






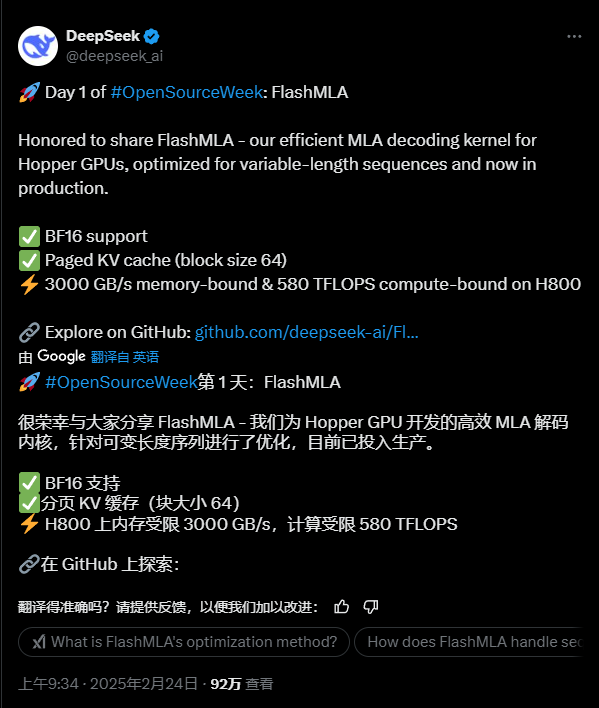
当所有人还在猜测DeepSeek的"开源五连发"会放出什么大招时,这个被称为"中国版OpenAI"的团队,用一份名为FlashMLA的硬核项目,直接把AI圈炸成了烟花大会!
GitHub链接都来不及复制,6.9k星已就位!
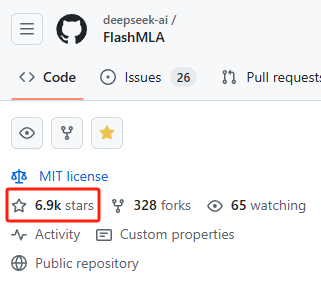
一大早开源的FlashMLA项目,像极了一场程序员圈的"派对"——12小时过去了,GitHub星标直冲6900+,评论区清一色的"Respect"刷屏。这阵仗不禁让人想起当年FlashAttention横空出世时,把Transformer模型塞进显卡的盛况。
但这次,DeepSeek玩得更野!
💡 一句话看懂FlashMLA:
这就是给H800/H100这些万元级显卡准备的"涡轮增压套件",专治大模型推理时"吃着火锅唱着歌,突然卡成PPT"的糟心体验。
实测数据更是暴力美学:
内存带宽飙到3000GB/s(相当于每秒搬空30个256GB的iPhone15)
算力直逼580TFLOPS(足够同时处理58万张高清图片)
长上下文推理效率提升3倍起步(以后让AI写《三体》续集都不用怕卡文)
🤯 更离谱的是,这波操作堪称"显卡解剖指南":
DeepSeek的工程师们直接把Hopper架构的GPU大卸八块,从芯片级重构了多头注意力机制。就像给赛车引擎做全车轻量化,把每个晶体管都安排得明明白白。

技术宅们看完代码直呼内行:
"这不就是给矩阵乘法做花式体操吗?"
"原来张量核心还能这么玩!"
"建议改名叫FlashMLArcade(街机模式)"
🎮 开箱即用才是真·良心:
环境要求干净利落:Hopper显卡+CUDA12.3+PyTorch2.0
接口设计比宜家说明书还简单
官方自曝师承FlashAttention和CUTLASS(这波是站在巨人肩膀上放二踢脚)
行业老炮都坐不住了:
"FlashAttention3才把H100利用率干到75%,DeepSeek转头就秀出580TFLOPs"
"现在做AI没点汇编级优化都不好意思开源"
"建议老黄下次发布会带DeepSeek工程师站台"
🚀 而这仅仅是开源马拉松的第一棒!
想想后面还有四天神秘项目待解锁,网友已经开始玩梗:
"DeepSeek宇宙"正式开启
"建议开源团队直接入住显卡厂商"
"现在转行还来得及当AI炼丹师吗"
当所有人都在讨论大模型参数竞赛时,DeepSeek用这个开源项目证明:在AI的星辰大海里,极致的工程优化才是真正的星际引擎。正如开发者文档里那句凡尔赛的注释:"本项目纯属工程实践"——好一个凡尔赛的纯属!
此刻,GitHub星标数仍在疯狂跳动,而吃瓜群众只想问:
明天DeepSeek要开的,到底是技术发布会,还是显卡性能拍卖会?



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









