



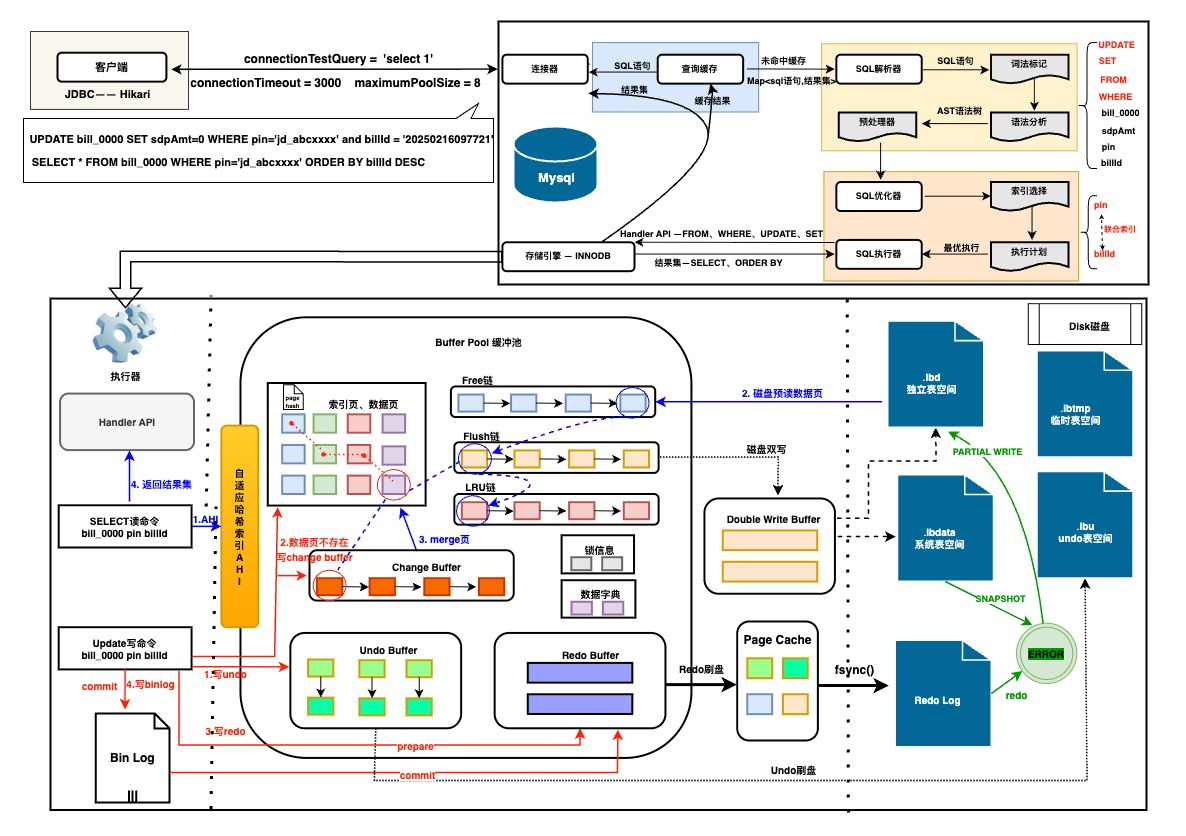
一、MySQL基础架构
MySQL总的可以分为两层:服务层和存储引擎层。
- 服务层负责与客户端建立连接及交互,包括连接器、查询缓存、解析器、预处理器、优化器、执行器等;
- 存储引擎层负责操作数据库并与服务层交互,主要包括插件式存储引擎。
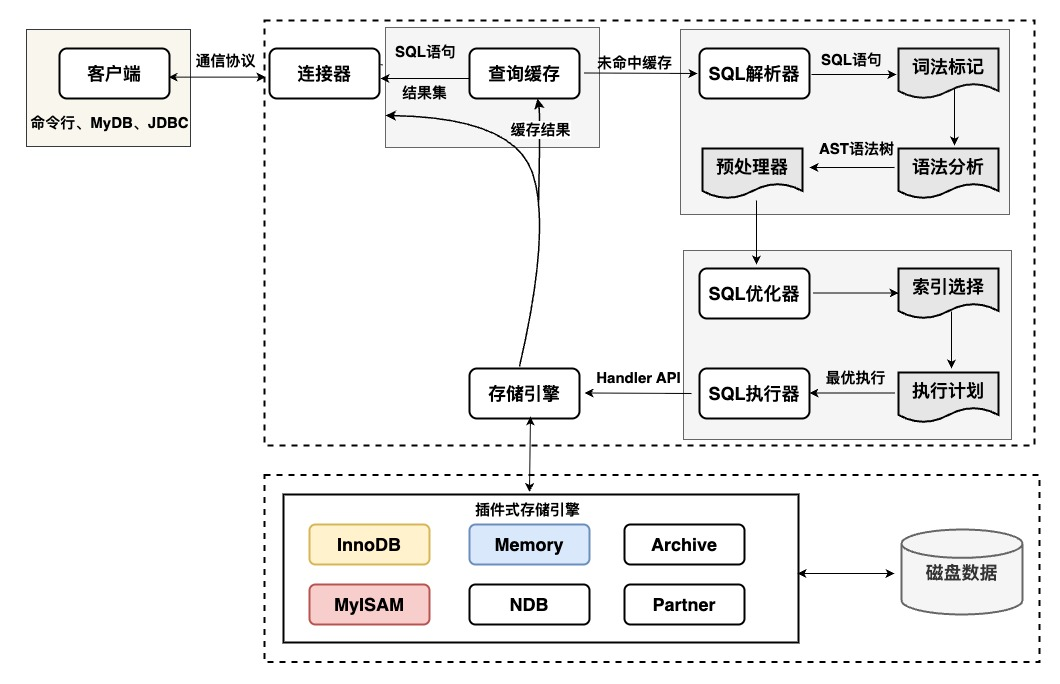
- 客户端:通过交互式连接(命令行、图形化用户界面)或非交互式连接(JDBC)与服务器交互
JDBC连接池可以有效管理MySQL活跃连接,减少创建和销毁连接的开销。参数配置:最大连接数、最小连接数、SQL等待时间、连接生命周期等
- 连接器:负责用户的身份认证工作(校验账户密码、库表权限等)
thread_stack:连接线程可使用的栈空间,不宜设置过大,一版使用默认值,可以限制内存消耗、探测不合理SQL、是一种连接保护参数
- 查询缓存(已废弃):记录执行的SQL语句及结果,废弃原因:
- 每次查询条件有一点不同,就无法命中缓存
- 需要大量额外的缓存空间储存开销
- 性能影响:触发表级锁的数据更新操作可能导致表缓存批量失效。存储成本&一致性开销
- 解析器:语法解析,将SQL拆解为结构化指令
- 词法标记:分词,标记关键字和非关键字(表名、列名、查询条件等)
- 词法分析:将SQL解析成一颗AST抽象语法树,并校验关键字是否合法,非关键字表名、列名是否存在等
- 预处理器:占位符参数替换为常量表达式;子查询展开为等价的join操作以便更好利用索引;确定复杂操作的操作顺序等。
- 优化器:对SQL语句进行分析与优化:通过考虑表索引、数据分布、查询条件等,计算IO成本(磁盘数据读取次数)、CPU成本(运算操作计算量),生成“最优”的执行计划
- 样本选择与成本计算。索引基数Cardinality——索引中不同值的数量,越大表示索引区别度越大,该索引将被优先选择使用。其他选择依据:二级索引成本、回表成本、临时表成本等。
Cost = Server Cost + Engine Cost = CPU Cost + IO Cost
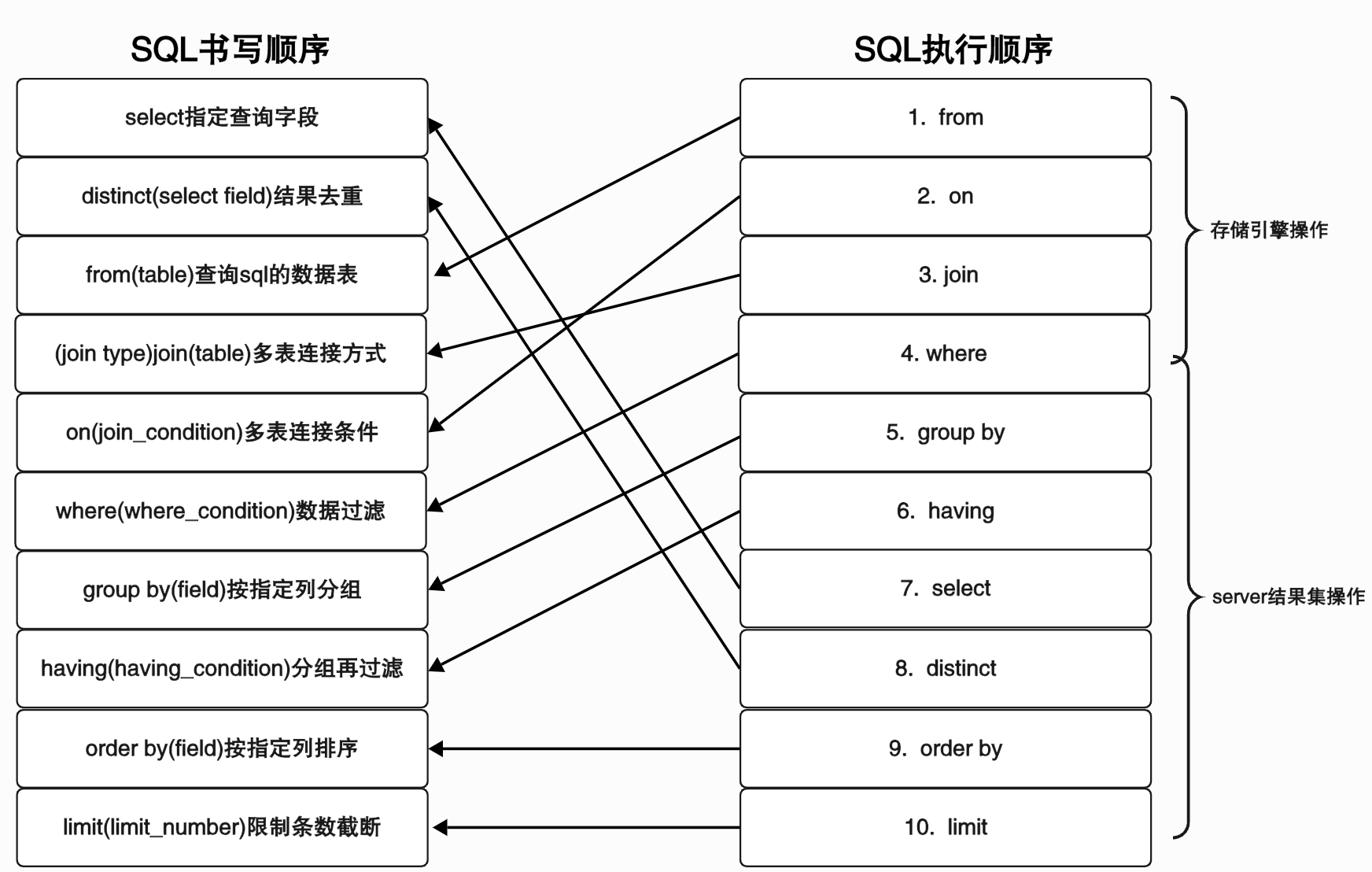
- 执行计划:使用explain命令可查看某条sql优化后的执行计划,参数如下:
|
参数 |
含义 |
|
id |
执行序列号,id值越大优先级越高,越先被执行 |
|
select_type |
查询类型
|
|
table |
对应的表名 |
|
type |
性能由高到低:
|
|
possible_keys |
可能用到的索引字段 |
|
key |
实际用到的索引字段 |
|
key_len |
实际使用索引的最大长度和 |
|
ref |
等值查询时,与索引比较的列或常量 |
|
rows |
估算出的扫描行数,越小越好 |
|
filtered |
按表条件过滤后条数/rows,留存记录的百分比 |
|
extra |
附加信息:
|
- SQL执行器:根据优化器选择的执行计划,调用存储引擎读取、更新数据,并对返回的数据页进行排序、过滤、分组和聚合等操作,最终将处理后的结果返回客户端。
- 存储引擎:负责数据的存储与读取,采用插件式架构,支持InnoDB、MyISM,Memory等多种存储引擎。
|
MyISM |
适用读取、写入的场景,读写不能并发,只有少量更新、删除的操作,对事务完整性、并发性要求不高的场景 |
|
InnoDB |
要求事务完整性,高并发情况下数据一致性,更新、删除操作多的场景(支持事务、行级锁、崩溃恢复等) |
|
Memory |
适用于数据少,需要快速访问的场景(使用较少) |
二、InnoDB存储引擎
存储引擎设计原则:内存速度远高于磁盘,一切的逻辑处理、读取写入都只操作内存中的数据
缓冲池的内存命中率通常应该保持在95%以上,否则应该检查缓冲池总大小的设置,及LRU链表是否被污染
1、InnoDB运行概览
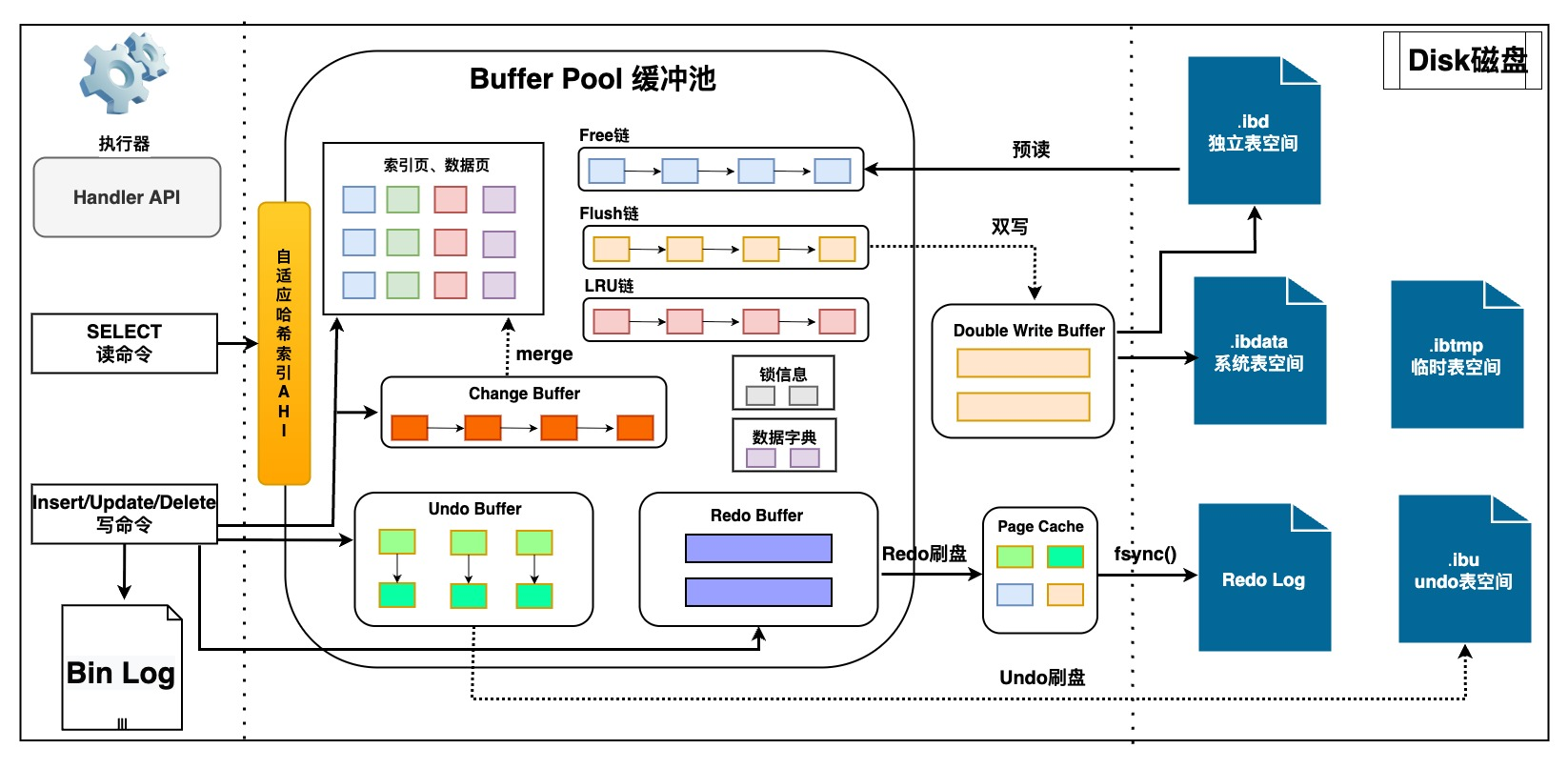
- 执行器调用
InnoDB存储引擎,开启事务并将数据旧值记录到Undo Log Buffer,从而可进行事务回滚,实现原子性;辅助read view实现MVCC,实现隔离性; - 若
Buffer Pool无对应数据页,则从磁盘加载数据页到缓存中;将数据新值写入Buffer Pool后,由后台IO线程异步刷盘(因为数据页随机IO刷盘耗时较大); - 写入
Redo Log Buffer缓存(prepare),并马上写入Redo Log文件,从而可在崩溃时恢复未刷盘的业务数据,实现持久性;且Redo为顺序IO刷盘,耗时很小。
Redo Log刷盘策略可配置,可靠性从高到低依次为:- 1(默认):事务提交后同步写入系统缓存pageCache,立即同步fsync()刷盘
- 2:事务提交后同步写入系统缓存PageCache,每秒fsync() 刷盘
- 0:事务提交后不触发,每秒异步写PageCache,异步fsync()刷盘
- 事务提交时,写入
MySQL的Bin Log,并将Redo Log状态设置为commit
Bin Log二进制编译后为逻辑日志,可以用于变更历史查询,数据库备份和主从复制等- 1(默认):事务条后同步写入系统缓存PageCache,同步fsync() 刷盘
- 0:事务提交后同步写入系统缓存PageCache,异步fsync() 刷盘
- N:每N次事务提交后写入系统缓存PageCache,异步fsync() 刷盘
- 后台线程进行数据刷盘时,会先将数据页写入
Double Write Buffer中,防止页断裂(partial write)问题,最后从Doubke Write Buffer写入实际的数据文件中 - 若是读
SQL语句,则需要检查Change Buffer中是否有记录,若存在需要将Change Buffer和Buffer Pool数据页合并,再返回给执行器处理并响应给客户端。
2、文件存储
磁盘文件中:行页的物理存储关系,区组段的映射关系,B+树的数据结构
.frm文件:存储表相关的元数据,包括表结构的定义信息,每张表对应一个frm文件.ibd文件/.ibdata文件:存储数据与索引。5.7 之前所有表的数据和索引存储在共享表空间.ibdata文件,5.7版本后会为每个表生成一个独享表空间.ibd文件,具有可压缩、可传输等优势。
2.1 数据页
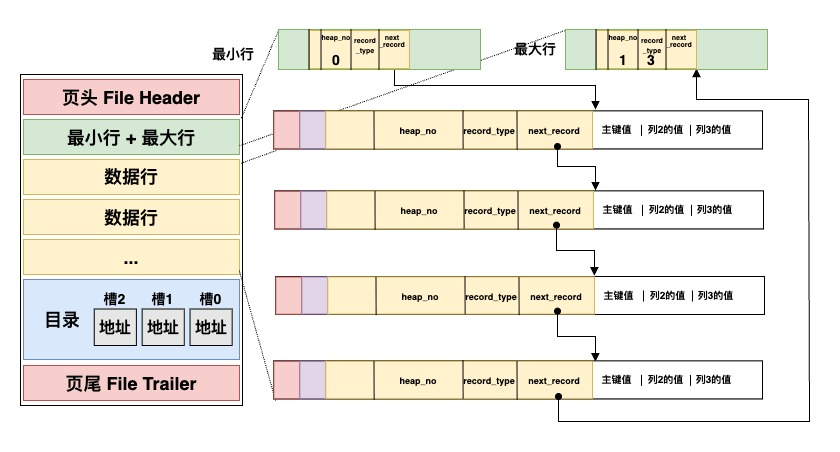
ibd文件的结构体为页,是InnoDB中内存和磁盘交互的最小存储空间,buffer pool中的存储单位也是页。每个页内部地址是连续的,适配计算机局部性原理。最常用的页类型:索引页、数据页,其余还有Undo Log页、Change buffer页等。页大小固定为16KB,无数据也是16KB,每次读取/写入磁盘也都固定为16KB。
File Header存有:唯一的页号、页类型、表空间ID、上页页号、下页页号、校验和,通过两个指针指向上一页和下一页(双向链表),使得页面之间逻辑连续。页头File Header和页尾File Trailer中存有校验和,用来校验页的完整性,辅助解决页断裂问题。
8条数据行构成一个组,行之间由单向链表连接。页目录的槽记录了组内最后一个行在页中的地址,可以做到加速查找:如果定位到了一个页,可以先在页目录中二分查找到在哪一个槽组,然后在组里遍历最多8次即可找到对应的行,复杂度O(log2N)+O(8)。
PS: MySQL5.6开始支持innodb_page_size自定义页大小(4KB、8KB、16KB、32KB、64KB),但16KB的默认页大小是 InnoDB 在多年实践中验证的“黄金平衡点”,兼顾了 I/O 效率、内存利用率、索引性能、硬件适配性和事务可靠性。- 磁盘I/O成本:HHD、SSD随机IO性能较差,较大的页能减少单次查询或写入所需 I/O 次数。
- 内存利用率:页过大则Buffer_Pool中可命中页数量变少,页过小则可能频繁I/O。
- 数据结构适配性:页越大则树的高度会降低,但是页内查询与管理成本会提高。
- 历史延革与标准:早期设计行业的普遍设计延续,如Oracle 默认块大小也为 8KB/16KB。
- 文件系统兼容:多数文件系统(如 ext4、XFS)的默认块大小为 4KB,16KB是4KB的整数倍,与文件系统块边界对齐,减少跨块读写。
2.2 数据行
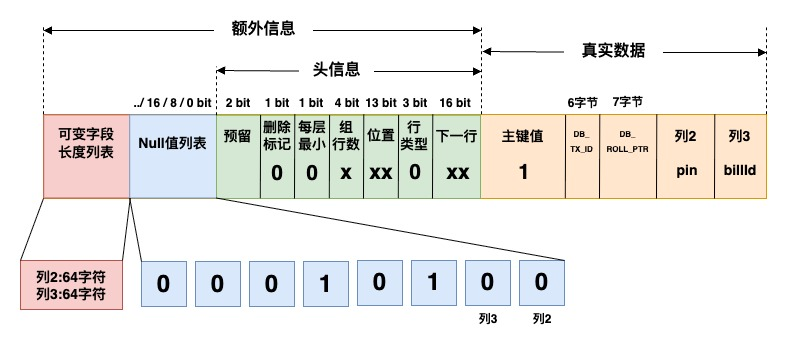
页中的数据行最大为8KB,大小不固定,与表里的数据行一一对应,每页的数据行构成单向链表。
|
列名 |
含义 |
|
主键值 |
主键id、唯一索引,若都无则自动生成一个DB_ROW_ID行唯一标识 |
|
DB_TX_ID |
当前所属事务ID号,辅助实现MVCC多版本并发控制 |
|
DB_ROLL_PTR |
回滚指针,指向Undo Log版本链,回滚指定版本 |
|
删除标记 |
delete后不会删除数据,而是设置删除标记,并将其从数据链表中断开,并指向垃圾链表 |
|
可变字段长度列表 |
每个列可用1~2字节表示,列字节数为0~255时,占用1字节表示;字节数256~65535时,占用2字节表示。最大可为16bit,2^16可以表示65535字节=16383字符 utf8mb4(Mysql5.7允许的varchar长度上限)。可变长字段太大可能本页放不下,会将字段单独放到一个溢出页。 |
|
Null值列表 |
为null值的字段,将在列表中(bitmap)分别用1bit位记录 |
- 直接删除数据可能导致关联数据页的移动,页分裂引发更多的碎片,所以delete选择延迟删除数,从数据链断开并指向垃圾回收链表,delete的位置后续可能被重用(空白空间没有被合适大小的数据占用则产生碎片)
- 大批量delete语句会写入Bin Log、Undo Log导致磁盘占用上升,因此需要通过磁盘碎片回收释放空间:optimze table、alter table engine=innodb,重建表、重组数据索引页数据实际删除。
2.3 区、组、段
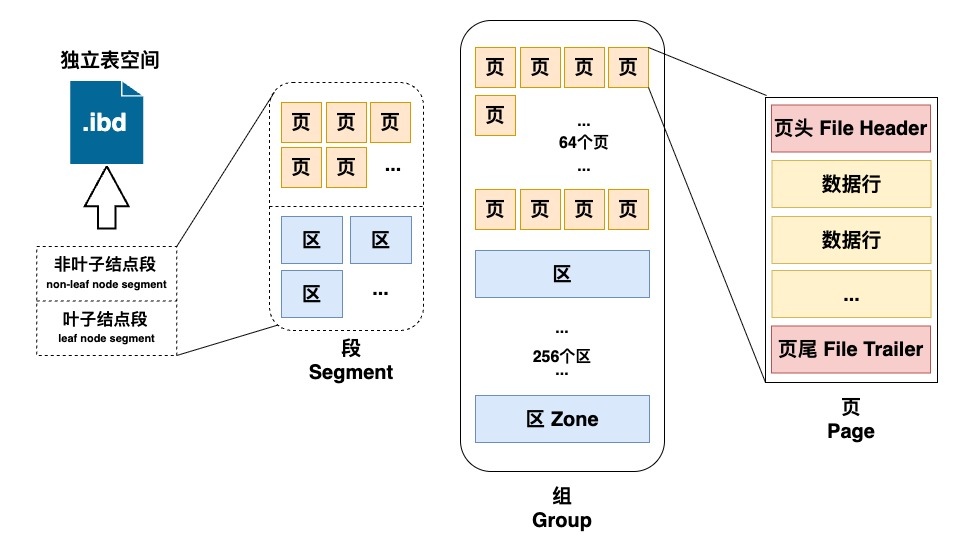
- 区:固定
1MB,开辟一块空间存放地址连续的64个页。若该区上的页被频繁读取,则将一整个区读出来,即进行区级别的预读
|
预读类型 |
触发时机 |
预读内容 |
|
随机预读 |
一个区的多个页面被非连续但集中访问超过13次(索引随机扫描) |
异步将本区剩余页面预读至 |
|
线性预读 |
一个区的多个页面被顺序访问(范围查询、全表扫描) |
异步预读相邻的下一个区,显著提升顺序扫描性能(innodb_read_ahead_threshold控制阈值) |
- 组:
256个区构成一个组,存有区组信息,便于高效定位管理区组。 - 段:一个逻辑概念,由多个区组成的逻辑单元,用来标注区、页的相关信息。数据段(叶子节点段)管理实际数据,索引段(非叶子节点段)管理索引信息,回滚段管理
undo log数据。
2.4 存储逻辑结构
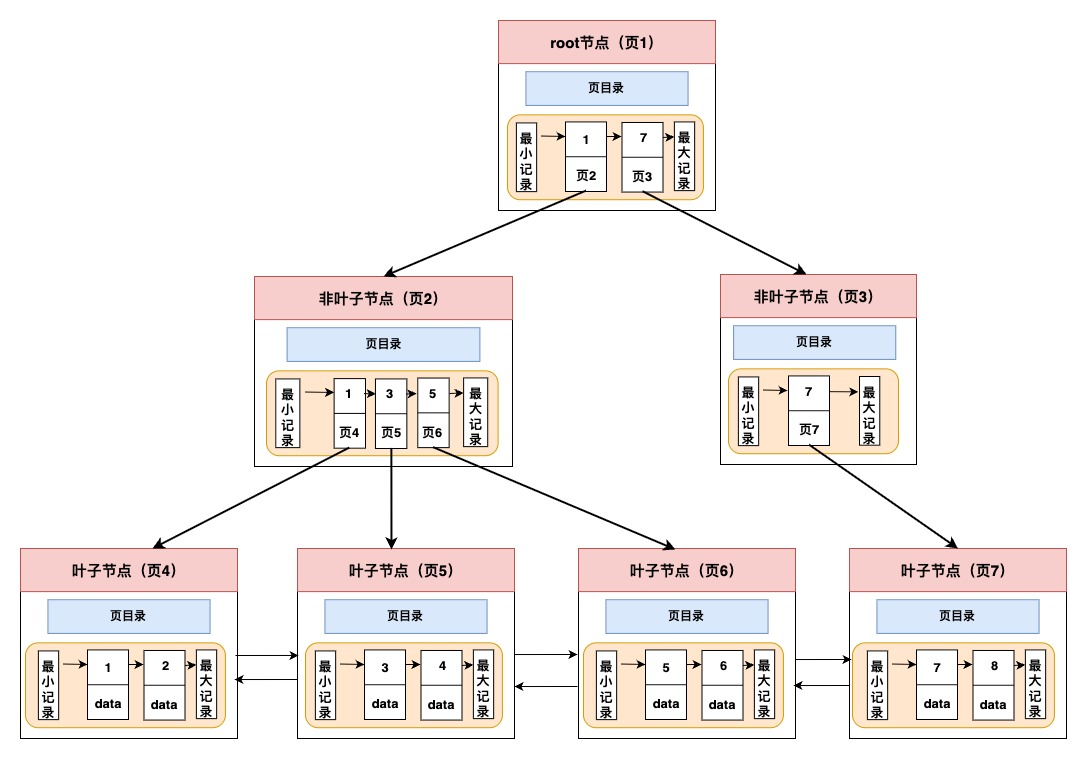
文件存储采用B+ 树逻辑结构,快速定位到页所在的位置;只有叶子节点存放数据,非叶子节点仅用来存放目录页作为索引。所有叶子节点按照索引大小排序,构成一个双向链表,便于范围查询。
2.5 Online DDL
针对海量且复杂的数据存储结构,实现高效OnLine DDL操作
MySQL处理DDL的算法主要有三种,Rebuilds Table、Inplace、Instant;算法流程主要分为准备阶段、执行阶段(耗时最长,关键在于此阶段是否阻塞DML)、提交阶段。
|
Rebuilds Table |
Inplace |
Instant |
|
MySQL5.6之前的默认方式,完全阻塞DML。 准备阶段:对表元数据加排他锁,创建临时表。 执行阶段:锁表阻塞DML,原表数据copy,临时表重命名,删除原表。 提交阶段:提交事物释放锁。 |
MySQL5.6之后支持,二级索引创建可原地执行,较短时间阻塞DML。 准备阶段:对表元数据加排他锁,创建临时文件,申请row log临时空间(buffer pool)存放执行阶段DML 。 执行阶段:排他锁转为共享锁,扫描数据存储到临时文件,记录DML到row log 。 提交阶段:锁表阻塞DML,重做row log,临时表重命名,删除原表,提交事物。 |
MySQL 8.0 版本支持,允许对表进行一些结构改变,而不需要重建整个表,较短时间阻塞DML。 添加列时,无需使用新表拷贝,而是添加到数据字典中并关联默认值,如果某一行没有新列的物理数据这返回默认值 删除列时,标记为隐藏 。 添加非唯一性索引时,立刻返回完成,在后台逐步构建出完整索引结构。 |
MySQL对索引和列调整的大部分动作,都支持OnLine DDL,只有添加全文索引、空间索引、变更列类型等少数操作,才不支持并发DML。
|
Online DDL |
Pt DDL | |
|
优势 |
执行速度快,不太需要临时空间、开销小 |
主从延迟很小,旧表碎片可完全释放 |
|
劣势 |
从库DDL执行开始时,主从复制延迟时间主键变大,直至从库DDL完成。某些场景下,可能会缩表 |
需要拷贝整个旧表数据到新表临时空间,磁盘IO上升,执行时间较长;拷贝数据时产生大量Bin Log,空间开销较大 |
|
适用场景 |
执行时间要求严格 |
从库延迟要求严格,缩表要求严格 |
3、Buffer Pool
InnoDB的高速内存,,实现数据当问“零延迟”
3.1 内存管理
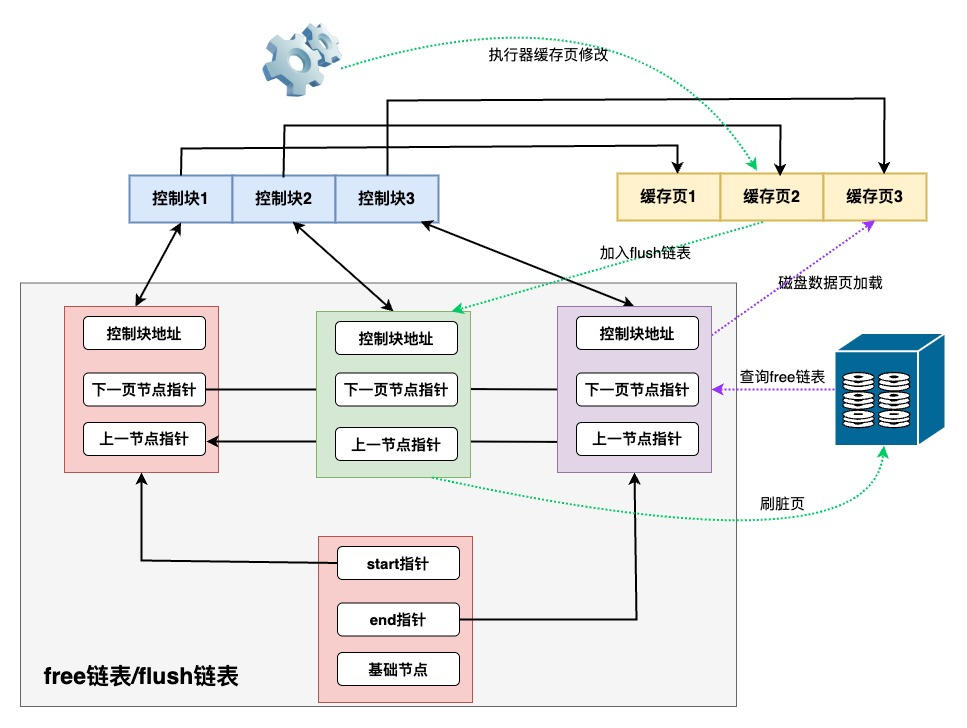
Buffer Pool是InnoDB内存中的最大一块内存,存有各项数据页、索引页、undo页、锁信息等。让有限的内存以最高的命中率处理数据请求,就是Buffer Pool 存在的意义。为了更好的管理这些缓存页,InnoDB为每个缓存页建立了对应的控制块,控制块信息包括了缓存页的表空间、页号、地址等。Buffer Pool初始化时,会生成空的缓存页与控制块,从磁盘中读取数据页后会讲数据和描述信息填入。
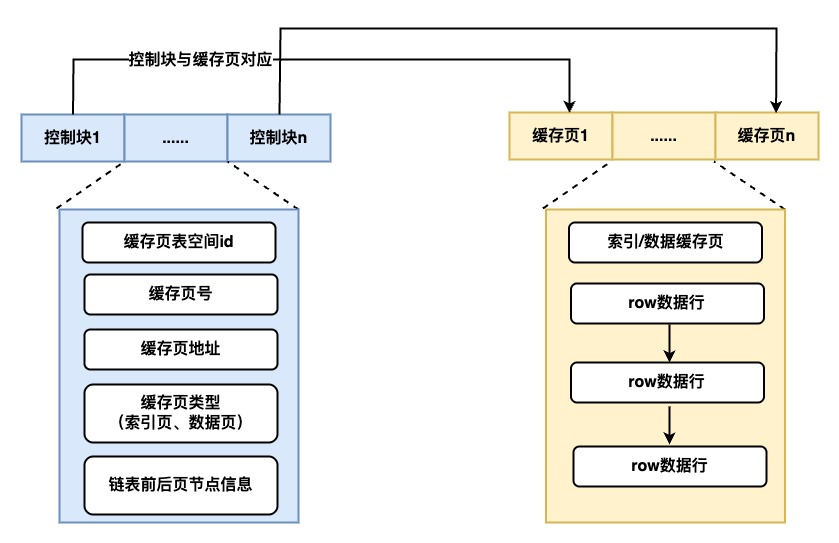
InnoDB通过free空闲链表、flush刷盘链表、LRU淘汰链表,三个链表来管理Buffer Poll的内存空间,有效管理空闲页、脏页、数据页。在Buffer Pool还包含一个page_hash的hash table,通过space_id和page_no作为key,对应缓存页的地址作为value,快速找到LRU List中的page,避免扫描整个List,极大提升了Page的访问效率。
- free list 定义当前没有存数据、处于空闲状态的页。当disk磁盘中的页放入到Buffer Pool缓冲池中时,就会从free List中查找是否有空闲页,如果有就将空闲页从free List中取出使用,并放入LRU链头部;如果没有,就会淘汰LRU链尾部的数据页,并分配其使用;若LRU链都为脏页无法被回收,则会触发刷脏。
- flush list 中存储了当前内存中的脏页,后台线程遍历fulsh链表将脏页写入磁盘。
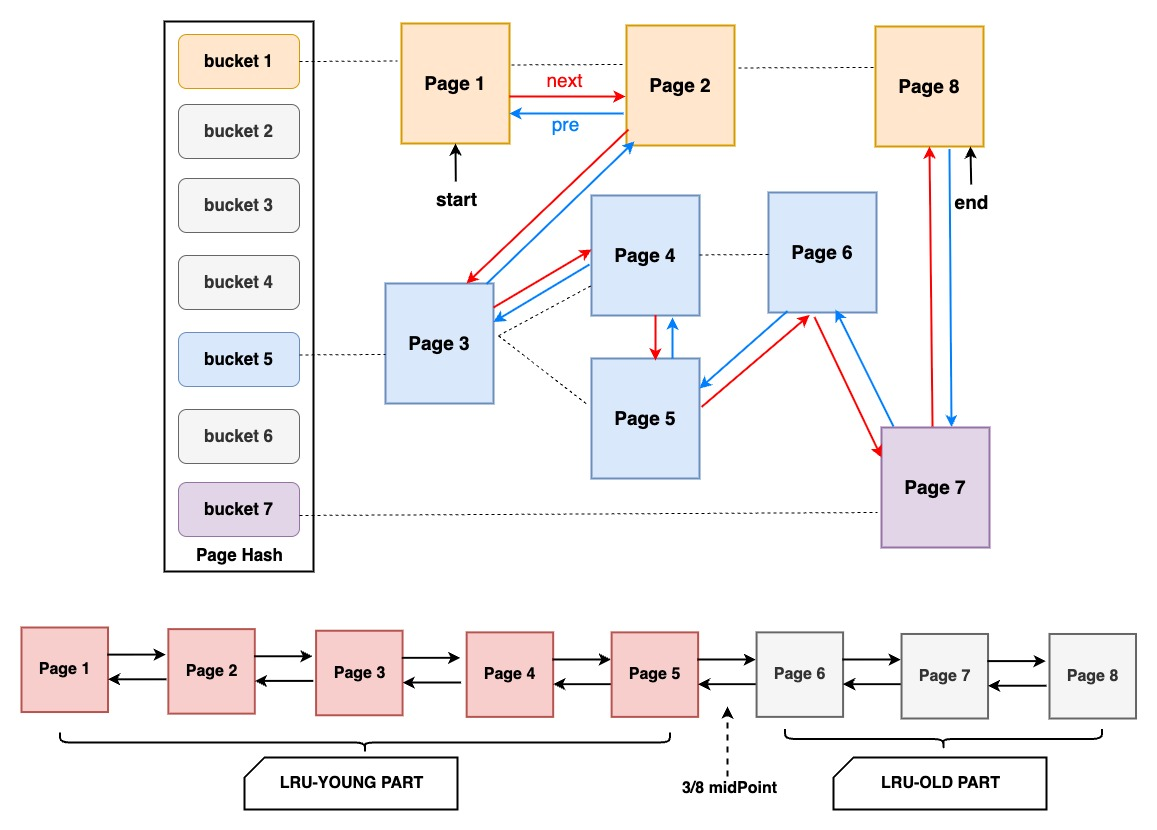
- LRU算法:常见的实现方式是使用
双向链表和哈希表,哈希表用于快速查找数据是否在缓存中,而双向链表用于记录数据的访问顺序。当数据被访问时,它会被移动到链表的头部,表示最近被使用;当需要淘汰数据时,可以选择链表尾部的数据,因为那些数据是最近最少被使用的。 - LRU list:从数据文件中新读取进来的页都会缓存在LRU list,并使用 LRU 算法管理页,当内存满的时候淘汰最久没有被使用的数据(链尾数据),以释放内存空间。但直接应用原始LRU算法会产生两个问题:1)预读失效;2) Buffer Pool 污染。
3.2 Undo Log Buffer
undo log回滚日志是逻辑操作日志,以表为维度,记录事务ID、数据行的变更值
- 增:insert语句,对应delete,记录主键ID
- 删:delete语句,对应insert,记录原内容全部内容
- 改:update语句,对应逻辑相反的update,记录修改字段的旧值
对同一条数据,对应的undo 版本链有两条:
- insert undo链:只记录新增操作,事务提交后即可删除
- update undo链:记录删除和更新操作,用于:
- 事务回滚:每个事务对应一组undo版本链,每条数据行的DB_ROLL_OTR指向undo链,在发生错误时可回滚到事务之前的数据状态
- 多版本并发控制(MVCC):配合read view控制各个隔离级别事务的可见数据,保证多个事务的数据一致性,
3.3 Redo Log Buffer
redo log重做日志是物理操作日志,记录的是页维度内容,页号、偏移量、页内修改内容等,顺序IO读写,存储量小读取快;通过innodb_flush_log_at_trx_commit参数控制刷盘策略
- 设置为0提供异步刷盘策略,最佳性能但最低安全性;
- 设置为1提供提交事务后同步刷盘策略,安全性最高
redo log与bin log通过两阶段提交协调工作,:当开启事务后:
- redo先标记prepare工作
- 写入bin log并执行fsync系统调用执行磁盘同步
- 在redo 日志记录标记commit表示提交完成
- 使用两阶段提交后,写入bin log时发生异常也不会有影响,MySQL在使用redo log恢复时,发现redo log还处于prepare阶段,且此时没有bin log,认为该事务未完成提交,会回滚此操作;
- redo log在commit阶段发生异常,虽然MySQL重启后发现redo log是处于prepare阶段,但是能通过事务ID找到对应的bin log记录,MySQL认为此事务执行是完整的,就会提交事务恢复数据。
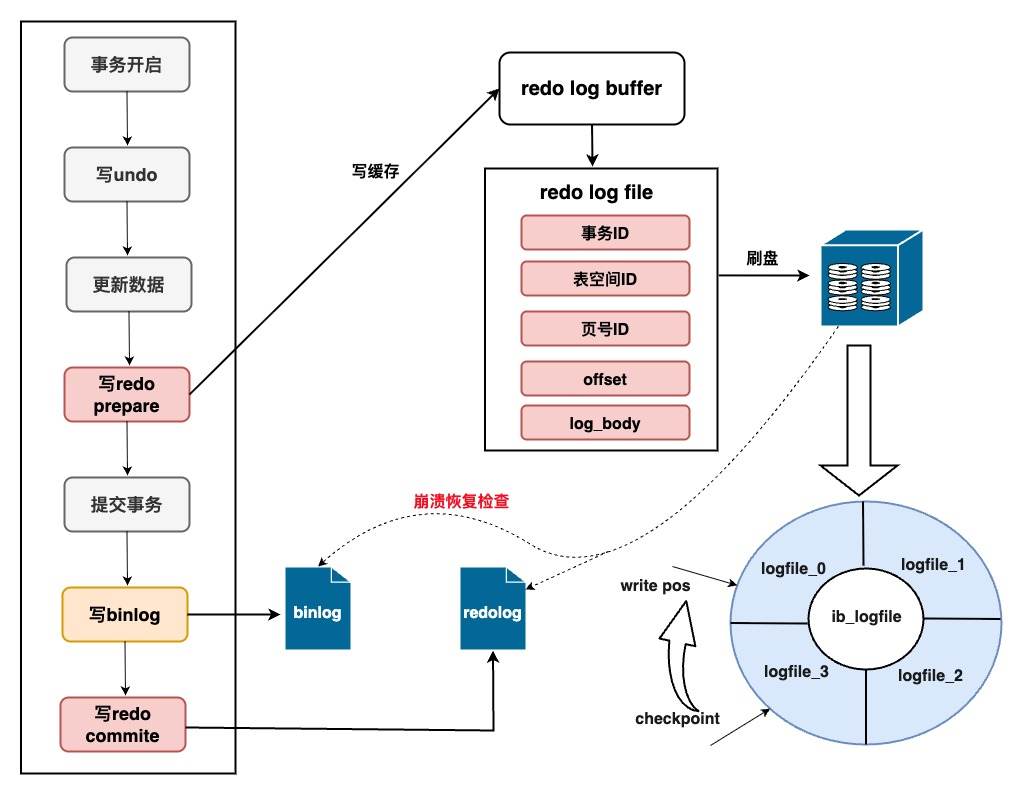
redo log文件组为避免日志不断写入,设置了write pos和checkpoint。write pos是当前记录的位置,一边写一边后移;checkpoint是当前要擦除的位置,也是往后推移。当buffer pool脏页刷库后,checkpoint将后移更新;加载日志文件恢复数据后,checkpoint也会后移更新;崩溃时只需恢复checkpoint之后的数据即可。
|
日志名称 |
日志类型 |
作用 |
生命周期 |
|
Redo Log 重做日志 |
物理日志 (InnoDB引擎) |
确保事务的持久性(Durability),崩溃后恢复未刷盘的脏页 |
事务提交后写入,循环覆盖,刷脏清除 |
|
Undo Log 回滚日志 |
逻辑日志 (InnoDB引擎) |
实现事务回滚和多版本并发控制(MVCC),记录数据修改前的旧值 |
事务结束后根据隔离级别,决定保留时间 |
|
Bin Log 二进制日志 |
逻辑日志 (Mysql Server) |
主从复制(Replication)和数据恢复,记录所有修改数据的 SQL 或行变更事件。 |
事务提交后写入,可配置保留策略 |
|
Relay Log 中继日志 |
逻辑日志 (Mysql Server) |
从库复制时使用,暂存主库的binlog事件,供SQL线程重放 |
主从同步时写入,可配置保留策略 |
|
Slow Query Log 慢查询日志 |
逻辑日志 (Mysql Server) |
slow_query_log开启,记录执行时间超过long_query_time的查询,识别低效查询 |
持续写入,需手动清理或配置自动轮转 |
|
Error Log 错误日志 |
逻辑日志 (Mysql Server) |
记录MySQL服务启动、运行、关闭过程中的错误、警告和关键事件 |
长期保留,需手动清理或配置自动轮转 |
PS: 为什么有了Bin Log, 还需要记一份Redo Log?崩溃恢复时可以使用Bin Log吗?
- 使用其他类型插件引擎发生崩溃时,可以使用Bin Log辅助进行数据恢复。但难以确认各事务提交状态,需要人工介入确定要恢复的Bin Log数据游标位置,手动进行恢复;
- Redo Log是专门针对事务持久性的日志,发生崩溃时可实现自动化的数据恢复;并且为物理日志,可直接应用到数据页,恢复效率高且具备幂等性。
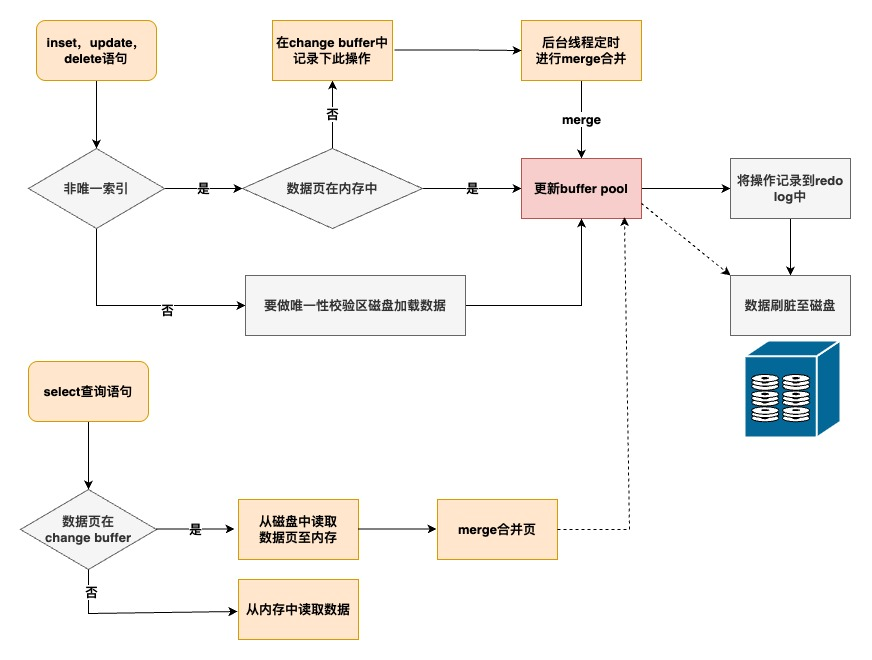
3.4 Change Buffer
当对数据进行写操作时,如果数据页不在内存buffer pool中,唯一索引数据需从磁盘中获取数据页加载到内存中,判断唯一性后再进行操作;而非唯一索引可以只在change buffer中做修改,节省随机IO读磁盘的消耗,适用于写多读少操作。虽然提升了写性能,但需要额外的merge机制来确保数据一致性
- 后台线程定时去merge合并 change buffer和数据页
- 查询时若数据存在于change buffer,则需要合并change buffer和数据页
3.5 AHI自适应哈希索引
自适应Hash索引AHI:根据数据的使用情况,为热点页建立自适应hash索引。建立在B+树索引上的索引,key=索引条件,value=叶子结点页指针。对于没有hash索引的页,只能回退到从root遍历B+索引树,找到链路上每一层的页号指针,根据页号不断深入查询直至叶子结点数据。
- 只适用于等值查询
- 只为buffer pool中的缓存页建立索引
- 不可主动创建
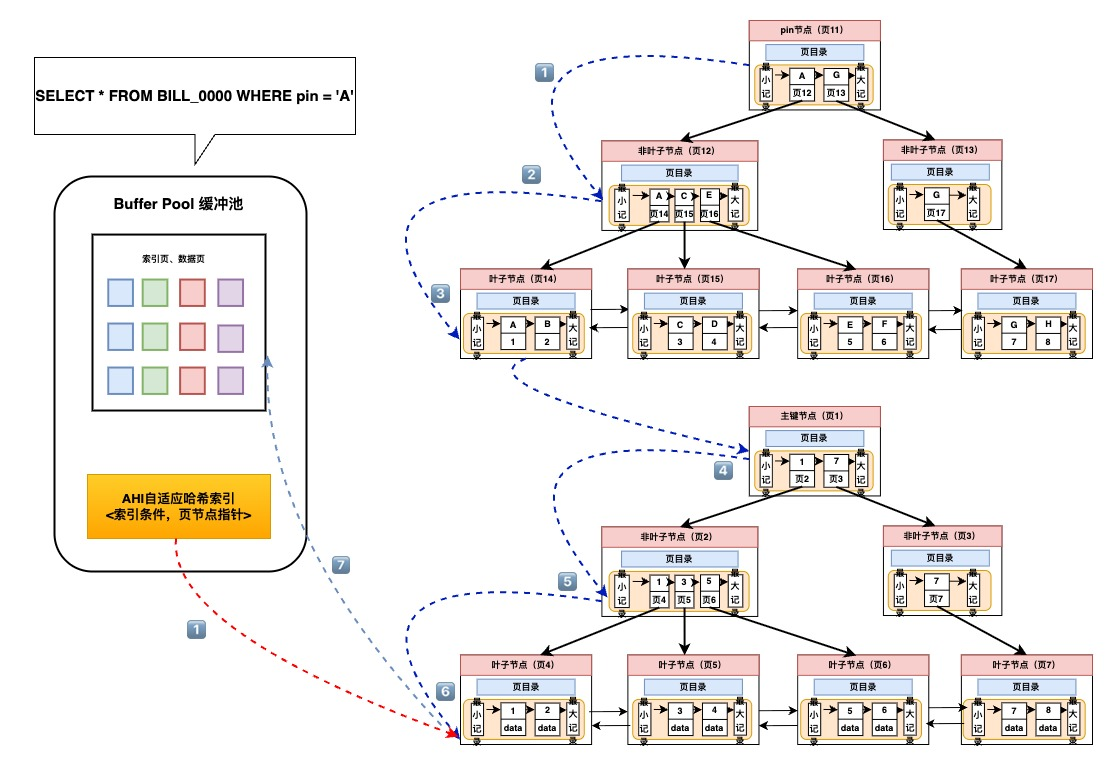
3.6 数据字段与锁信息
数据字典:记录表定义、列定义、索引定义、视图、表关系等元数据。
锁信息:记录锁了哪个事务、哪个索引,对应的表信息、页号、行号等。锁的数据结构:
|
锁共有的基本信息 |
不同类型锁的特有信息 |
|
上锁事物的信息,TRX_ID、事物状态 被锁的索引信息,锁作用的索引 锁的类型与模式信息 lock_mode: 共享锁(读锁)、独占锁(写锁) lock_type: 表锁、行锁 |
被锁表的信息(表锁) 表空间+页号(行锁) 被锁行行号(行锁) |
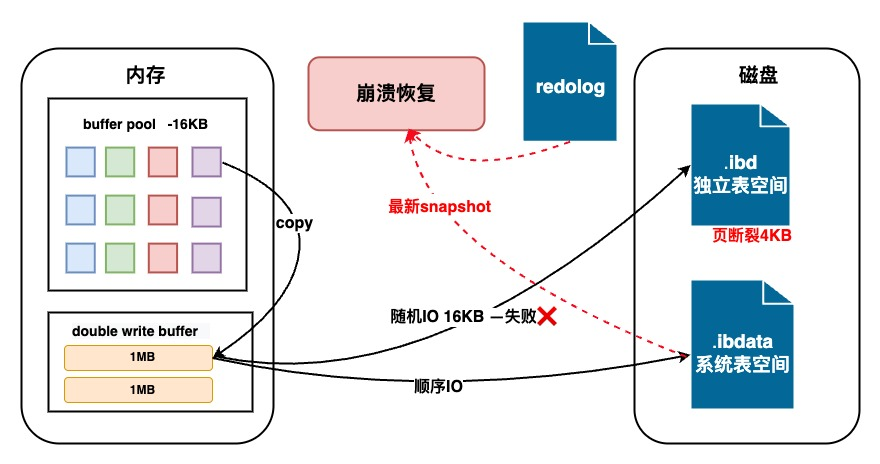
4、DoubleWrite双写
DoubleWrite双写护航、数据无损、崩溃恢复
- 双写缓冲区:
DoubleWrite由两部分组成,一部分是内存中的DoubleWrite Buffer,大小为2MB;另一部分是物理磁盘上共享表空间中连续的128个页,大小通用是2MB。脏页刷新时先写DoubleWrite Buffer,再顺序IO写共享表空间,最后再随机IO写数据文件磁盘。 - 双写原因:Mysql数据库IO的最小单位是
16K,文件系统IO的最小单位是4K,可能存在数据写了页的一部分就宕机中断的情况,页中一部分是旧的一部分是新的,即发生了页断裂。如果发生了页断裂,则从DoubleWrite写入的共享文件中找到最近的一次完整副本,搭配Redo Log重做日志,来恢复数据。
三、MySQL架构总结
SQL使用建议
|
减少数据库磁盘io/网络io |
· 查询语句只select必要列,使优化器可以正确判断合适的索引,减少回表次数与扫描量,降低与客户端的传输带宽消耗 · 尽量不要在数据库层面用复杂函数,将函数实现在客户端/应用方,降低数据库CPU消耗和计算负载 |
|
降低与数据库交互冗余消耗 |
· 考虑使用小批量DML操作,避免循环单次执行DML操作,批量操作只需做一次SQL解析、执行计划 · 优化事务使用,不合理的事务如:事务中调用RPC(超时)、超长事务,导致数据库连接长久无法释放,应用无法获取连接 |
|
提升数据库内存资源利用率 |
· 注意SQL字段索引失效全表扫描,会大量使用buffer pool,增加undo log、redo log存储成本等,并引发频繁刷脏 · 优化SQL使用,如:善用explain分析并优化索引、子查询或游标方式优化limit深度分页、使用join代替子查询优化创建临时表问题、join多表查询时小表驱动大表等 |
四、数据库原理与实践
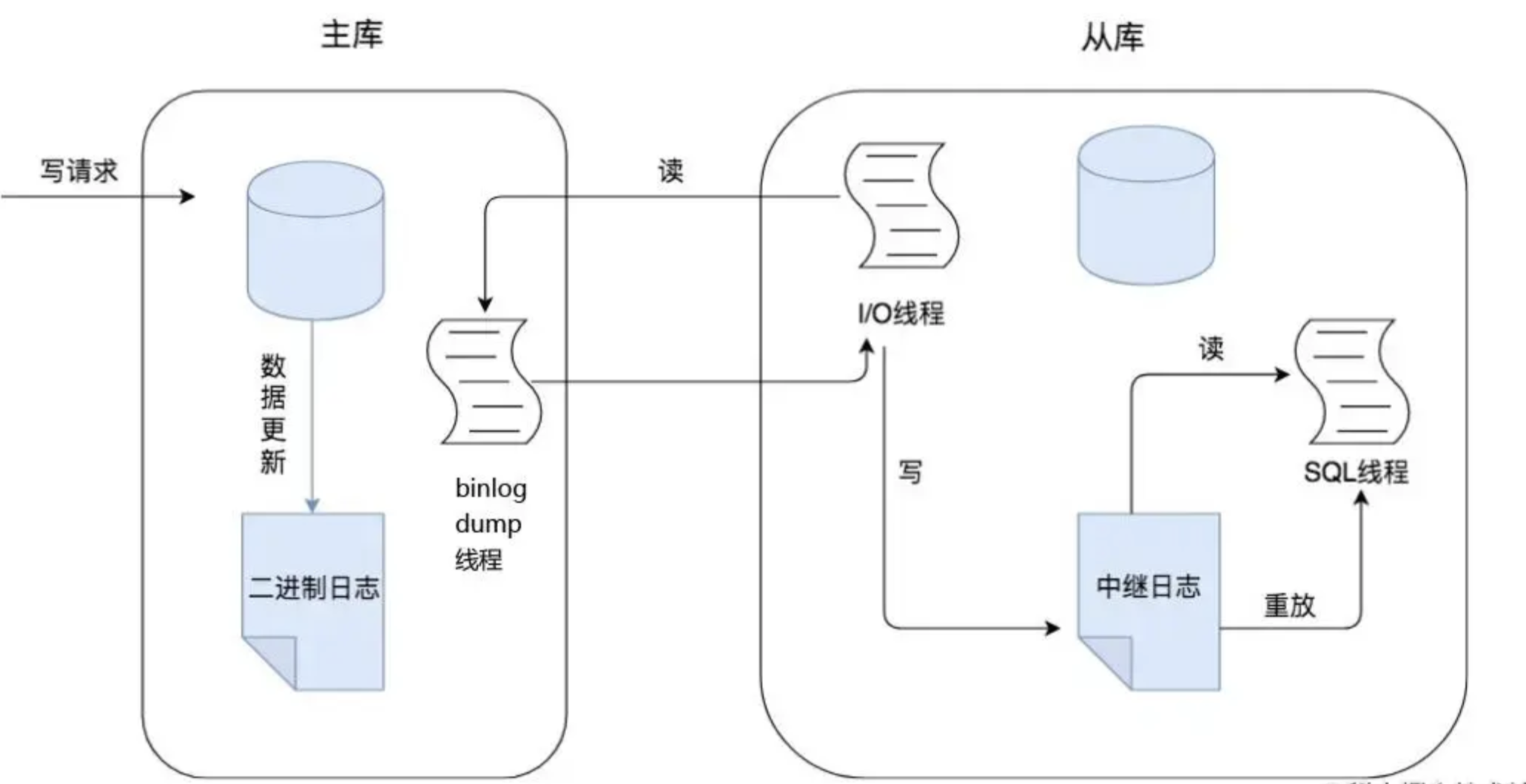
1、主从复制
主从复制是指一个主库(Master)将数据变更通过复制机制同步到一个或多个从库(Slave),实现数据的多副本冗余和读写分离。MySQL支持异步、半同步和全同步等多种复制方式。
1.1 主从复制优点
- 高可用性:通过将主数据库的数据复制到一个或多个从数据库,可以在主数据库故障时快速切换到从数据库,以实现系统的高可用性和容错能力,从而保证系统的持续可用性。
- 提高整体性能和吞吐量:通过将读请求分散到多个从服务器上进行处理,从而减轻了主服务器的负载压力,提高数据库系统的整体性能和吞吐量。主服务器主要负责写操作,而从服务器主要负责读操作,从而分担了主服务器的压力。
- 数据备份和恢复:通过主从同步,可以将主服务器上的数据异步复制到从服务器上,从而实现数据备份和灾难恢复的需求。在应对意外数据丢失、灾难恢复或误操作时,可以使用从服务器作为数据的备份源来进行数据恢复。
1.2 主从复制方案
- 异步复制
主库在执行写操作后,会将数据更新记录到bin log中,但不会等待从库的响应。从库通过I/O线程异步读取主库的binlog并写入中继日志,再由SQL线程重放这些日志以同步数据。
减少了主库的性能压力,但可能导致从库数据短暂滞后于主库。
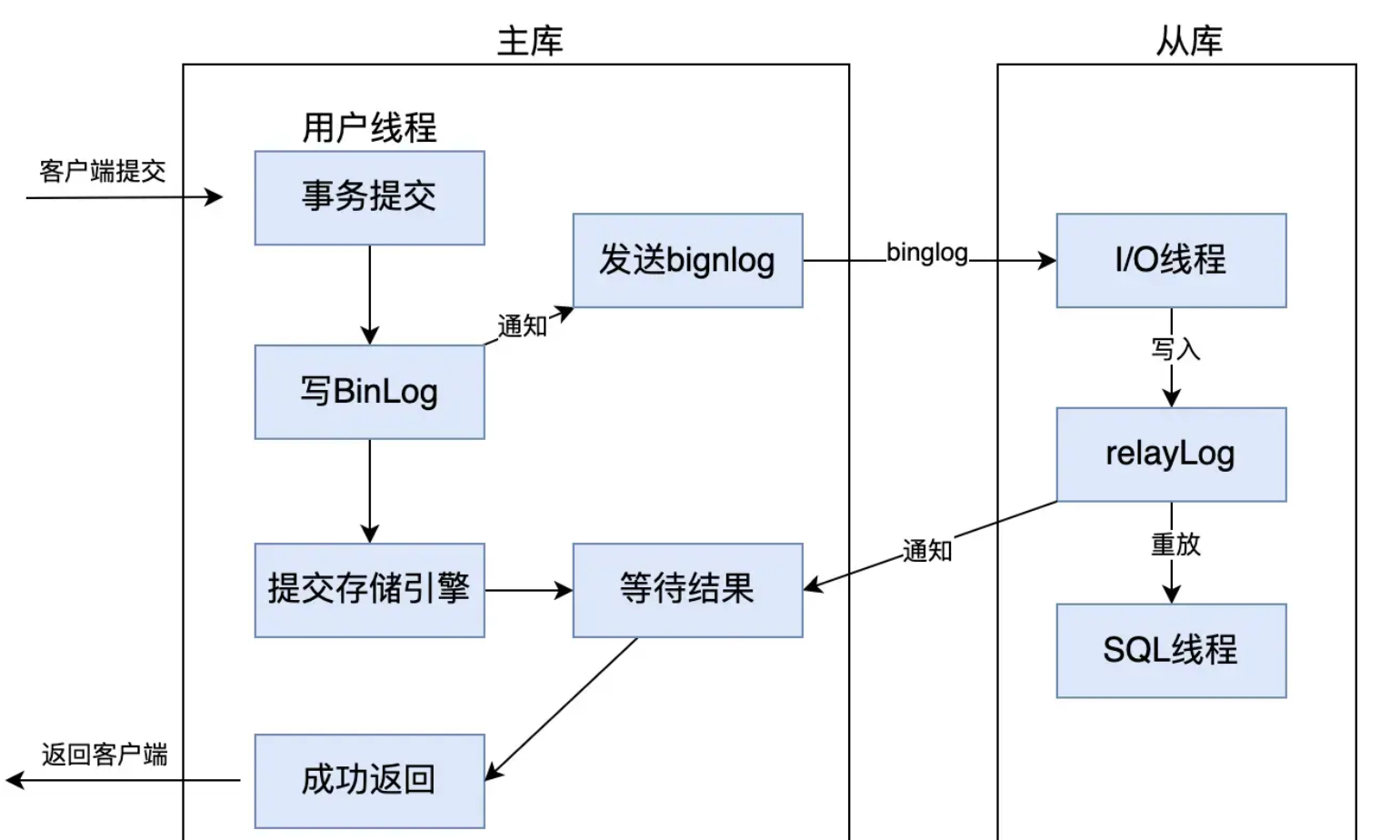
- 半同步复制
- 半同步复制(
after_commit)
介于异步复制和全同步复制之间的数据库主从复制模式。当主库提交事务时,会先将事务写入bin log,然后等待至少一个从库接收并写入relay log后,才向客户端返回成功响应。
比异步复制更可靠,确保数据至少有一个副本,但性能略低于异步复制,因为主库需要等待从库的确认。如果从库未及时响应,主库会降级为异步复制以避免阻塞。
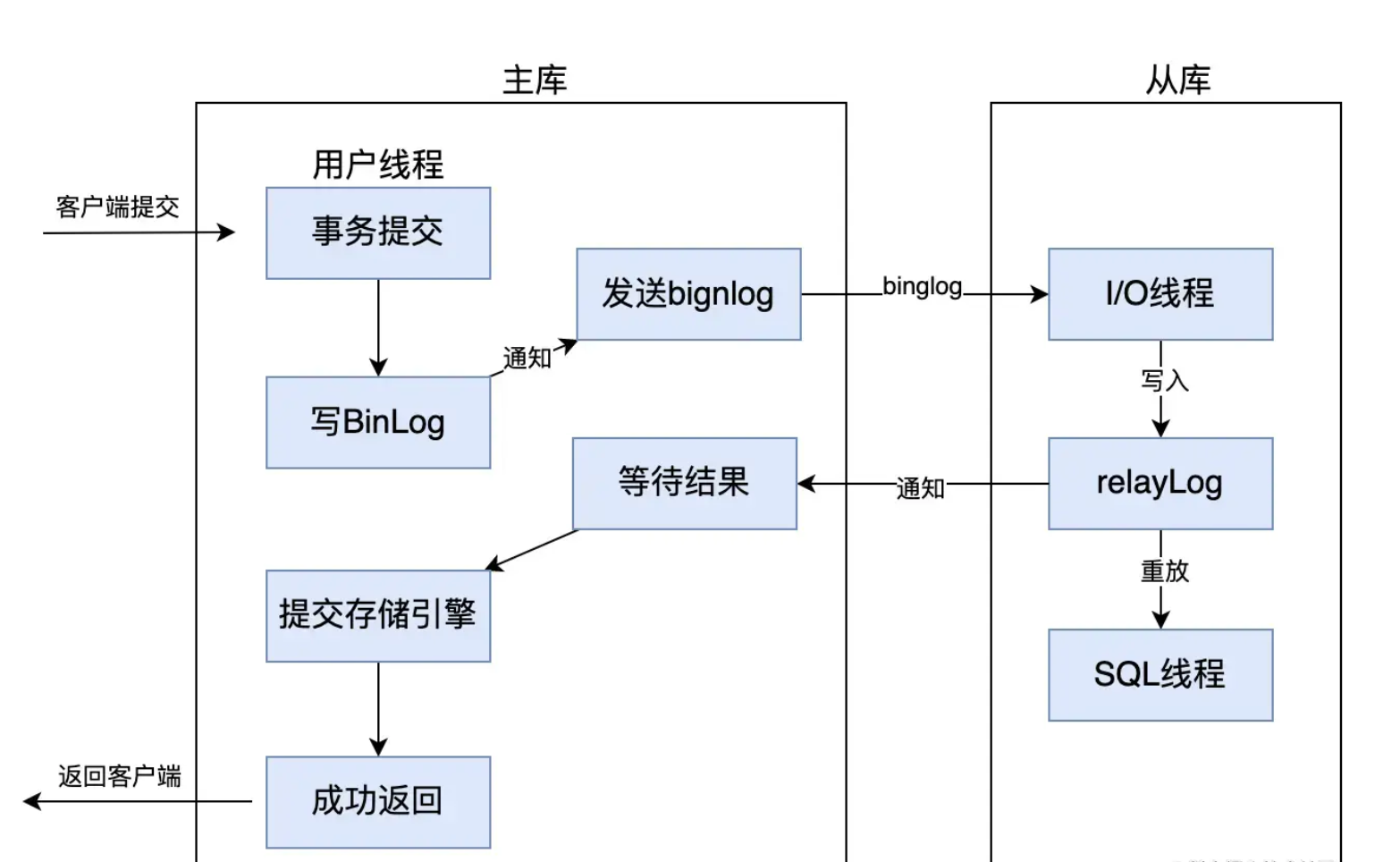
- 增强半同步复制(
after_sync)
在事务提交时,主库先等待至少一个从库接收并确认bin log,之后才提交存储引擎并返回成功响应给客户端。
比半同步复制更安全,因为即使主库崩溃,从库也一定收到了事务日志,避免了数据丢失风险。但它的性能可能略低于半同步,因为主库需等待从库确认后才能完成提交。
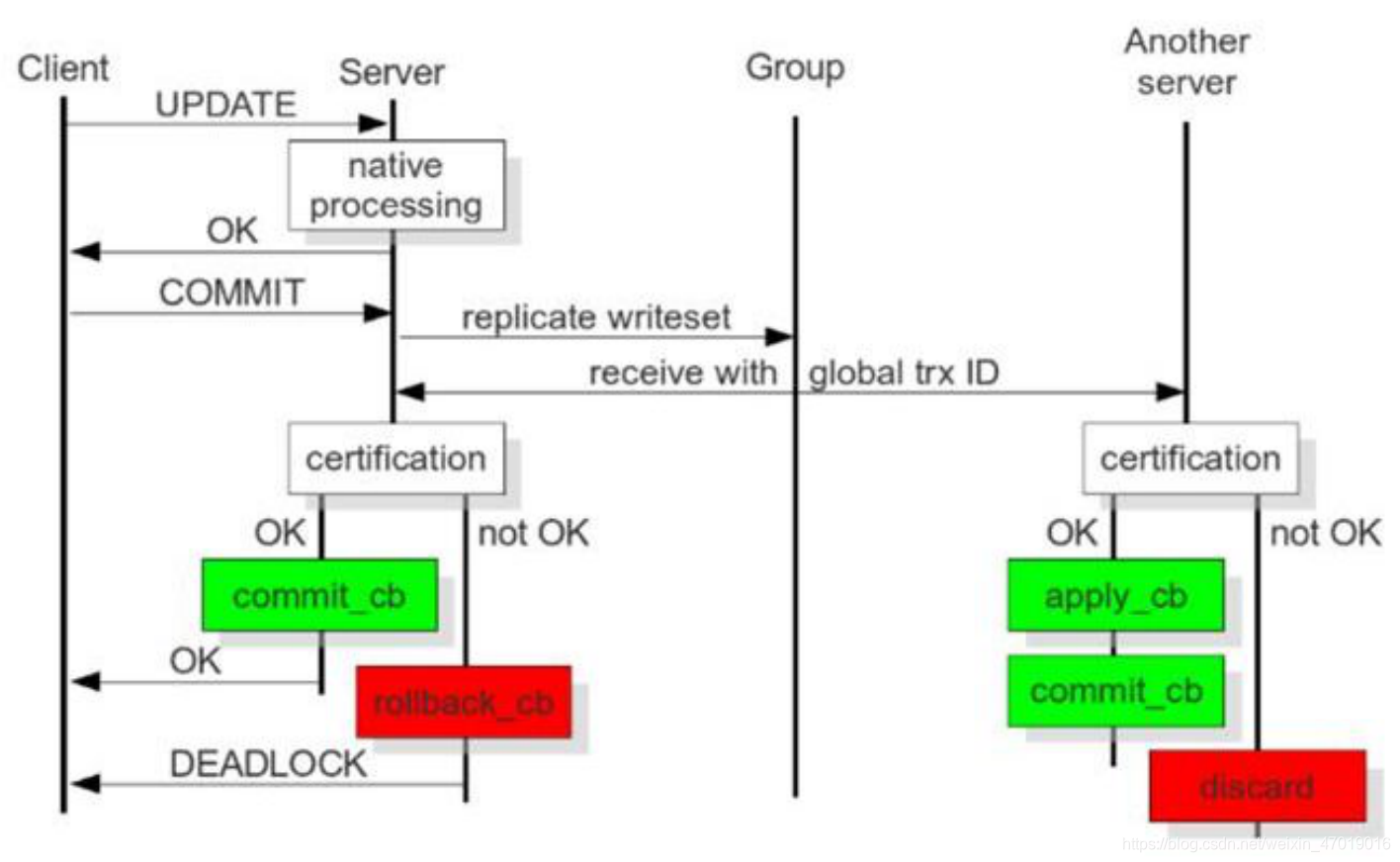
- 全同步复制(PXC、Group Replication)
强一致性的多主复制方案。当客户端发起更新请求时,事务会在当前节点处理,随后将写集(writeset)广播到整个集群。每个节点通过全局事务ID和认证机制(certification)检查冲突,只有多数节点验证通过后事务才会提交,否则回滚。
确保所有节点数据严格一致,适合高一致性要求的场景,但会因跨节点协调带来较高的延迟和性能开销。
- 总结对比
|
复制类型 |
一致性 |
性能 |
数据丢失风险 |
适用场景 |
|
异步复制 |
弱一致性 |
高 |
有 |
读多写少,容忍延迟 |
|
半同步复制 |
较强一致性 |
较高 |
低 |
重要数据场景 |
|
全同步复制 |
强一致性 |
一般 |
极低 |
金融、电商等强一致性要求场景 |


















 2552
2552

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









