



爬虫
目录
网络爬虫(又被称为网页蜘蛛,网络机器人)就是模拟浏览器发送网络请求,接收请求响应,一种按照一定的规则,自动地抓取互联网信息的程序。
原则上,只要是浏览器(客户端)能做的事情,爬虫都能够做。
需要一个运行Python的环境,我用的是pychram
爬虫神器requests模块使用
resp = requests.get(网址)
resp = requests.post(网址)
resp.text 拿到页面源代码, 数据
resp.json() 能直接拿到json数据
爬取肯德基餐厅信息:
import requests
url = "http://www.kfc.com.cn/kfccda/ashx/GetStoreList.ashx?op=keyword"
data = {
"cname": "",
"pid": "",
"keyword": "徐家汇",
"pageIndex": "1",
"pageSize": "10",
}
resp = requests.post(url,data = data)
print(resp.json())
正则表达式:
1.正则支持普通字符
2.元字符,就一个符号来匹配一堆内容
\d能够匹配一个数字(0-9)
\w能够匹配数字,字母,下划线(0-9,a-z,A-Z)
\W除了数字,字母,下划线以外的内容
[abc]匹配abc
[^abc]除了abc
.除了换行符以外的其他所有内容都可以被匹配
3.量词
控制前面元字符出现的频次
+,前面的元字符出现1次或者多次
*,前面的元字符出现0次或者多次,尽可能多的拿到数据
?,前面的元字符出现0次或者1次
4.惰性匹配
爬虫学习,晚上一起学习,干嘛呢,学习呢
爬虫.*学习
爬虫学习
爬虫学习,晚上一起学习
爬虫学习,晚上一起学习,干嘛呢,学习
爬虫.*?学习
爬虫学习
.*?惰性匹配 匹配到距离xxx最近的内容
python内置模块re
re.findall() 拿到的是列表 print(result)
re.finditer() 迭代器,返回得结果放到迭代器中,
re.seach() 只拿到第一个结果就返回 print(result.group())
预加载:
obj = re.compile(r"\d+")
obj.findall()
s = """
<div class="abc">
<div><a href="baidu.com">我是百度</a></div>
<div><a href="qq.com">我是腾讯</a></div>
<div><a href="163.com">我是网易</a></div>
</div>
"""
obj = re.compile(r'<div><a href=".*?">.*?</a></div>')
result = obj.finditer(s)
for item in result:
# url = item.group("url")
# txt = item.group("txt")
# print(txt, url)
# print(item.groupdict())
print(item.group())
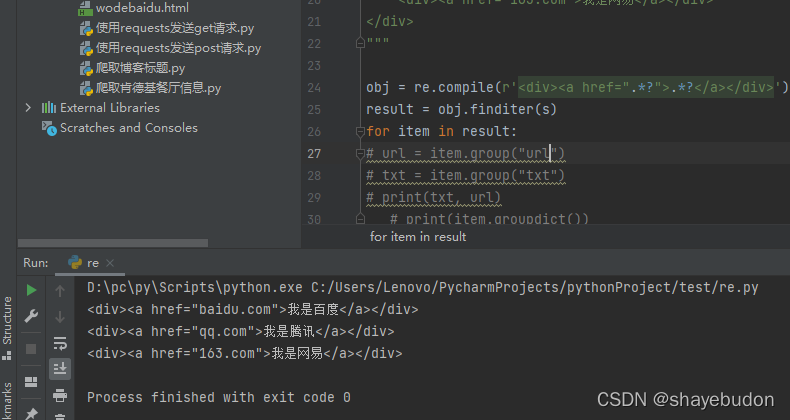
只得到了范围里面的内容,想进一步提取数据,使用 (?P<name>.*?)
obj = re.compile(r'<div><a href="(?P<url>.*?)">(?P<txt>.*?)</a></div>') r与字符串中的\区分
字符串中的\是转义符
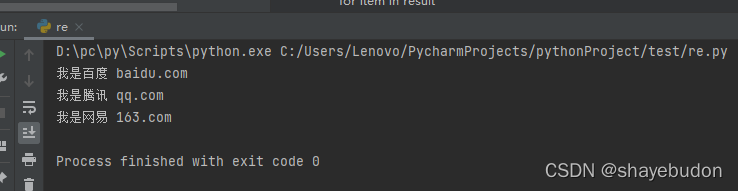
obj = re.compile(r'<div><a href="(?P<url>.*?)">(?P<txt>.*?)</a></div>')
result = obj.finditer(s)
for item in result:
url = item.group("url")
txt = item.group("txt")
print(txt, url)
# print(item.groupdict())
xpath解析
XPath,全称 XML Path Language,即 XML 路径语言,它是一门在 XML 文档中查找信息的语言。最初是用来搜寻 XML 文档的,但同样适用于 HTML 文档的搜索。所以在做爬虫时完全可以使用 XPath 做相应的信息抽取。
python3环境下安装命令:pip install lxml
xpath语法:
| 表达式 | 描述说明 |
|---|---|
| nodename | 选取此节点的所有子节点 |
| / | 从根节点选取 |
| // | 从当前节点选择子孙节点(不考虑它们的位置) |
| . | 选取当前节点 |
| .. | 选取当前节点的父节点 |
| @ | 选取属性 |
实例应用:
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8" />
<title>Title</title>
</head>
<body>
<span>我爱你</span>
<ul>
<li><a href="http://www.baidu.com">百度</a></li>
<li><a href="http://www.google.com">谷歌</a></li>
<li><a href="http://www.sogou.com">搜狗</a></li>
</ul>
<ol>
<li><a href="feiji">飞机</a></li>
<li><a href="dapao">大炮</a></li>
<li><a href="huoche">火车</a></li>
</ol>
<div class="job">李嘉诚</div>
<div class="common">胡辣汤</div>
</body>
</html>
该页面为:

# 先导入 lxml 库
from lxml import etree
# 加载数据, 返回element对象
et = etree.HTML(pageSource)
xpath语法实例:
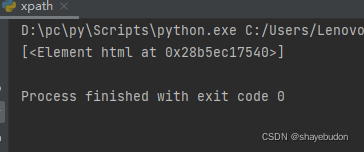
# result = et.xpath("/html") # /html表示根节点
从源代码中的html标签开始找

运行结果为:
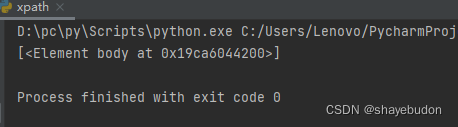
# result = et.xpath("/html/body") # 表达式中间的/表示一层html节点
从html标签中的body标签中找

运行结果为:
# result = et.xpath("/html/body/span")
从html标签中的body标签 中的span标签中找

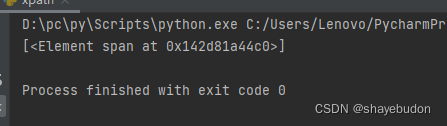
# result = et.xpath("/html/body/span/text()") # text()表示提取标签中的文本信息
先结果中显示span标签中的文字 用到text()

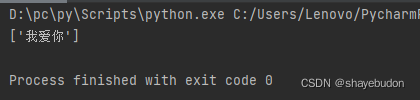
# result = et.xpath("/html/body/*/li/a/text()") # * 任意的. 通配符
*号表示在html body标签下任意标签中含有li/a
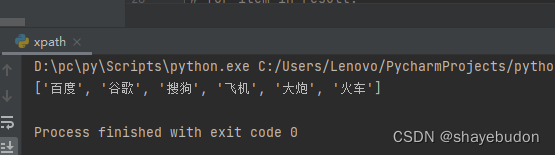

一个为ul 一个为ol 但是结果中都出现了
# result = et.xpath("/html/body/*/li/a/@href") # @表示属性
在结果中显示链接,href属于属性 加@

# result = et.xpath("//li/a/@href") # // 表示任意位置
在任意未知有li/a标签,显示href
# result = et.xpath("//div[@class='job']/text()") # [@xx=xxxx] 属性的限定
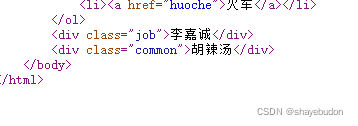
在同一标签下,想显示李嘉诚时,使用[@xx=xxx]进行属性限定
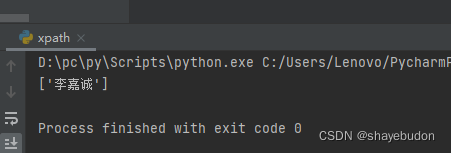
# print(result)
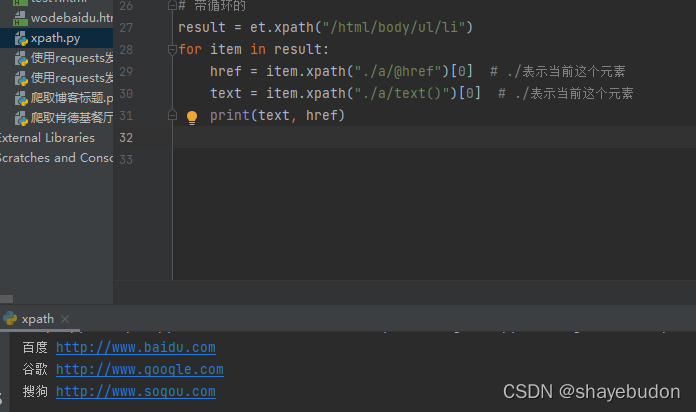
# 带循环的
result = et.xpath("/html/body/ul/li")
for item in result:
href = item.xpath("./a/@href")[0] # ./表示当前这个元素
text = item.xpath("./a/text()")[0] # ./表示当前这个元素
print(text, href)
将html改为PDF格式
使用wkhtmltopdf.exe工具
下载地址:wkhtmltopdf
在pycharm中安装pdfkit库
pip install pdfkit
在pycharm中安装whtmltopdf库
pip install wkhtmltopdf
wkhtmltopdf用法简介:
import pdfkit
pdfkit.from_url('http://baidu.com','out.pdf')
pdfkit.from_file('test.html','out.pdf')
pdfkit.from_string('Hello!','out.pdf')
from_ulr()
def from_url(url, output_path, options=None, toc=None, cover=None,
configuration=None, cover_first=False):
"""
Convert file of files from URLs to PDF document
:param url: url可以是某一个url也可以是url的列表,
:param output_path: 输出pdf的路径,如果设置为False意味着返回一个string
Returns: True on success
"""
r = PDFKit(url, 'url', options=options, toc=toc, cover=cover,
configuration=configuration, cover_first=cover_first)
return r.to_pdf(output_path)
from_file()
def from_file(input, output_path, options=None, toc=None, cover=None, css=None,
configuration=None, cover_first=False):
"""
Convert HTML file or files to PDF document
:param input: 输入的内容可以是一个html文件,或者一个路径的list,或者一个类文件对象
:param output_path: 输出pdf的路径,如果设置为False意味着返回一个string
Returns: True on success
"""
r = PDFKit(input, 'file', options=options, toc=toc, cover=cover, css=css,
configuration=configuration, cover_first=cover_first)
return r.to_pdf(output_path)
from_string()
def from_string(input, output_path, options=None, toc=None, cover=None, css=None,
configuration=None, cover_first=False):
#类似的,这里就不介绍了
r = PDFKit(input, 'string', options=options, toc=toc, cover=cover, css=css,
configuration=configuration, cover_first=cover_first)
return r.to_pdf(output_path)

















 638
638

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









