









用于解决海量日志数据的分析
hive是基于Hadoop的一个数据仓库工具,可以将结构化的数据文件映射为一张数据库表,并提供完整的sql查询功能,可以将sql语句转换为MapReduce任务进行运行。其优点是学习成本低,可以通过类SQL语句快速实现简单的MapReduce统计,不必开发专门的MapReduce应用,十分适合数据仓库的统计分析。
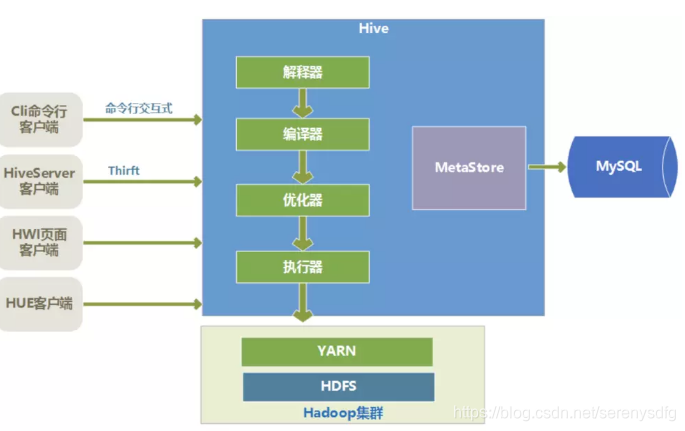
元数据是一般是存储在MySQL这种关系型数据库上的,Hive和MySQL之间通过MetaStore服务交互
具体扩展使用参考:https://www.jianshu.com/p/e9ec6e14fe52
Hive的几个特点
-
Hive最大的特点是通过类SQL来分析大数据,而避免了写MapReduce程序来分析数据,这样使得分析数据更容易。
-
数据是存储在HDFS上的,Hive本身并不提供数据的存储功能
-
Hive是将数据映射成数据库和一张张的表,库和表的元数据信息一般存在关系型数据库上(比如MySQL)。
-
数据存储方面:它能够存储很大的数据集,并且对数据完整性、格式要求并不严格。
-
数据处理方面:因为Hive语句最终会生成MapReduce任务去计算,所以不适用于实时计算的场景,它适用于离线分析。
HIVE UDF
在Hive中,用户可以自定义一些函数,用于扩展HiveQL的功能,而这类函数叫做UDF(用户自定义函数)。UDF分为两大类:UDAF(用户自定义聚合函数)和UDTF(用户自定义表生成函数)。
单的UDF实现——UDF和GenericUDF
Hive有两个不同的接口编写UDF程序。一个是基础的UDF接口,一个是复杂的GenericUDF接口。Hive要使用UDF,需要把Java文件编译、打包成jar文件,然后将jar文件加入到CLASSPATH中,最后使用CREATE FUNCTION语句定义这个Java类的函数
udf相关学习:https://blog.youkuaiyun.com/u010376788/article/details/50532166


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









