



 本文介绍了条件GAN(Conditional GAN)的应用,包括文本到图像的生成,无监督条件生成的两种方法——Cycle GAN和Stack GAN。Cycle GAN通过两次转换确保输入与输出之间的关系,而Stack GAN则通过逐步生成高分辨率图像。此外,还探讨了D(判别器)的角色以及在语音增强和视频生成中的应用。
本文介绍了条件GAN(Conditional GAN)的应用,包括文本到图像的生成,无监督条件生成的两种方法——Cycle GAN和Stack GAN。Cycle GAN通过两次转换确保输入与输出之间的关系,而Stack GAN则通过逐步生成高分辨率图像。此外,还探讨了D(判别器)的角色以及在语音增强和视频生成中的应用。
Conditional GAN
输入文字,输出图片。text to image
D要判别:x是否是真的 + x和c是否匹配
D的输入是G的输入c(文字)和输出x(照片),是一组键值对。即D要同时看G的输入和输出。
D什么时候给低分:①G生成的图x模糊 或者 ② G生成的图x清晰,但是生成的图x和文字c不匹配
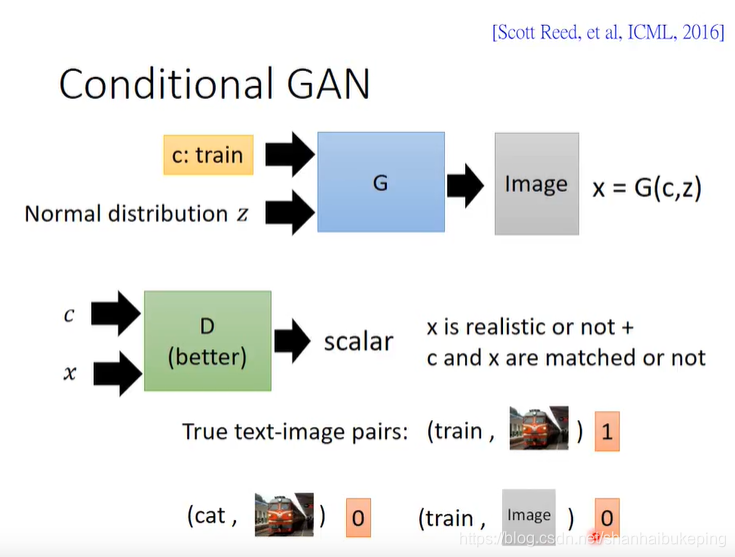
下面的结构更合理:两个输出,可以看出造成D分值低的原因是①还是②

Stack GAN
先产生小图 (6464),再根据小图产生大图(256256)
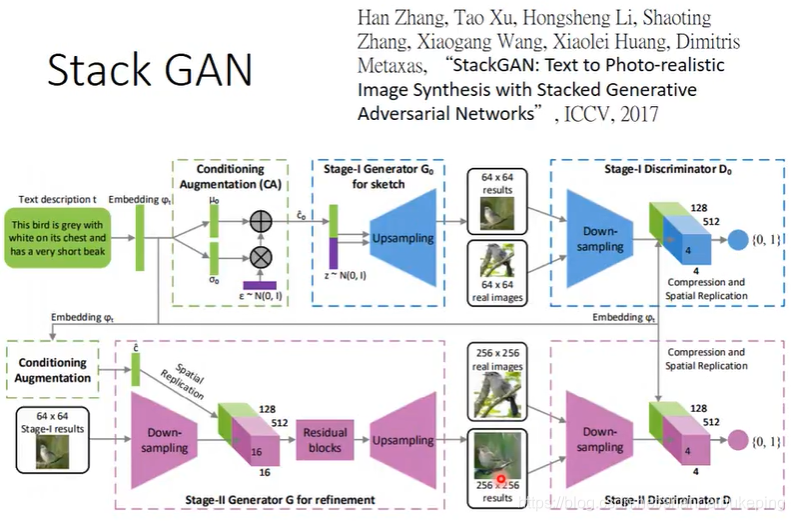
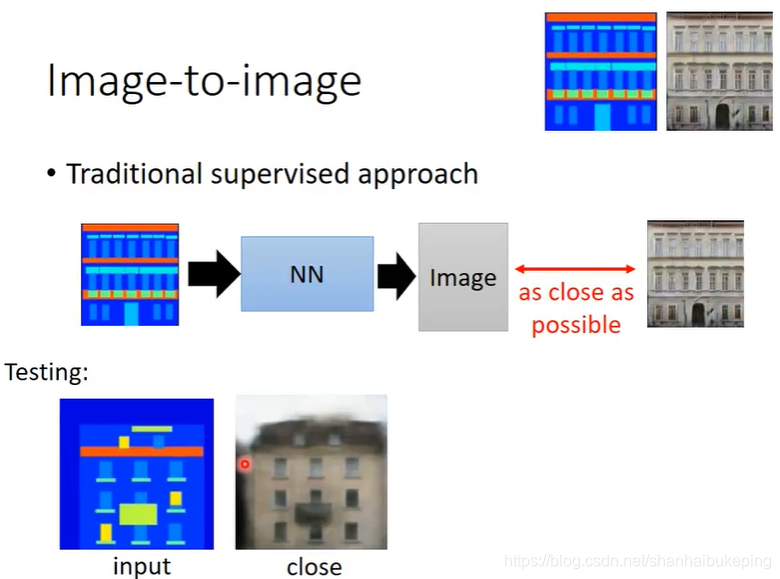
image-to-image
NN:输入一张图,生成一张图,产生的图片比较模糊
GAN:
D检查G的输入和输出是否为一对。
单独的GAN可能会生成奇怪的东西,此时加上一个constrain:希望G生成的图与输入的图差异不大。其结果GAN+close就会好很多。
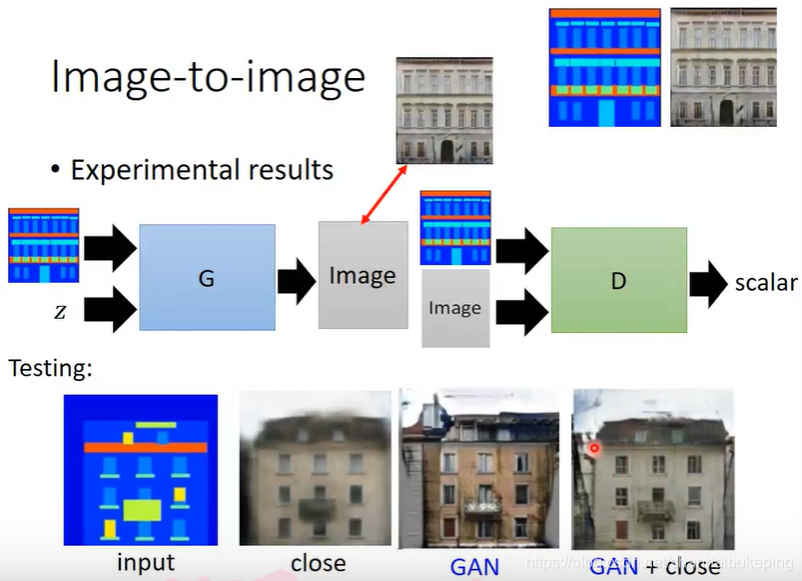
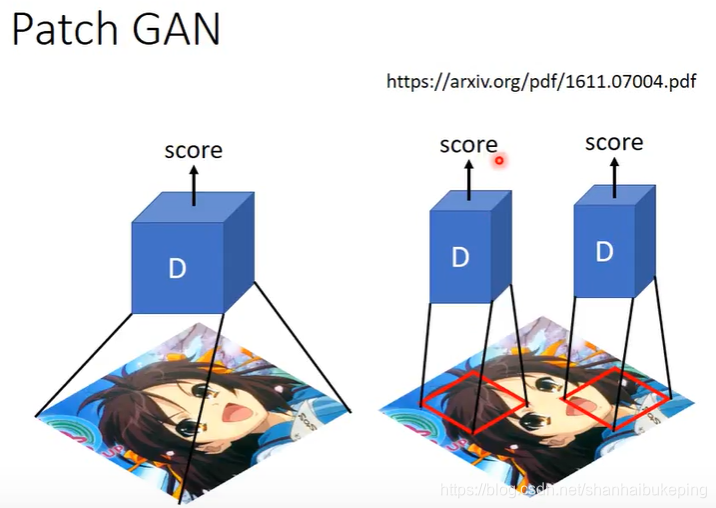
D只看一小块,叫Patch GAN
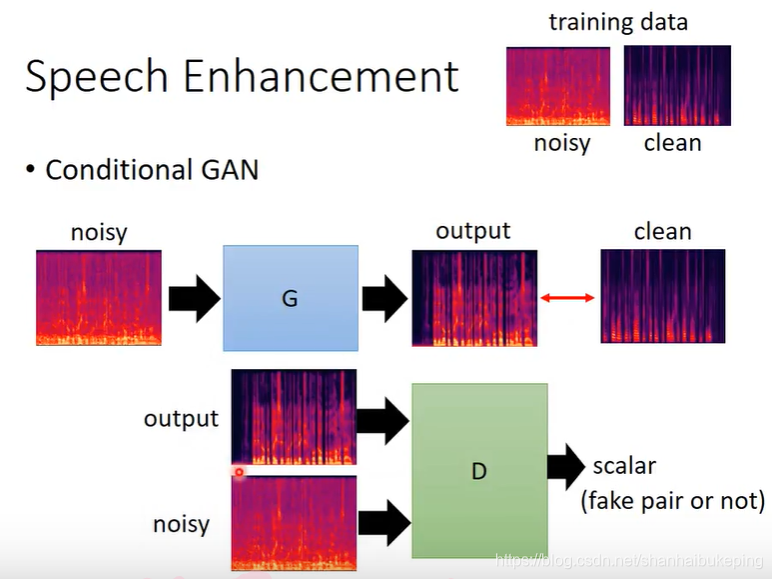
Speech Enhancement
D的输入也是两个:G的输入和输出
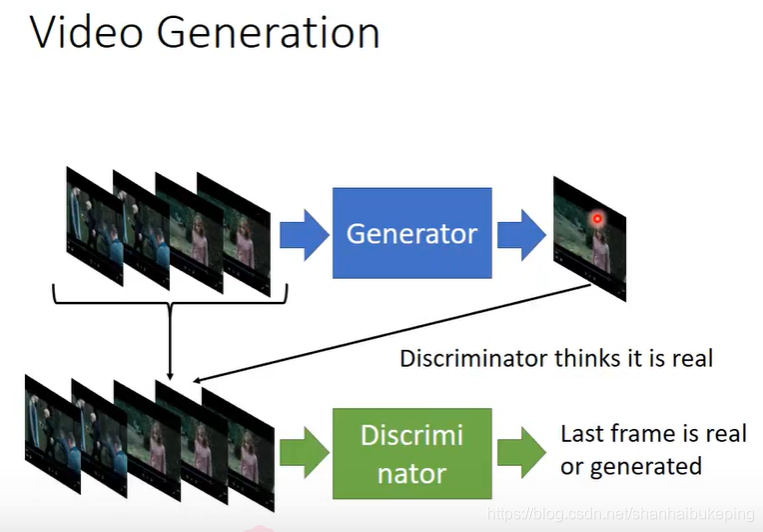
Video Generation
D的输入也是G的输入和输出。
unsupervised conditional generation
两种方法:
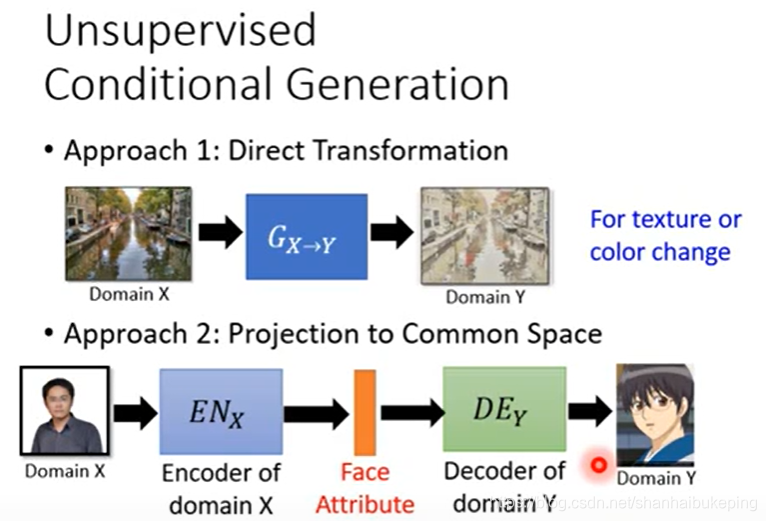
方法一:
给G输入一张照片c,让他输出一张经过处理的照片c
有Domain X 和 Domain Y,但是没有X和Y的联系关系
给 X 怎么知道输出 Y
Domain Y的Dy的作用:输入一张照片,判别这张照片是否属于Domain Y
G的作用:生成一张风景老照片欺骗Dy
问题:如果G生成一张跟输入无关的人物老照片,怎么办
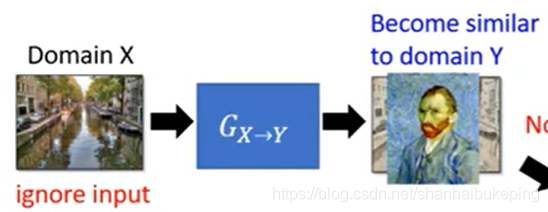
目的:希望G骗过D,且G的输入和输出有一定的关系
最简单的做法:不管这个问题
Cycle GAN:两次转换
X->Y->X
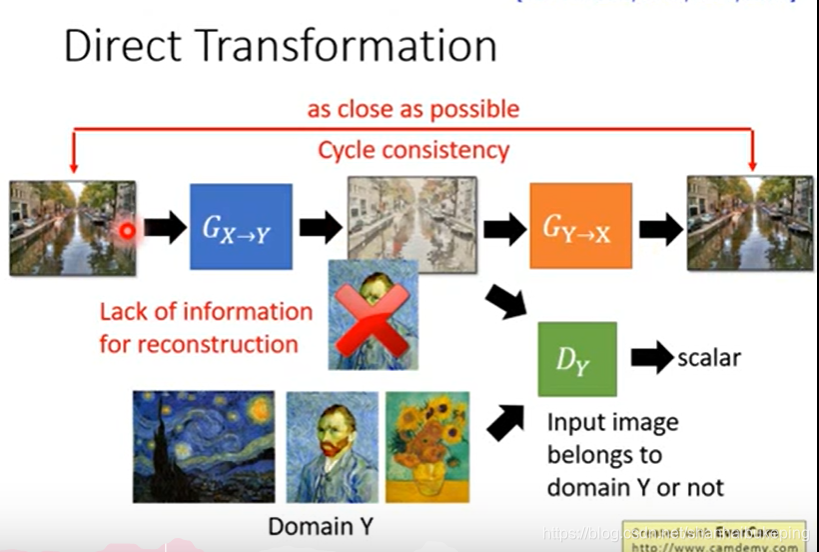
Y->X->Y
Gy->x,让Dx确认生成的是x的图,再把x转成y,仍希望input和output越接近越好。
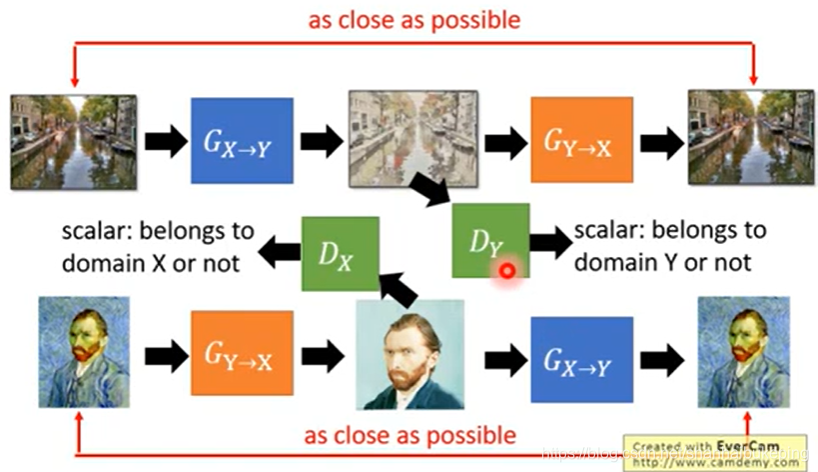
方法二:
目标:如果是supervised,很简单,但是现在是unsupervised
如何建立ENx和DEy之间的关系
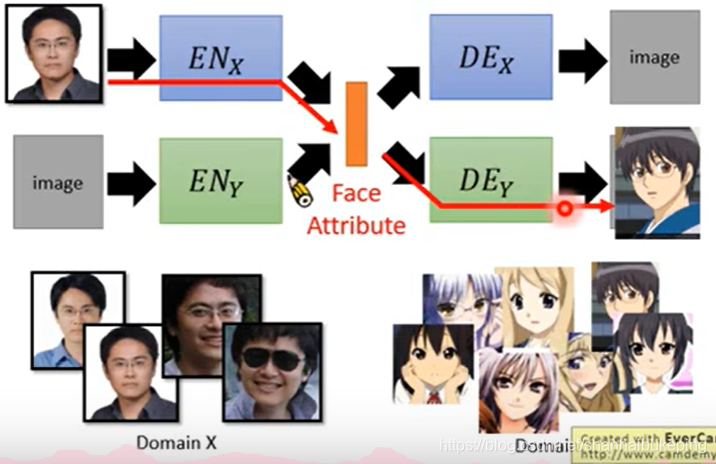
x的encoder和x的decoder组成auto encoder;y的encoder和x的decoder组成auto encoder。
input一张x,reconstruct一张x的图;input一张y,reconstruct一张y的图;
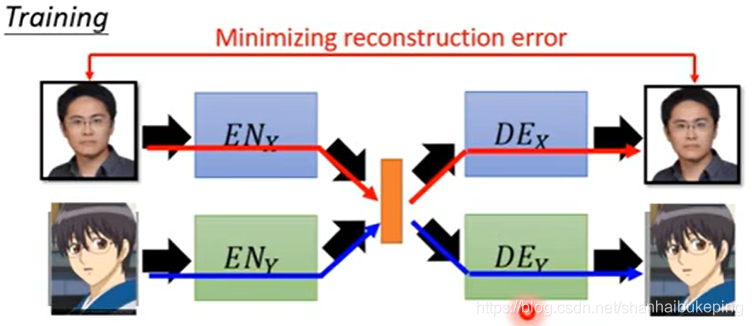
但是这样x和y没有任何关系。因为x和y是分别训练的。
解决方法:
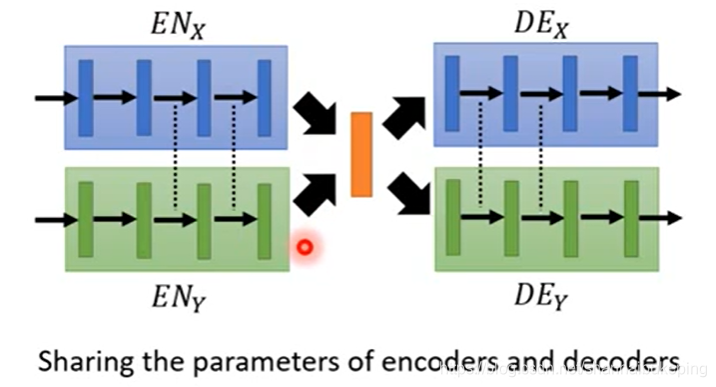
①使ENx和ENy的后几层共用,使DEx和DEy的前几层共用。
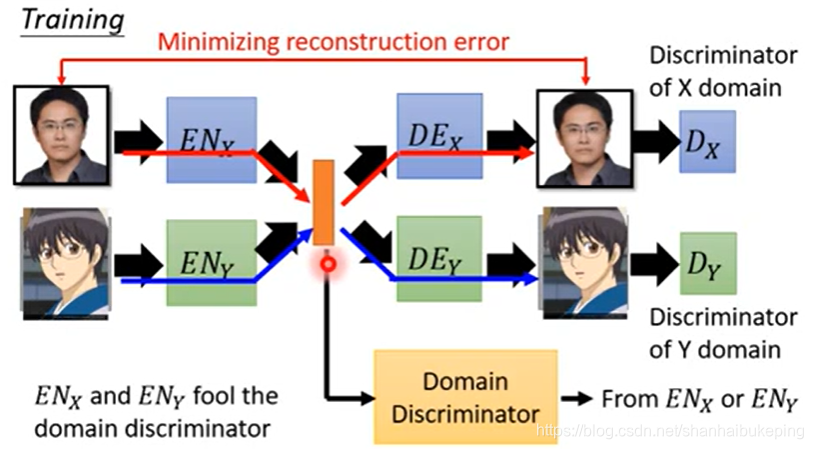
②加一个domain discriminator
判断橙色块的vector来自于ENx还是ENy
ENx和ENy要欺骗domain discriminator,使它判别不出来

















 350
350

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









