Hive SQL执行流程分析
最新推荐文章于 2025-11-01 16:25:04 发布





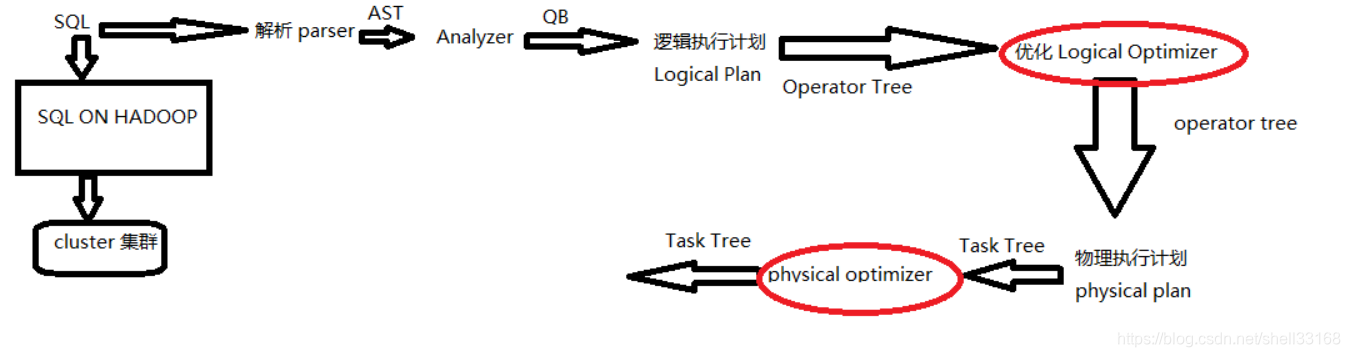
 本文深入探讨了HiveSQL执行慢的原因,解析了其执行步骤,包括PredicatePushDown和MapJoin的发生阶段,详细讲解了groupby的过程,并通过mapreducecount过程说明了split、shuffle、reduce和combiner的工作原理。
本文深入探讨了HiveSQL执行慢的原因,解析了其执行步骤,包括PredicatePushDown和MapJoin的发生阶段,详细讲解了groupby的过程,并通过mapreducecount过程说明了split、shuffle、reduce和combiner的工作原理。
本文深入探讨了HiveSQL执行慢的原因,解析了其执行步骤,包括PredicatePushDown和MapJoin的发生阶段,详细讲解了groupby的过程,并通过mapreducecount过程说明了split、shuffle、reduce和combiner的工作原理。
本文深入探讨了HiveSQL执行慢的原因,解析了其执行步骤,包括PredicatePushDown和MapJoin的发生阶段,详细讲解了groupby的过程,并通过mapreducecount过程说明了split、shuffle、reduce和combiner的工作原理。
 1132
1664
1132
1664

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言