




 本文介绍Hive中正确增加分区字段的方法,解决旧分区字段无法更新的问题,并演示如何创建和修改自带JSON格式解析的Hive表,包括序列化方式的变更及字段添加。
本文介绍Hive中正确增加分区字段的方法,解决旧分区字段无法更新的问题,并演示如何创建和修改自带JSON格式解析的Hive表,包括序列化方式的变更及字段添加。
一、问题描述:
实际应用中,常常存在修改数据表结构的需求,比如:增加一个新字段。
如果使用一般的add columns(col1 string)的语句增加字段的话,对于旧分区中的col1将为空且无法更新,即便insert overwrite该分区也不会生效。
1、准备一个分区表test_partition
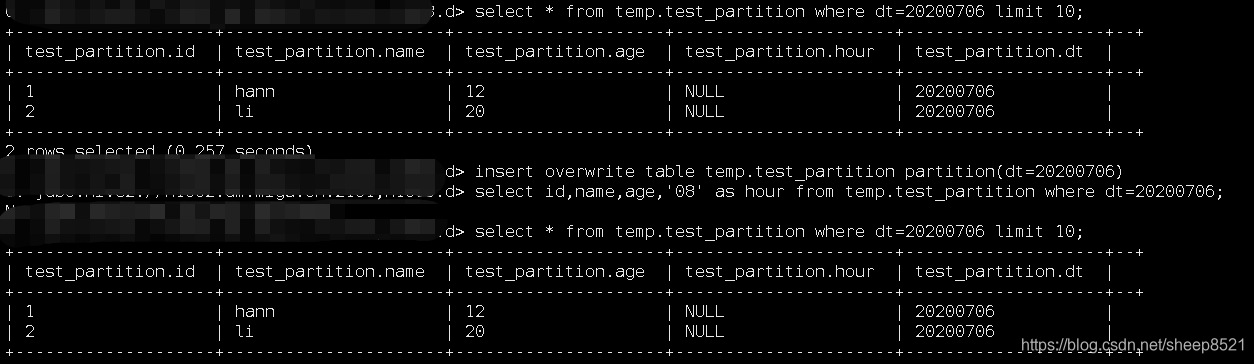
2、测试数据新增字段
alter table temp.test_partition add columns (hour string);

3、插入数据

插入失败,所以原来的插入方式对以前分分区是不生效的,这个在生产中刷数据是没有意义的。
4、Hive的联级(cascade)正确的增加分区方式。
alter table temp.test_partition add columns(
hour string
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 3978
3978




 到【灌水乐园】发言
到【灌水乐园】发言







