




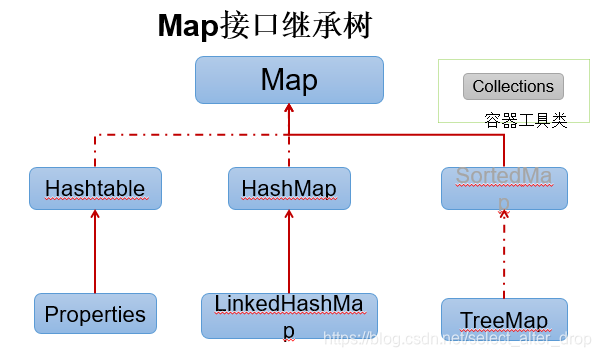
 本文深入探讨了Java中的Map接口,重点分析了HashMap、Hashtable和TreeMap的特性和使用。HashMap的存储结构包括数组+链表/红黑树,允许null键值。Hashtable是线程安全但效率较低,不允许null。TreeMap基于红黑树,元素需可比较。还介绍了Properties类在读写配置文件中的应用。
本文深入探讨了Java中的Map接口,重点分析了HashMap、Hashtable和TreeMap的特性和使用。HashMap的存储结构包括数组+链表/红黑树,允许null键值。Hashtable是线程安全但效率较低,不允许null。TreeMap基于红黑树,元素需可比较。还介绍了Properties类在读写配置文件中的应用。
文章目录
双列集合—Map
问题
1.Map 中的 Entry 接口是什么作用?
interface Entry<K,V>
- 1)HashMap/HashTable中:元素Node实现Map.Entry<K,V>接口)
static class Node<K,V> implements Map.Entry<K,V> {
final int hash;
final K key;
V value;
Node<K,V> next;
……
}
- 2)TreeMap中:元素Entry实现Map.Entry<K,V>接口
static final class Entry<K,V> implements Map.Entry<K,V> {
K key;
V value;
Entry<K,V> left;
Entry<K,V> right;
Entry<K,V> parent;
boolean color = BLACK;
……
}
- 3)LinkedHashMap中:元素 Entry 实现 继承自 HashMap.Node
static class Entry<K,V> extends HashMap.Node<K,V> {
Entry<K,V> before, after;
Entry(int hash, K key, V value, Node<K,V> next) {
super(hash, key, value, next);
}
}
2.Map接口中的 entrySet() 方法:???
Set<Map.Entry<K, V>> entrySet();
3.关于 null 值的存储:
1)ArrayList 能存储 null
源码:
public boolean add(E e) {
ensureCapacityInternal(size + 1); // Increments modCount!!
elementData[size++] = e;
return true;
}
此外输出该list对象时:
System.out.println(list);
//println() 会将 list 转为 String : String.valueOf(x)
String s = String.valueOf(x);
//String.valueOf(x):
return (obj == null) ? "null" : obj.toString();
2)HashMap 能存储 null key 和 null value (对应HashSet LinkedHashSet LinkedHashMap)
- 因为 null 有对应 hash 值 为 0;
HashMap源码:
public V put(K key, V value) {
return putVal(hash(key), key, value, false, true);
}
static final int hash(Object key) {
int h;
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}
3)HashTable 不能存储 null值
//put():
if (value == null) {
throw new NullPointerException();
}
4)TreeMap TreeSet 不能存储 null值:null 不能调用 compareTo()方法
if (key == null)
throw new NullPointerException();
1.概述
key=value
Map分类:
- HashMap/TreeMap/HashTable/Properties
1.Map 集合的特点
- key-value
- Map中的key值,相当于是一个Set集合 无序且不能重复
- Map中的value值,相当于一个Collection 可以重复,顺序是按照key值
方法
增
put(Object key,Object value); 新增
putAll(Map map); 批量新增
删
remove(Object key);根据key值移除数据
remove(Object key, Object value) 根据key=value移除数据
clear();清空
改
put(Object key,Object value); key值一致,则value值覆盖之前的value值
replace(2, "Oracle") 根据key值替换
map.replace(2, "Oracle", "SqlServer"); 根据key=value替换
查
size() 返回数据个数
isEmpty() 是否为空
containsKey(Object key) 是否包含指定key值
containsValue(Object value)是否包含指定value值
get(Object key); 根据key值获得value值
遍历方式
a.遍历key
keySet()方法:返回Map中所有的key值的Set[集合]
Set keys = map.keySet();//返回map中所有的key值
for (Object object : keys) {
System.out.println(object);
System.out.println(map.get(object));
}
b.遍历value
values()方法:返回Map中所有value的Collection[List:包含重复值]
public Collection<V> values()
Collection values = map.values();//获得map中所有的value值
for (Object object : values) {
System.out.println(object);
}
c.entrySet():获得map集合中key=value的值(Map.Entry 内部类)
- getKey()
- getValue()
Set entrySet = map.entrySet();//获得map集合中key=value的值
for (Object object : entrySet) {
//entrySet中的每一个对象的实际类型是什么?
Map.Entry entry=(Map.Entry)object;
System.out.println(entry.getKey());
System.out.println(entry.getValue());
System.out.println(object);
}
HashMap
JDK8及之后:数组 + 链表/红黑树
JDK7:数组 + 链表
1.源码分析:
以JDK8为例
步骤:
①创建HashMap对象时,table数组并没有初始化,仅仅只是将加载因子loadFactor初始化0.75
②当添加元素时,
如果是第一次添加元素时,table数组初始化容量为16,临界值threshold初始化12(16*0.75)
否则直接添加,先根据哈希值获取存放的索引,如果没有,直接添加。
如果有元素,需要解决冲突,然后添加。
③当每次添加元素时,先判断size>threshold,如果大于,则需要扩容
扩容倍数:2倍
2.hash方法的原理:
-
方法原型:return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
-
获取二次哈希值
-
然后通过运算得到存放的桶的索引: tab[i = (n - 1) & hash])
3.put方法的原理: ★
调用putVal(hash(key),key,value,true,true)
①先判断是否为第一次添加,
如果是第一次添加,调用resize方法,进行table初始化.然后进行下一步
容量为16,临界值为12
如果不是第一次添加,直接进行下一步
②需要获取待添加元素的插入点(存放的索引): tab[i = (n - 1) & hash])
然后判断该索引处是否有元素:
如果没有元素,则直接赋值
如果已经有元素,则需要根据以下情况进行判断:
情况1:判断二者的哈希值和地址|内容 是否相等,如果相等,则直接覆盖, 如果不相等,判断情况2
情况2:判断是否为树结构,然后根据树结构的特点进行冲突解决
情况3:判断是否为链表结构,然后根据链表结构的特点进行冲突解决
③判断++size>临界值threshold,如果满足,则需要重新调用resize方法,进行2倍扩容
newCap = oldCap << 1
扩容需要重新打乱之前的顺序,重新计算所有元素的hash值和存放的索引,然后赋值
4.如何将链表结构转换成树结构?
当链表的节点数>=8 && table的容量>=64 ,才会转换
核心代码:
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
treeifyBin(tab, hash);
if (tab == null || (n = tab.length) < MIN_TREEIFY_CAPACITY)
jdk7和jdk8源码的区别:
①整体结构:
jdk7:数组+链表
jdk8:数组+链表+红黑树
②table的类型不一样
jdk7:Entry[]
jdk8:Node[]
③创建对象时,对table的处理不一样
jdk7:table直接初始化容量为16
jdk8:table没有初始化,在第一次添加元素才进行初始化
使用:
将key的元素类型重写hashCode和equals,否则认为地址相等的两个key为重复元素
Hashtable
HashMap是JDK1.2版本出现,Hashtable是JDK1.0版本出现
TreeMap
底层结构:红黑树
特点:对添加到里面的元素进行自然排序(Comparable)或定制排序(Comparator)
-
HashMap允许存储null键和null值;
-
Hashtable不允许存储null键和null值;
-
HashMap是同步的 -->线程安全 -->效率低
-
Hashtable是不同步的 -->线程不安全 -->效率高
Properties类[IO流]
Properties类 继承自 Hashtable,Properties属于Map集合框架中的Hashtable的子类,所以具备Hashtable的特点
1.what
java.lang.Object
继承者 java.util.Dictionary<K,V>
继承者 java.util.Hashtable<Object,Object>
继承者 java.util.Properties
API:
Properties 类表示了一个持久的属性集。Properties 可保存在流中或从流中加载。属性列表中每个键及其对应值都是一个字符串。
说明:
- 1、存储键值对
- 2、键不能重复,值可以重复
- 3、不允许null键,null值
- 4、不支持泛型
2.为啥要学它?其作用?
Properties专门用于读写配置文件的
注:配置文件专门用于存储项目的配置信息
-
固定格式:键值对格式
-
默认编码格式:ISO8859-1
-
键和值数据类型:String
-
文件后缀:.propertier
key=value -->不能有空格;每对一行;
3.相关API:
- store(OutputStream/writer,String)
- setProperty(String key,String value)
- load(InputStream) ★
- getProperty(String key) ★
- getProperty(String key,String defaultValue)
4.使用方法:从程序 到 文件
1)创建Properties对象
Properties info = new Properties();
2)存储键值对信息到集合容器中:setProperty()
info.setProperty("username","周杰伦");
info.setProperty("password","123456");
3)将集合中的键值对写入到配置文件中:info.store()
FileWriter writer = new FileWriter("src\\user.properties");
info.store(writer,null); //第二个参数为备注信息
4)关闭流
writer.close();
5.从文件 到 程序
1)创建Properties对象
Properties info = new Properties();
2)加载:info.load()
info.load(new FileInputStream("src\\user.properties"));
3)根据键获取值:info.getProperty()
System.out.println(info.getProperty("username"));

















 745
745

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









