






 博客探讨了PyTorch中MultiScaleRoIAlign操作的使用和输出形状的困惑。作者通过代码示例展示了该方法如何处理不同大小的特征图和RoIs,并解释了为何输出形状不是预期的[12, 5, 3, 4],而是[6, 5, 3, 3]。文章提到了关键点在于RoIs在不同特征图上的应用方式,以及在计算时如何聚合信息。作者通过参考多个资源最终理解了这个问题。
博客探讨了PyTorch中MultiScaleRoIAlign操作的使用和输出形状的困惑。作者通过代码示例展示了该方法如何处理不同大小的特征图和RoIs,并解释了为何输出形状不是预期的[12, 5, 3, 4],而是[6, 5, 3, 3]。文章提到了关键点在于RoIs在不同特征图上的应用方式,以及在计算时如何聚合信息。作者通过参考多个资源最终理解了这个问题。
这几天在看一个代码,看到这个方法,官方给的代码样例:
>>> m = torchvision.ops.MultiScaleRoIAlign(['feat1', 'feat3'], 3, 2)
>>> i = OrderedDict()
>>> i['feat1'] = torch.rand(1, 5, 64, 64)
>>> i['feat2'] = torch.rand(1, 5, 32, 32) # this feature won't be used in the pooling
>>> i['feat3'] = torch.rand(1, 5, 16, 16)
>>> # create some random bounding boxes
>>> boxes = torch.rand(6, 4) * 256; boxes[:, 2:] += boxes[:, :2]
>>> # original image size, before computing the feature maps
>>> image_sizes = [(512, 512)]
>>> output = m(i, [boxes], image_sizes)
>>> print(output.shape)
>>> torch.Size([6, 5, 3, 3])当时很奇怪,输入除了 feat2 不要用,feat1,feat3都要用,但是我当时很奇怪的是:明明两个featuremap,按理输出的shape应该是 shape= [12,5,3,4],为啥是[6, 5, 3, 3]?
我当时的想法是,有两个feature map,那6个box应该分别在每个feature map上进行找box对应区域,这个想法是错的,下图见解:
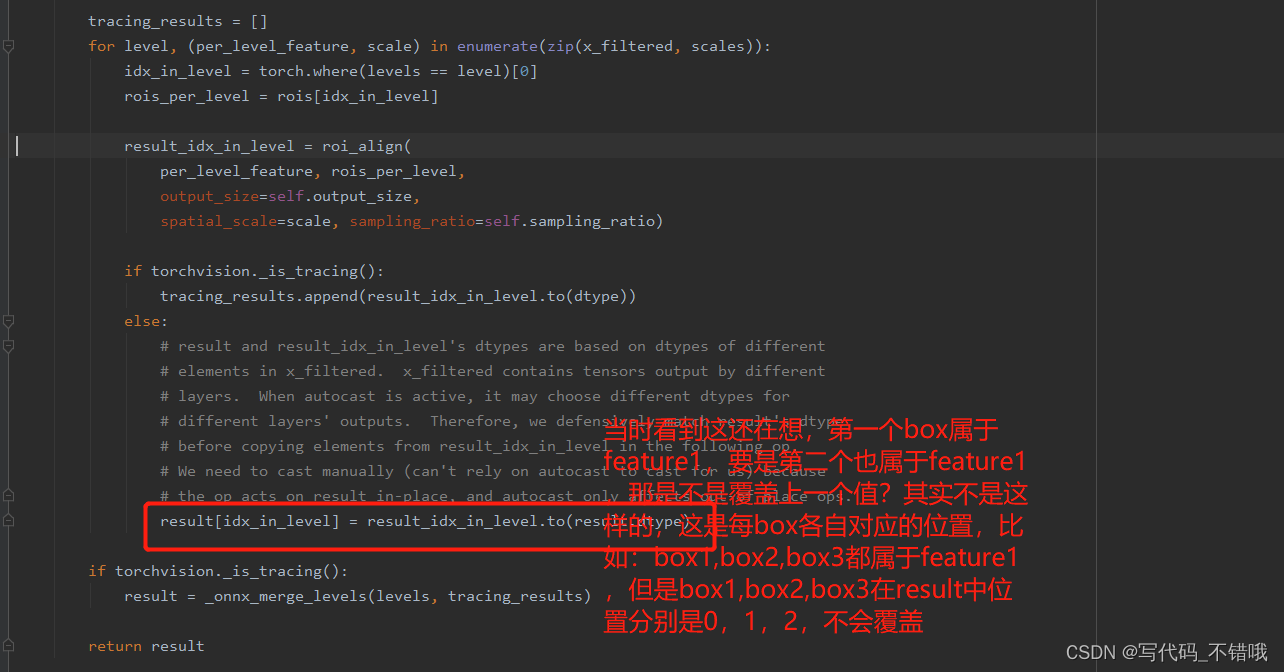
而且在RPN给出的rois时,给几个box,就会在上面初始化 MultiScaleRoIAlign 方法时确定(rois给几个,这个是确定好的),接着result中就会有几个key,不会出现覆盖。
虽然简单记录了,也不知道别人能不能看懂,但是困扰我有好久了,昨天晚上到今天终于搞懂了。
为数不多找到的参考:
从源码学习 Faster-RCNN - 刘知安的博客 | LiuZhian's Blog

















 799
799

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









