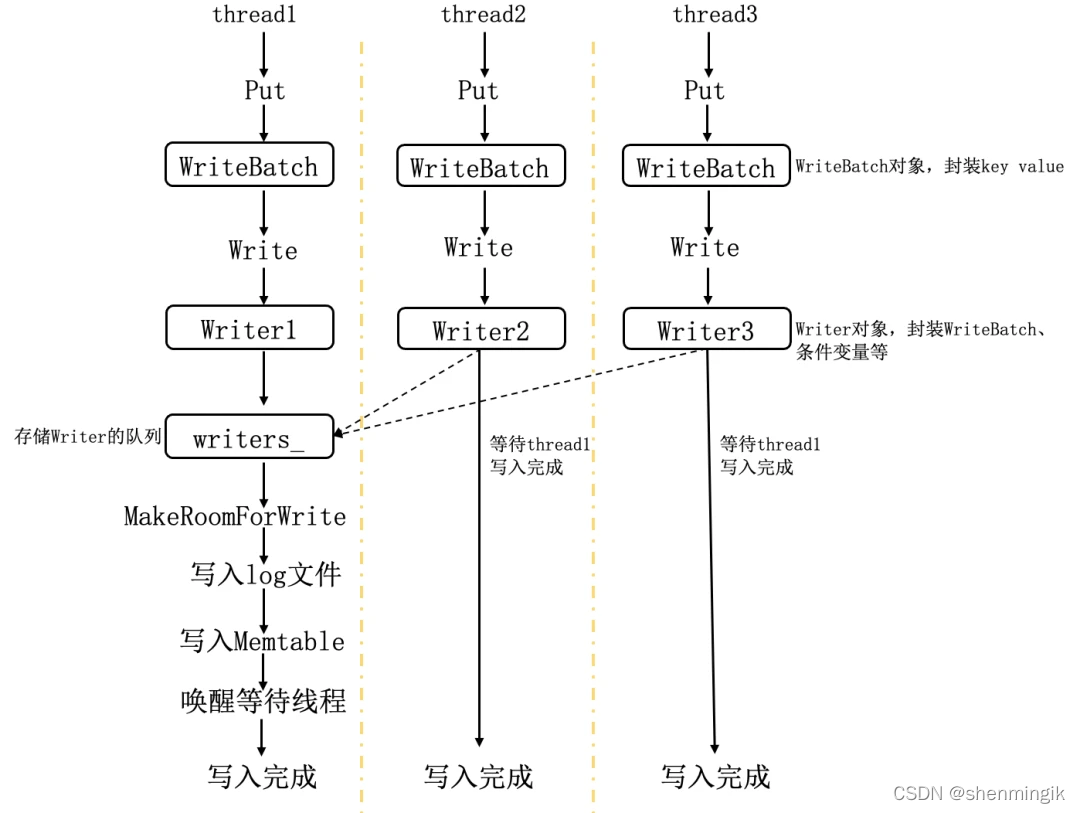
最后对写入步骤进行简单总结,如下图所示,三个写线程同时调用 LevelDB 的 Put 接口并发写入,三个线程首先会通过抢锁将构造的 Writer 对象串行的放入 writers写队列,这时 Writer1 处于写队列头部,thread1 会执行批量写操作,不仅会把自己构造的 Writer 写入,还会从队列中取出 thread2、thread3 对应的 Writer,最后将三者一起写入 Log 文件及内存 Memtable,thread2、thread3 在 push 完之后则会进入等待状态。thread1 写入完成之后,会唤醒处于等待状态的 thread2 和 thread3。
参考文献
[1] LevelDB 原理解析:数据的读写与合并是怎样发生的?(在原文基础上增添内容)

















 911
911

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









