






 本文探讨了Presto和Hive在大数据处理上的差异,包括Presto的快速查询能力、内存计算优势及常见问题,同时介绍了PrestoSQL优化策略,如避免单节点数据处理、减少数据扫描范围等。
本文探讨了Presto和Hive在大数据处理上的差异,包括Presto的快速查询能力、内存计算优势及常见问题,同时介绍了PrestoSQL优化策略,如避免单节点数据处理、减少数据扫描范围等。
目录
presto会比hive快,原因:
Hive sql 转换 Presto sql 经常遇到的一些问题,降低转换成本。
针对Presto sql的优化介绍,了解优化的基本原则以及常规的实践方式。
了解存储格式对即席查询的影响,最终推动存储格式的优化。
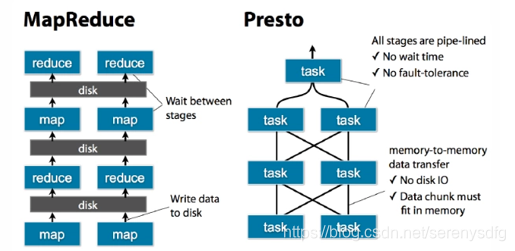
Presto是常驻任务,接受请求立即执行,全内存并行计算;hive需要用yarn做资源调度,接受查询需要先申请资源,启动进程,并且采用mapreduce计算模型,中间结果会经过磁盘。
由于 Presto 卓越的性能表现,使得 Presto 可以弥补 Hive 无法满足的实时计算空白,因此可以将 Presto 与 Hive 配合使用:对于海量数据的批处理和计算由 Hive 来完成;对于大量数据(单次计算扫描数据量级在 GB 到 TB)的计算由 Presto 完成。Presto 也适合实时计算任务。
特点
基于内存的分布式计算引擎(不是数据库) 多数据源接入(hive/mysql/sqlserver/kafka/redis…) 跨数据源join操作、标准sql支持,强类型检查
问题
不适合计算太大的数据量(目前1TB以上不建议)
容错处理较差,如果某个节点失败,整个查询也将失败
Udf支持不完善、不能完全兼容hive语法
Hive SQL -> Presto SQL 常见问题
官方文档
https://prestodb.io/docs/0.206/
字符串使用单引号
库/表/字段 和 关键词区别使用双引号
presto数组下标是由1开始,而不是由0开始
强类型约束
类型转换:type = ‘1’ 改为 cast(type as Integer) = 1
异常处理
try(ext[‘liveid’])
Json提取
Hive: get_json_object(detail_1,'$.detail1’)
Presto: json_extract_scalar (detail_1,'$.detail1’)
month函数使用
presto是强类型约束,month函数需要的类型是timestamp,而hive中则是直接使用string即可,所以在presto中需要先将string转换成timestamp类型,如下:month(date_parse(dt, '%Y-%m-%d’))
时间转换
Hive: unix_timestamp -> Presto: to_unixtime
Hive: from_unixtime -> Presto: from_unixtimePresto SQL优化
避免单节点处理数据
count(distinct)
group by 代替
approx_distinct(x)代替,大约有2.3%的误差
union
不需要排重则尽量使用union all
order by
使用列存储,尽量将排序字段减少、使用limit减少数据的扫描范围
分区获取、只查询需要的列,避免select *
利用索引减少数据扫描,如min-max index
查询sql常规优化
过滤条件必须加上分区字段
在group by 时,尽可能将基数大的字段放前面(数量多的)
如:group by dt, uid -> group by uid, dt
避免多个like语句
避免join条件涉及计算,使用子查询替换包含计算的条件
当前影响查询效率的主要问题
存在很多多次扫描同一张表的语句
数据分区粒度比较粗
Presto 查询覆盖率不足,目前覆盖率30%左右
很多查询都是从比较原始的表进行,比如ods_action_log_new,dwd_huya_event等
数据存储格式几乎都是text格式

















 1467
1467

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









