




 本研究提出了一种基于BoTNet-Transformer改进的YOLOv7水果识别系统,旨在解决传统YOLO在水果识别中的局限性。BoTNet-Transformer模型利用Transformer结构增强全局特征捕获,处理小尺寸目标,并提高模型的泛化能力,以提升水果识别的准确性、召回率和鲁棒性。系统整合了BackBone、Neck、Head等组件,适用于智能农业和食品安全领域。
本研究提出了一种基于BoTNet-Transformer改进的YOLOv7水果识别系统,旨在解决传统YOLO在水果识别中的局限性。BoTNet-Transformer模型利用Transformer结构增强全局特征捕获,处理小尺寸目标,并提高模型的泛化能力,以提升水果识别的准确性、召回率和鲁棒性。系统整合了BackBone、Neck、Head等组件,适用于智能农业和食品安全领域。
1.研究背景与意义
项目参考AAAI Association for the Advancement of Artificial Intelligence
研究背景与意义
随着人工智能技术的快速发展,计算机视觉领域的研究也取得了巨大的进展。目标检测是计算机视觉中的一个重要任务,它的应用范围广泛,包括智能交通、安防监控、无人驾驶等领域。而在目标检测任务中,水果识别是一个具有挑战性的问题,因为水果的形状、颜色和纹理等特征差异较大,同时水果在不同的环境下也会有不同的光照和角度变化,这给水果识别带来了一定的困难。
目前,基于深度学习的目标检测方法已经取得了显著的成果。其中,YOLO(You Only Look Once)是一种快速而准确的目标检测算法,它通过将目标检测任务转化为一个回归问题,实现了实时的目标检测。然而,传统的YOLO算法在水果识别任务中存在一些问题,如对小尺寸目标的检测效果较差,对于水果的形状和纹理特征的学习能力有限等。
为了解决这些问题,本研究提出了一种基于BoTNet-Transformer的改进YOLOv7的水果识别系统。BoTNet-Transformer是一种新兴的深度学习模型,它结合了Bottleneck Transformer和YOLOv7的优点,能够更好地处理水果识别任务中的挑战。
首先,BoTNet-Transformer模型具有较强的特征提取能力。传统的YOLO算法主要使用卷积神经网络进行特征提取,但卷积神经网络在处理大尺寸目标和复杂纹理时存在一定的局限性。而BoTNet-Transformer模型采用了Transformer结构,能够更好地捕捉水果的全局特征和上下文信息,从而提高水果识别的准确性。
其次,BoTNet-Transformer模型能够有效地处理小尺寸目标。在水果识别任务中,一些水果可能具有较小的尺寸,传统的YOLO算法往往难以准确地检测这些小尺寸目标。而BoTNet-Transformer模型通过引入Bottleneck Transformer结构,能够更好地学习小尺寸目标的特征,提高水果识别的召回率。
此外,BoTNet-Transformer模型还具有较强的泛化能力。水果在不同的环境下可能会有不同的光照和角度变化,这给水果识别带来了一定的挑战。传统的YOLO算法往往对于光照和角度变化较为敏感,容易导致误检和漏检。而BoTNet-Transformer模型通过引入Transformer结构,能够更好地学习水果的上下文信息,提高水果识别的鲁棒性。
综上所述,基于BoTNet-Transformer的改进YOLOv7的水果识别系统具有重要的研究意义和应用价值。通过引入BoTNet-Transformer模型,可以提高水果识别的准确性、召回率和鲁棒性,进一步推动水果识别技术的发展,为智能农业、食品安全等领域提供有力的支持。
2.图片演示
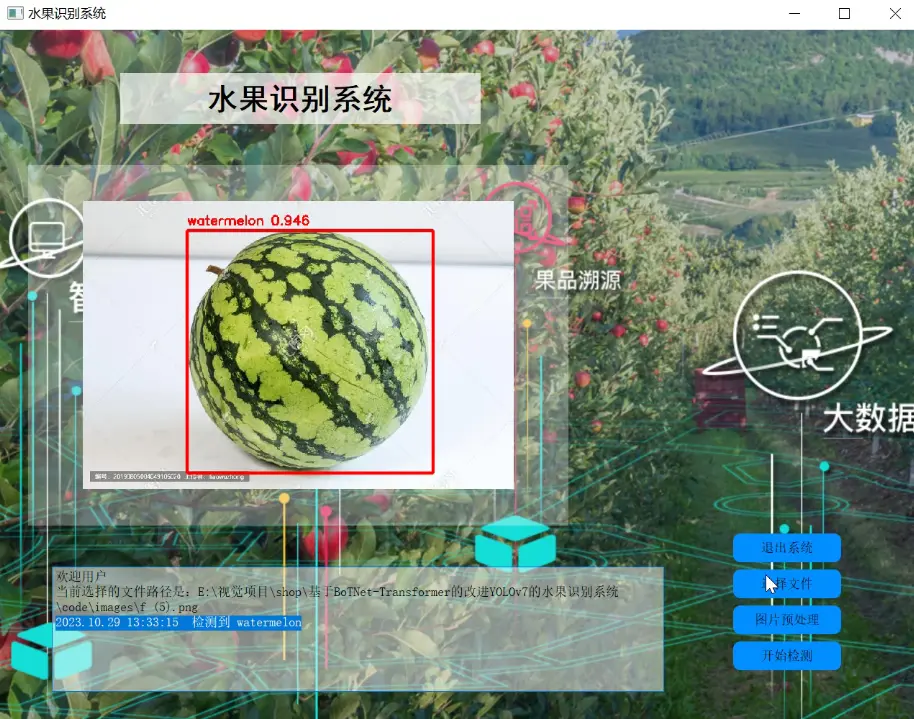
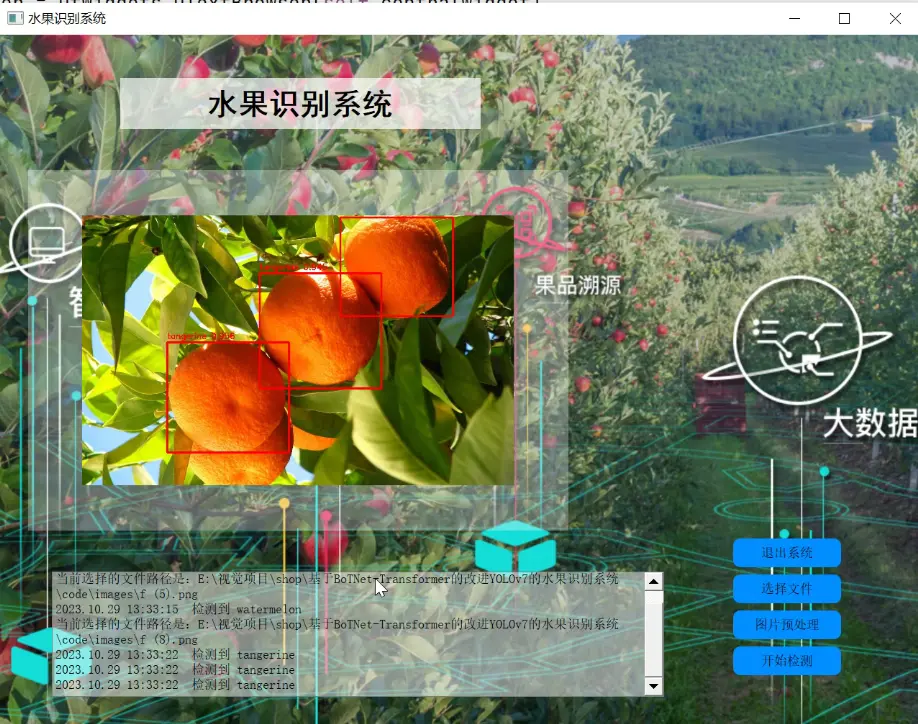

3.视频演示
基于BoTNet-Transformer的改进YOLOv7的水果识别系统_哔哩哔哩_bilibili
4.检测流程
YOLOv7 网络主要包含了 Input(输入)、Backbone(骨干网络)、Neck(颈部)、Head(头部)这四个部分。首先,图片经过输入部分数据增强等一系列操作进行预处理后,被送入主干网,主干网部分对处理后的图片提取特征;随后,提取到的特征经过 Neck 模块特征融合处理得到大、中、小三种尺寸的特征;最终,融合后的特征被送入检测头,经过检测之后输出得到结果。
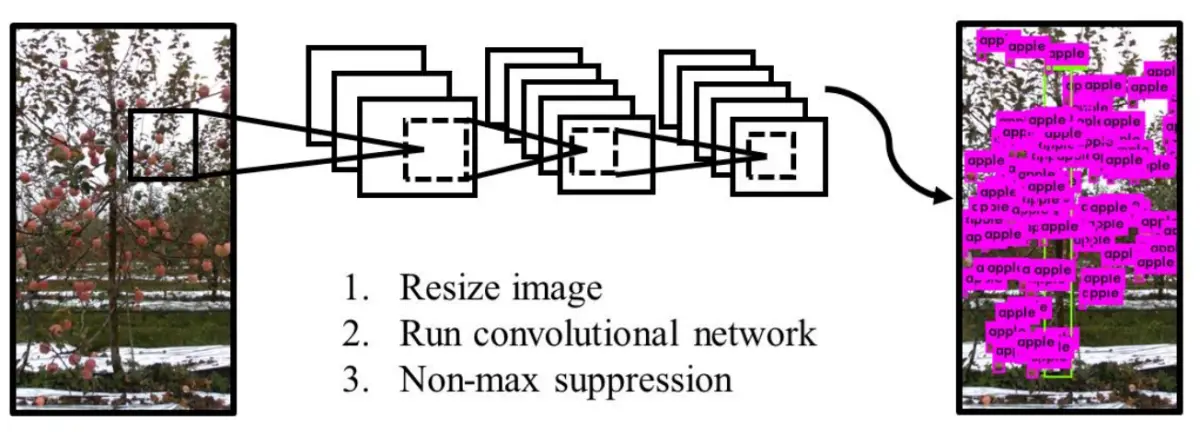
5.核心代码讲解
5.1 common.py
class MHSA(nn.Module):
def __init__(self, n_dims, width=14, height=14, heads=4, pos_emb=False):
super(MHSA, self).__init__()
self.heads = heads
self.query = nn.Conv2d(n_dims, n_dims, kernel_size=1)
self.key = nn.Conv2d(n_dims, n_dims, kernel_size=1)
self.value = nn.Conv2d(n_dims, n_dims, kernel_size=1)
self.pos = pos_emb
if self.pos:
self.rel_h_weight = nn.Parameter(torch.randn([1, heads, (n_dims) // heads, 1, int(height)]),
requires_grad=True)
self.rel_w_weight = nn.Parameter(torch.randn([1, heads, (n_dims) // heads, int(width), 1]),
requires_grad=True)
self.softmax = nn.Softmax(dim=-1)
def forward(self, x):
n_batch, C, width, height = x.size()
q = self.query(x).view(n_batch, self.heads, C // self.heads, -1)
k = self.key(x).view(n_batch, self.heads, C // self.heads, -1)
v = self.value(x).view(n_batch, self.heads, C // self.heads, -1)
content_content = torch.matmul(q.permute(0, 1, 3, 2), k)
c1, c2, c3, c4 = content_content.size()
if self.pos:
content_position = (self.rel_h_weight + self.rel_w_weight).view(1, self.heads, C // self.heads, -1).permute(
0, 1, 3, 2)
content_position = torch.matmul(content_position, q)
content_position = content_position if (
content_content.shape == content_position.shape) else content_position[:, :, :c3, ]
assert (content_content.shape == content_position.shape)
energy = content_content + content_position
else:
energy = content_content
attention = self.softmax(energy)
out = torch.matmul(v, attention.permute(0, 1, 3, 2))
out = out.view(n_batch, C, width, height)
return out
class BottleneckTransformer(nn.Module):
def __init__(self, c1, c2, stride=1, heads=4, mhsa=True, resolution=None, expansion=1):
super(BottleneckTransformer, self).__init__()
c_ = int(c2 * expansion)
self.cv1 = Conv(c1, c_, 1, 1)
if not mhsa:
self.cv2 = Conv(c_, c2,  最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 4937
4937





 到【灌水乐园】发言
到【灌水乐园】发言







