







 超级会员免费看
超级会员免费看
 这篇博客介绍了如何使用Python语言找出字典中键值最大的键值对,通过示例代码展示了具体实现过程。
这篇博客介绍了如何使用Python语言找出字典中键值最大的键值对,通过示例代码展示了具体实现过程。
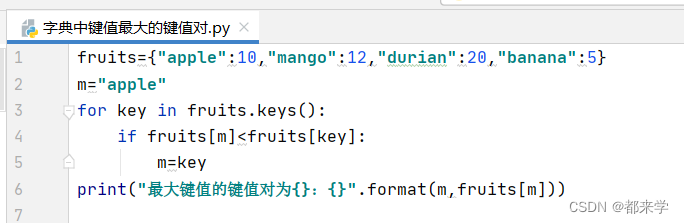
fruits={"apple":10,"mango":12,"durian":20,"banana":5}
m="apple"
for key in fruits.keys():
if fruits[m]<fruits[key]:
m=key
print("最大键值的键值对为{}:{}".format(m,fruits[m]))
运行结果如下:

根据所需要分析的键值对,依次填入到fruits中
fruits={"apple":10,"mango":12,"durian":20,"banana":5}
m="apple"
for key in fruits.keys():
if fruits[m]<fruits[key]:
m=key
print("最大键值的键值对为{}:{}".format(m,fruits[m]))
运行结果如下:
根据所需要分析的键值对,依次填入到fruits中
 5457
2402
9587
392
5457
2402
9587
392

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言





























